







1.字符编码(Encode)与字体(Font)显示概述
如图1,大家在阅读器界面看到的不同字体和尺寸的"好"字(左边宋体小二,右边楷体小二),在电子书txt格式文档中的原始数据是如何存储的呢?

图1 左边宋体小二,右边楷体小二
实际上,采用不同编码格式,其表示方法是不同的,以下是四种常用编码格式的表示方法。
utf8: 0xE5A5BD
utf16-le: 0x7D59
utf16-be: 0x597D
ascii/gbk:0xBAC3
关于这四种常用编码方式的基本规则和概念,在此不详细介绍了,
有兴趣的爱好者可以看看阮一峰老师的这篇博客:
但自此说明的是,我把gbk和ascii码放在一起,是因为ascii本身只是标准英文字符集编码,是不包含汉字的,
gbk是在ascii字符集之后,按照相应规则,扩充了汉字库,并完全包含了ascii字符集(有点C和C++ 语法集的关系)。
但是gbk并不是国际通用汉字标准,只是中国大陆地区自制的编码标准,所以才有gbk编码的文本,容易出现乱码现象,
可能需要转换成unicode码才能互相传输显示(另外,港台汉字采用big-5编码)。
一个txt文档里的原始文字变成屏幕上显示的各种字体和大小的字符的过程如图2所示。通过基本概念的解释,
让爱好者意识,显示的字体和编码的字符是不同的基本概念,接下将详细介绍编码和字体系统的框架。
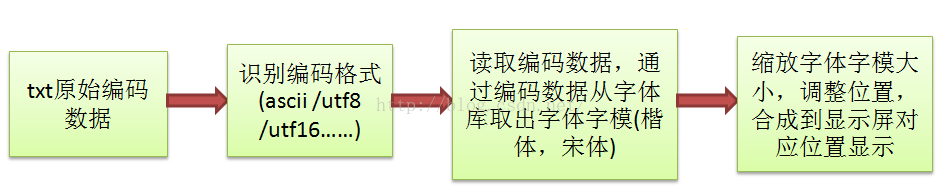
图2 原始txt文本编码数据到显示在屏幕上的字体转换过程
2.字符编码系统(Encode System) 架构与API
1).系统框架
字符编码系统由核心层与各个组件部分,其架构图如图3所示。每个组件都是可装载卸载的,即系统不需要实现所有组件,仅需要激活一个组件就能使用该组件在组件指定的特性和范围中运行,本项目其它子系统都是采用这种可装载卸载组件的方法架构和设计的。

图3 字符编码系统框架
Encode System core:
字符编码系统的核心层,用于封装字符编码相关的复杂业务逻辑与数据交换,Book Engine通过输入原始txt文档文件,由Encode system内部组件自动匹配对应的编码格式,然后选用对应的解码格式化组件,无法匹配的字符编码格式文件将返回错误。
2). API简介
encode system 相关头文件在include/encode.h中声明。
encode:
编码系统核心结构描述符encode 声明如下:
typedef struct encode{
char *name;
struct encode_attr attr;
int (*is_support)(char *file_buf_head);
int (*get_fmtcode_frm_buf)(__u8 *curr_addr, __u8 *buf_end, __u32 *fmtcode);
struct encode *next;
}encode;
中获取。
attr:
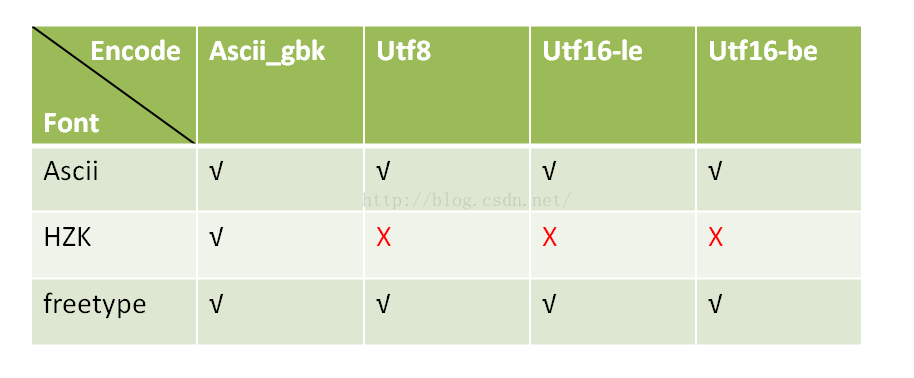
encode 的属性attr包含了该encode对应编码格式所能自动识别的txt文件该编码前缀长度head_len(如:utf8格式文件头长度),
以及suppt_font_h,表示编码encode支持适配的的字体字模库的链表,并非每钟编码方式都能能支持所有的字库字模,本项目
编码格式所能支持的字体字模库对应表如表1所示。
表1 encode所支持的font对应关系表
is_support():
通过读取文件前head_len个字符,自动识别文件的编码格式,来选择自动对应的encode
get_fmtcode_frm_buf():
从已识别编码格式的文件中,获取经过unicode格式化的字符编码,系统可以unicode格式化后的字符编码到font
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









