







采集商品评论对于企业和消费者都至关重要。它不仅帮助企业了解产品优势与不足,指导产品改进和市场策略调整,还能通过积极回应顾客反馈增强品牌忠诚度。对消费者而言,真实客观的评价是决策的重要参考,有助于避开潜在问题,选择最适合自己的产品。因此,有效收集并分析商品评论已成为提升用户体验和竞争力的关键环节。
下面介绍一个简单的方法,来采集淘宝评论。
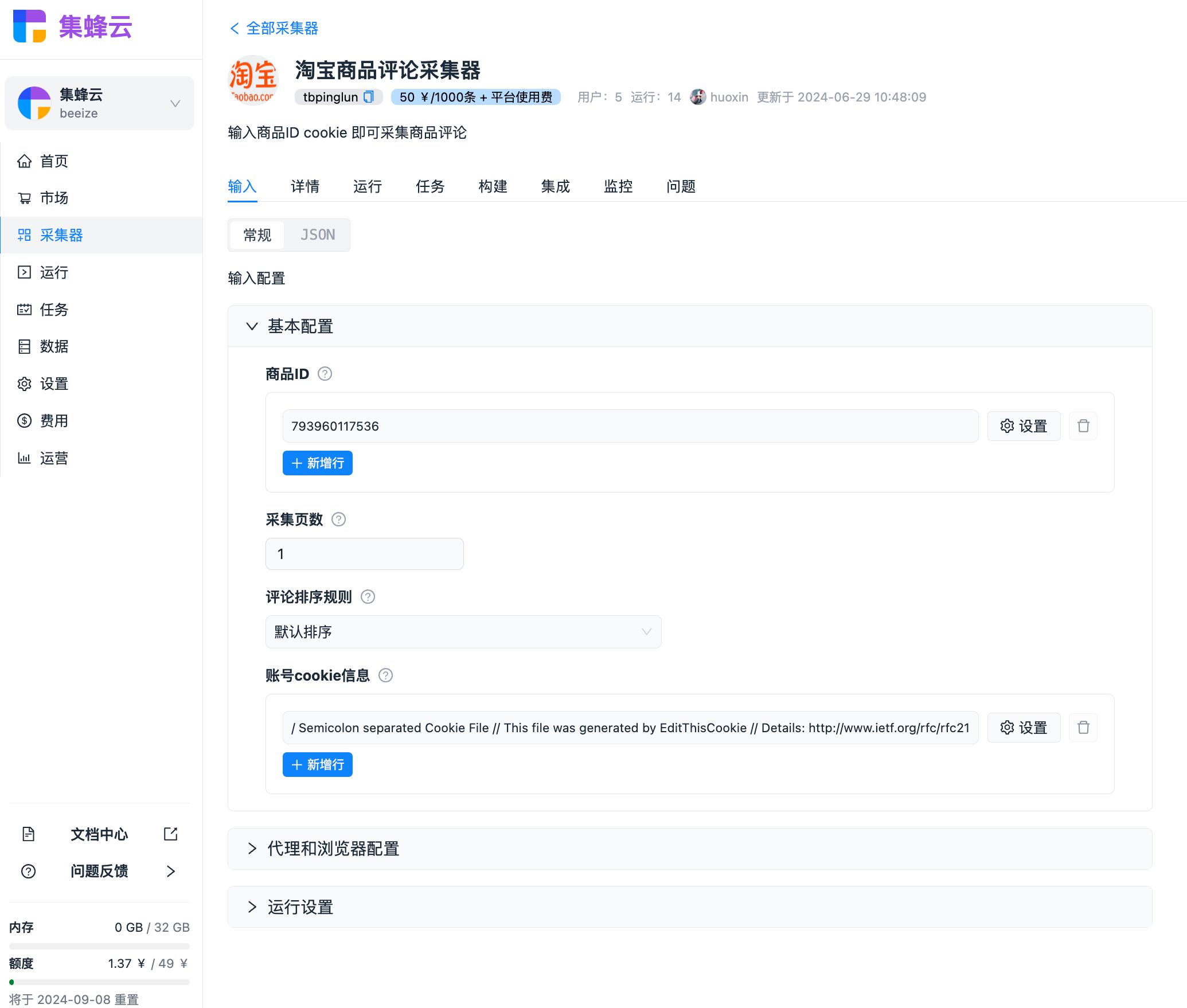
1、输入商品的 ID
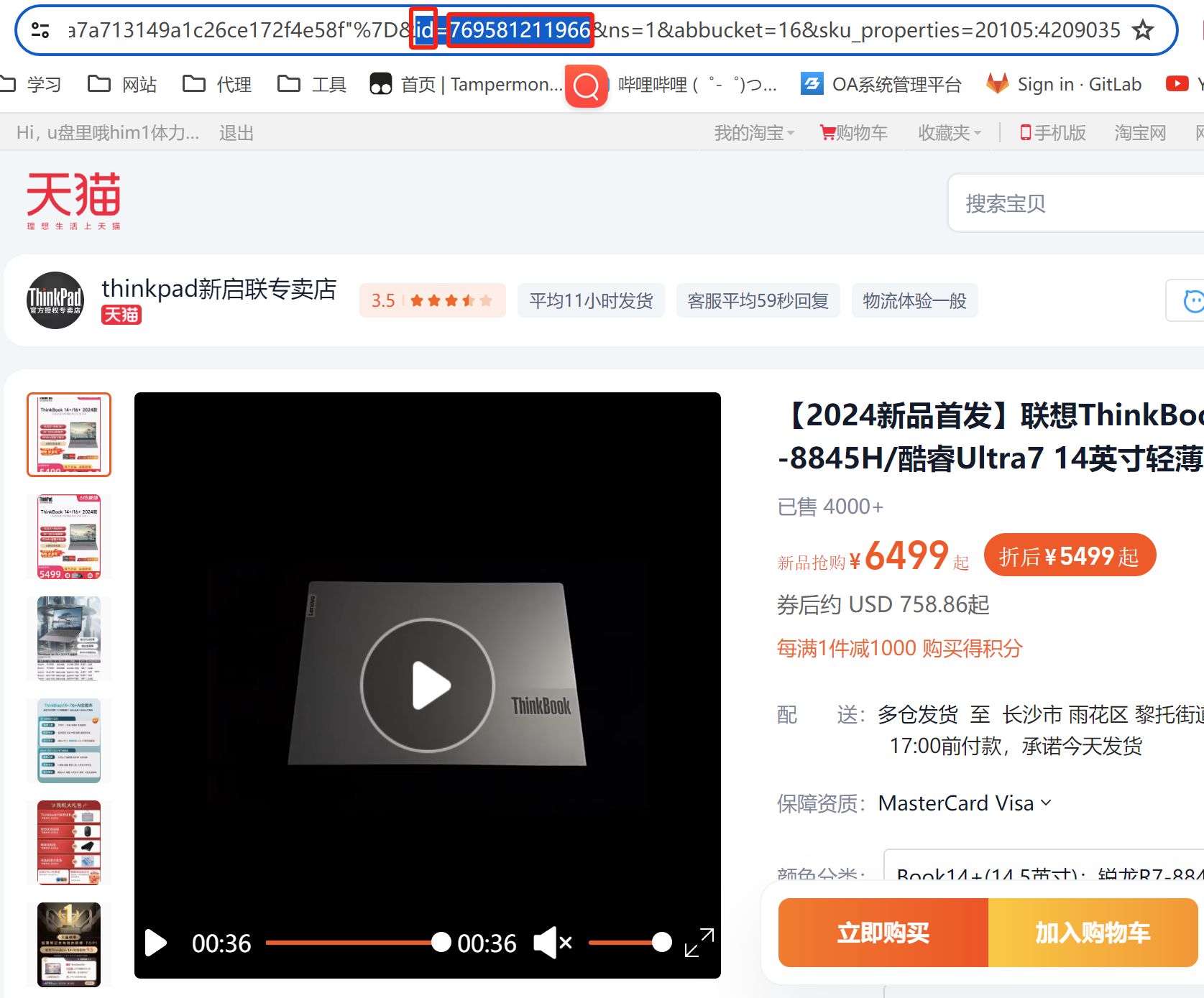
点击商品详情页,在链接中获取,如图所示:
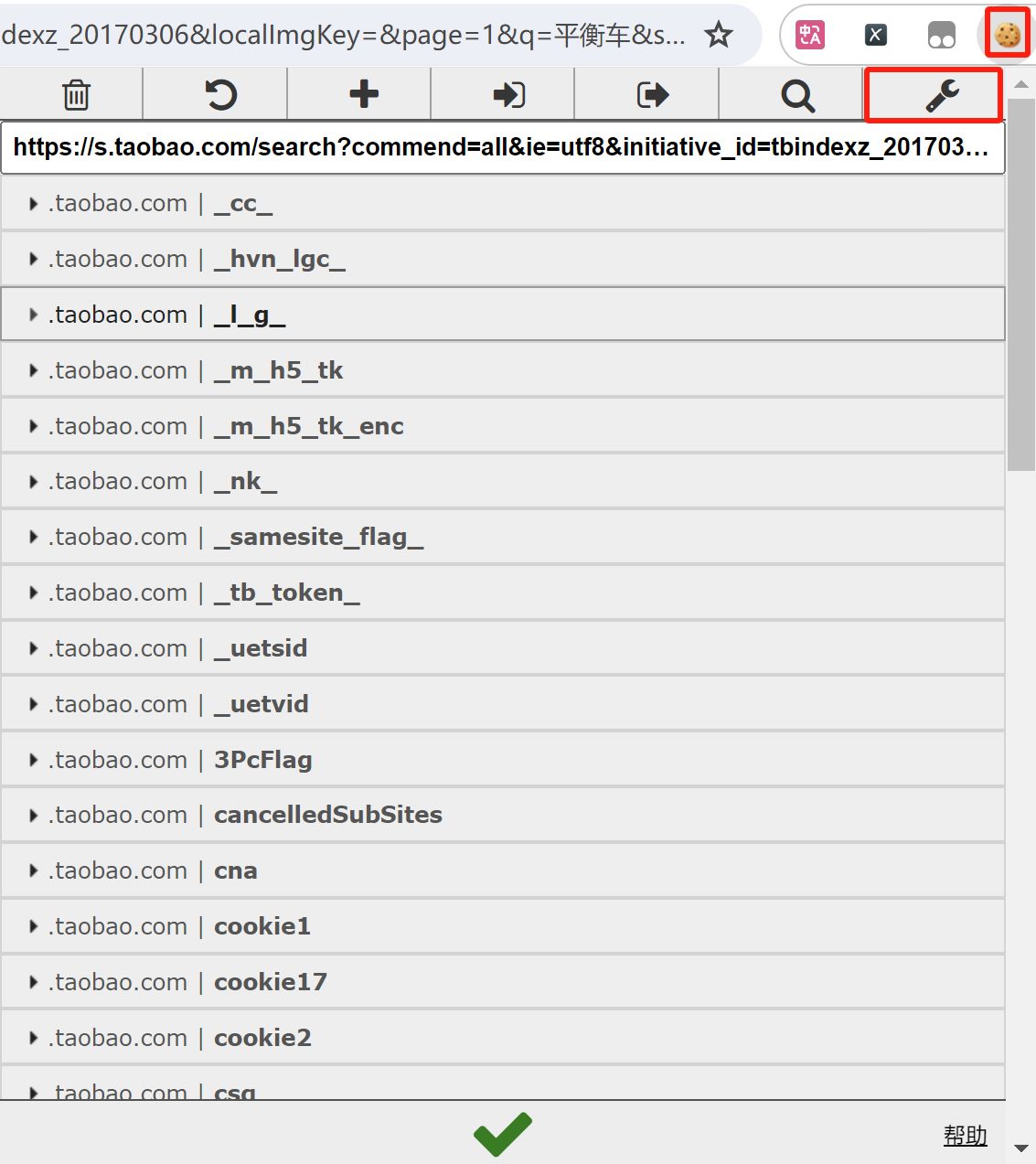
2、获取淘宝账号的 cookie
下载插件(安装方便简单,一次安装,永久使用) 链接:https://blog.csdn.net/m0_73689941/article/details/140006629
首先对EditThisCookie插件进行设置, 更改导出格式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









