







- 将solr-7.3.1.tgz上传到linux,解压到/user/local/server/solr
- 进入bin目录下启动solr:./solr start -force #linux下要求跟参数-force,默认在8983端口启动。
- 创建core: ./solr create -c core1 -force
- 重启jetty: ./solr restart -p 8983 -force
简单增删改查操作:
public class SolrTest {
// solr url
private final static String BASE_URL = "http://192.168.209.151:8983/solr";
/**
* 获取SolrClient
* solrj 6.5及以后版本获取方式
* @return
*/
public static HttpSolrClient getSolrClient(){
/*
* 设置超时时间
* .withConnectionTimeout(10000)
* .withSocketTimeout(60000)
*/
return new HttpSolrClient.Builder(BASE_URL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
}
//操作文档必须制定操作的core,如core1
@Test
public void docmentAdd() throws SolrServerException, IOException{
HttpSolrClient client = getSolrClient();
SolrInputDocument document =new SolrInputDocument();
// 执行添加 ps:如果id相同,则执行更新操作
document.addField("id", "47896");
document.addField("bookName", "平凡的世界");
document.addField("bookType", "文学小说");
document.addField("bookPrice", 89);
// 要指定操作的collection 就是solr-home下定义的core,
UpdateResponse response = client.add("core1", document);
client.commit();
}
@Test
public void documentQuery() throws SolrServerException, IOException{
HttpSolrClient client = getSolrClient();
Map<String, String> params =new HashMap<String,String>();
params.put("q", "*:*");
MapSolrParams solrParams = new MapSolrParams(params);
//执行查询 第一个参数是collection,就是我们在solr中创建的core
QueryResponse response = client.query("core1", solrParams);
// 获取结果集
SolrDocumentList results = response.getResults();
for (SolrDocument result : results) {
// SolrDocument 数据结构为Map
System.out.println(result);
}
}
@Test
public void testDelete() throws IOException, SolrServerException {
HttpSolrClient solrClient = getSolrClient();
// 通过id删除 执行要删除的collection(core)
solrClient.deleteById("core1", "47896");
// 还可以通过查询条件删除
// solrClient.deleteByQuery("core1", "查询条件"); //查询条件:"*:*" 删除所有,慎用
// 提交删除
solrClient.commit("core1");
}
solr 7.3安装配置、中文分词配置
- 什么是solr,solr是Apache开源的一个分词索引库软件,其他另行百度
- solr 下载安装
- 下载地址: 点击打开链接
- 解压下载的压缩包,solr 7.3 不需要使用Tomcat启动,自带jetty,
- window运行: bin/solr.cmd start,solr默认端口为8983
- 访问:http://localhost:8983/solr/

- solr 配置
- 创建core,solr.cmd create -c articles。其中articles是core的名称,可以自定义。
- 重启solr:solr.cmd -p 8983 restart
- 查看core:打开solr控制台,点击"Core Admin",列表中出现"articles",说明core创建成功
- 测试分词,选择刚才创建的core,点击Analysis进入分词分析页面,输入要分词的句子,选择分词库,点击分析按钮,即可看到分词结果
- solr默认不支持中文分词

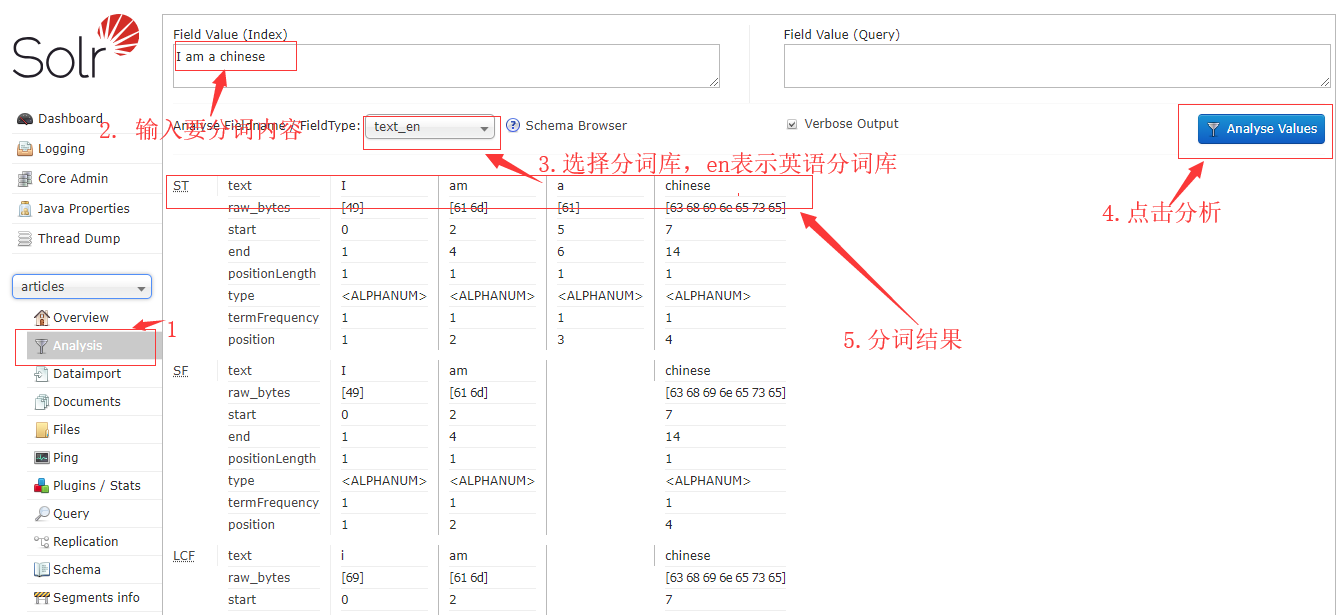
- 中文分词插件配置
- 添加中文分词插件:solr 7.3中自带中文分词插件,将solr-7.3.1\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-7.3.1.jar 复制到 solr-7.3.1\server\solr-webapp\webapp\WEB-INF\lib 目录中
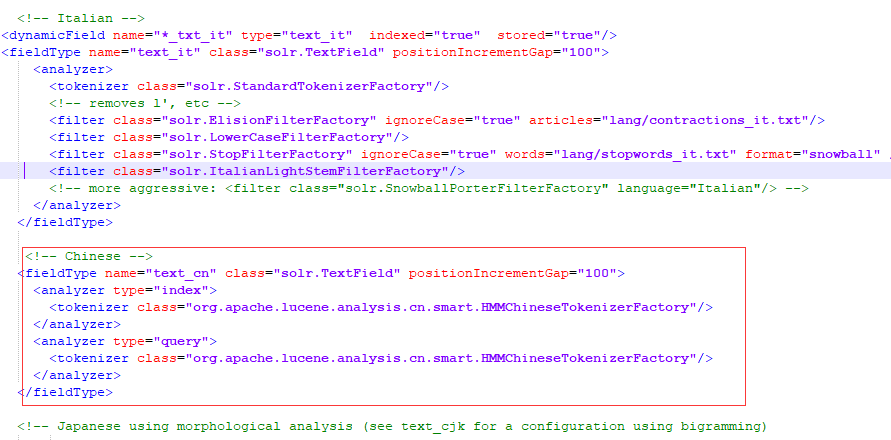
- 配置中文分词,修改 solr-7.3.1\server\solr\articles【创建的core的名称】\conf\managed-schema文件,添加中文分词
-
<!-- Chinese -->
-
<fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100">
-
<analyzer type="index">
-
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
-
</analyzer>
-
<analyzer type="query">
-
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
-
</analyzer>
-
</fieldType>
-
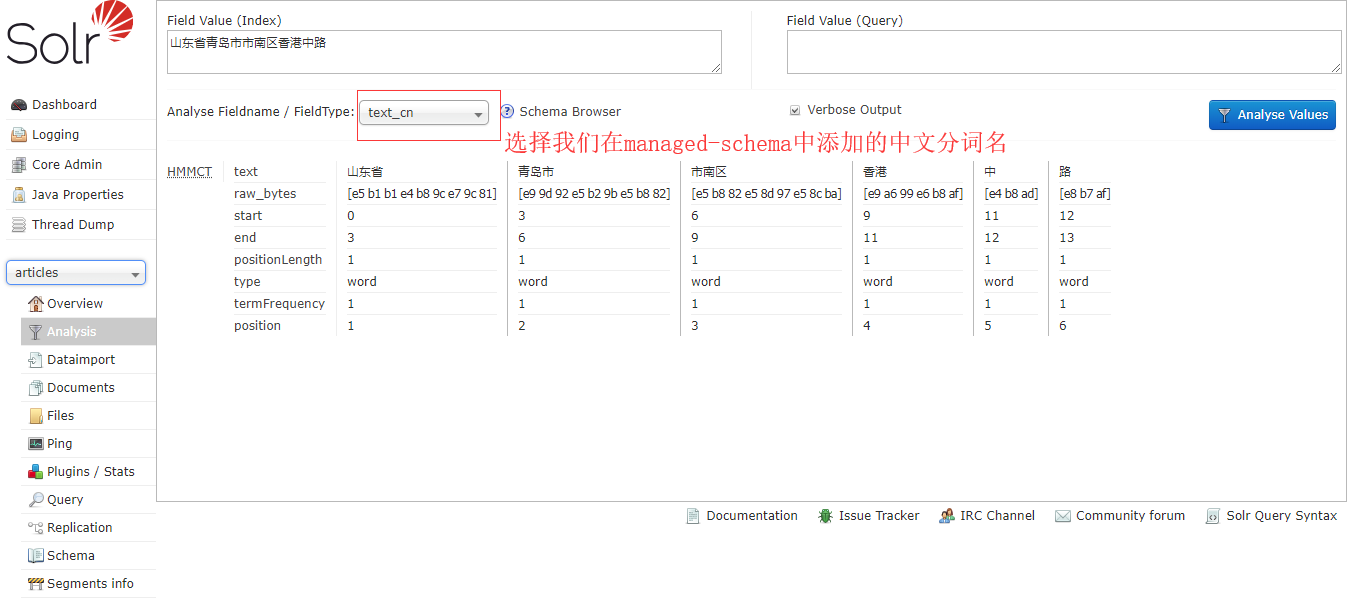
- 重启solr,测试中文分词
- OK















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









