






在这个数据驱动的时代,快速准确地获取网站信息对于企业决策和市场分析至关重要。本文将揭示三种高效的数据采集方法,帮助您轻松解锁网站数据的无限可能,助力业务洞察与增长。通过实战技巧与工具推荐,让您掌握数据收集的艺术。
正文
一、为什么要重视网站数据采集?
在数字化转型的浪潮中,网站数据如同深海中的宝藏,蕴藏着用户行为、市场趋势与竞争对手情报。实时监测与智能分析这些数据,能够为企业带来竞争优势,驱动产品迭代与市场策略的优化。
二、手动下载 vs. 自动化采集:选择的重要性
手动下载:虽然直接但效率低下,不适合大规模数据需求。
自动化采集:利用技术手段自动抓取,适用于大量、定期数据收集,提高效率与准确性。
三、三大高效数据采集方法揭秘
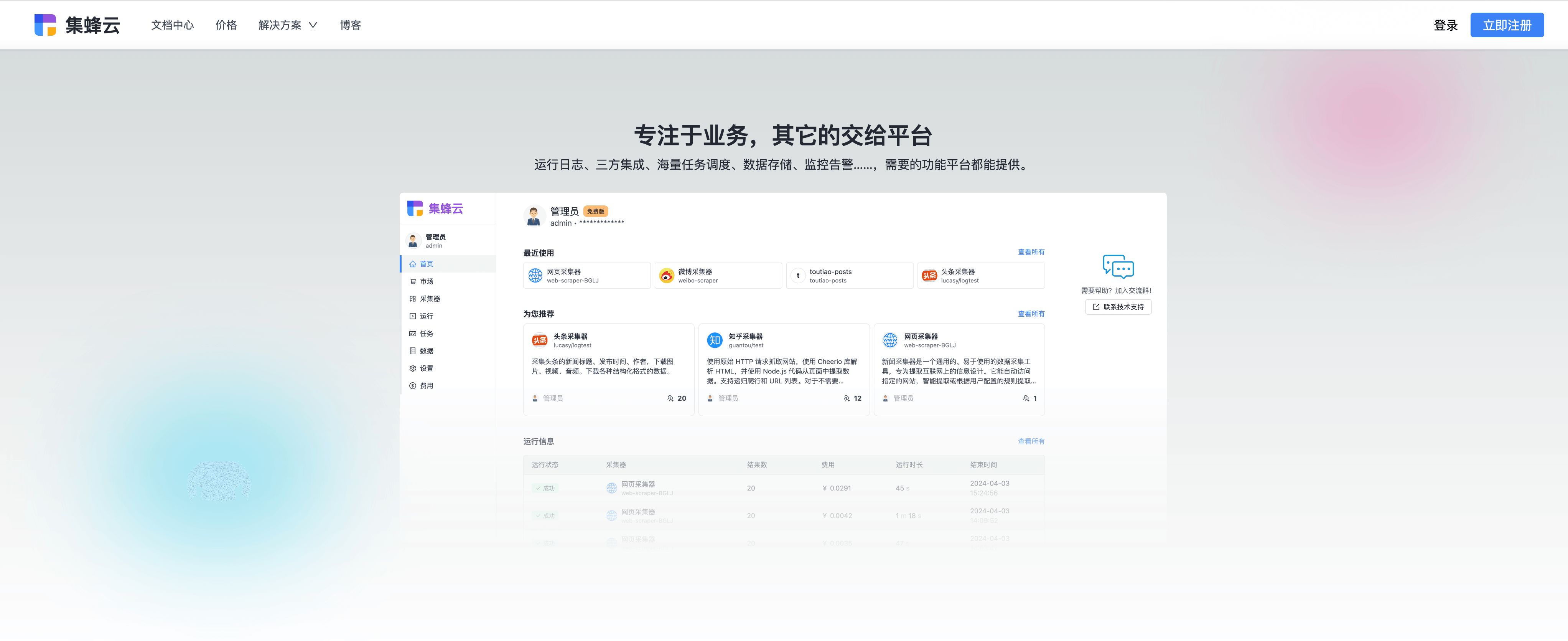
1. Web Scraping(网页爬虫)
技术要点:利用Python等编程语言,结合BeautifulSoup或Selenium等库编写脚本,模拟浏览器行为抓取数据。
优势:高度定制化,能针对特定需求灵活调整。
挑战:需要一定的编程基础,且需应对网站反爬策略。
2. API接口调用
概念:许多网站提供API供开发者获取数据,无需爬虫即可获得结构化信息。
优点:简单易用,数据格式统一,合规性高。
局限:并非所有网站都开放API,且可能受限于访问频率和数据量。
3. 云端数据采集平台
特点:如第三方云端采集平台,提供一站式数据抓取、存储与分析服务。
优势:无需编程基础,支持海量任务调度,集成监控告警等功能,确保数据采集的高效与稳定性。
应用场景:适合企业级用户,尤其是需要高频次、大规模数据采集的团队。
四、实战技巧与注意事项
遵守Robots协议,尊重网站数据权限。
处理反爬机制,如更换User-Agent、使用代理IP等。
数据清洗,确保采集到的数据质量,去除冗余与错误信息。
五、提升数据采集效率的外部资源
推荐阅读:“Web Scraping Techniques for Efficient Data Extraction”,深入了解高级抓取技巧。
六、常见问题解答
如何开始学习网页爬虫?
从Python基础开始,逐步学习requests、BeautifulSoup等库的使用。
遇到反爬怎么办?
考虑使用更复杂的请求头部伪装、代理IP池或更高级的浏览器模拟技术。
数据采集的法律边界在哪里?
严格遵守目标网站的使用条款,了解相关法律法规,如GDPR等。
数据采集频率怎么设置合理?
根据网站规定和实际需求调整,避免对目标网站造成过大负担。
如何存储和管理采集到的大数据?
可采用云数据库服务,如AWS S3、Google Cloud Storage等,便于扩展与管理。
结语
掌握高效的数据采集方法,是解锁数字世界宝藏的钥匙。无论是初创企业还是成熟团队,云端数据采集平台如集蜂云,以其便捷高效的特点,成为数据驱动决策的强大助手。选择合适的方法,让数据成为您的智囊团,引领业务走向成功。















 2567
2567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









