







redis
缓存击穿
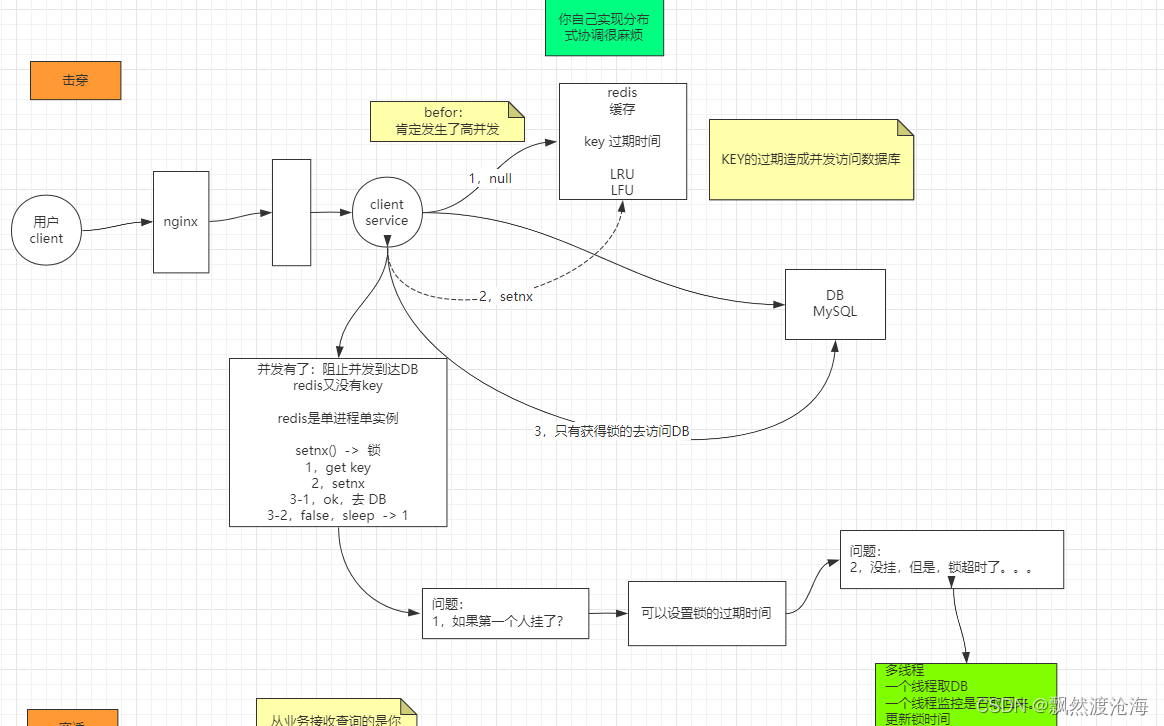
缓存一般收到内存大小限制,key 可能会被LRU LFU清掉,也有可能设置过期时间删除了,因为某些key不在redis里面了,大量并发来找这个key的时候,客户端直接去请求数据库,这就是缓存击穿
解决办法
- 设置key永远不过期,或者快过期时,通过另一个异步线程重新设置key
- 当从缓存拿到的数据为null,重新从数据库加载数据的过程上锁
这里其实还是会存在一个问题:
- 如果第一个拿到锁的人挂了,别人也拿不到锁,这样就死锁了。可以设置锁的过期时间来避免这个问题。
- 由于我设置了过期时间,可能会发生这样的情况:拿到锁的人没挂,但是可能由于网络拥塞或者数据库拥塞,锁超时了,又有一个人拿到这个锁,又去数据库取,更加拥塞了。
针对这个问题,可以开启多个线程,一个线程去库里取数据,另一个线程去给锁的超时时间延长。这样会让代码逻辑变得复杂。 - 像上面这样,你自己去实现分布式协调很麻烦。因此我们引入Zokeeper
提示啊,缓存雪崩是指大量缓存失效,缓存击穿是指热点数据的缓存失效!!!
提示啊,缓存雪崩是指大量缓存失效,缓存击穿是指热点数据的缓存失效!!!
提示啊,缓存雪崩是指大量缓存失效,缓存击穿是指热点数据的缓存失效!!!
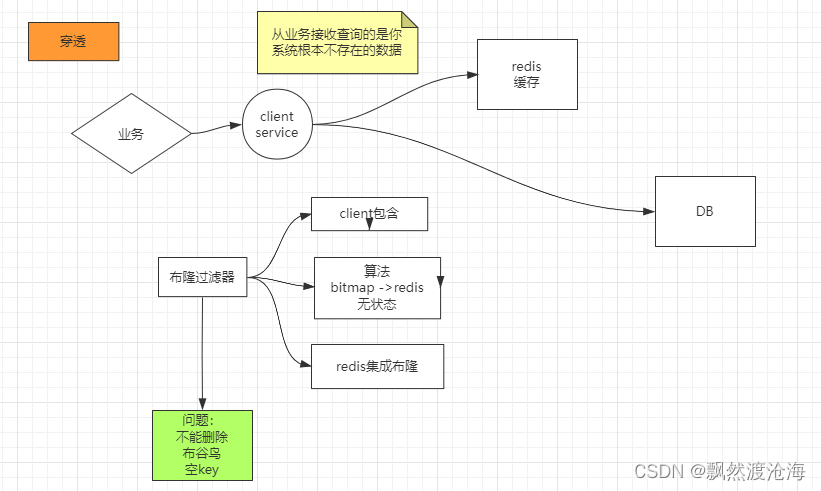
缓存穿透
假如客户端每秒发送5000个请求,其中4000个为黑客的恶意攻击,即在数据库中也查不到。举个例子,用户id为正数,黑客构造的用户id为负数,如果黑客每秒一直发送这4000个请求,缓存就不起作用,数据库也很快被打死。
怎么解决?
- 对请求参数进行校验,不合理直接返回
- 查询不到的数据也放到缓存,value为空,如 set -999 “”
- 使用布隆过滤器
- 你可以在客户端中包含布隆过滤器的算法
- 你可以在客户端只包含算法,在redis中存放bitmap
- 你可以直接在redis中集成布隆模块:RedisBloom模块
布隆过滤器的缺点:只能增加,不能删除,如果你的业务删除了数据库中的某条数据,无法在布隆过滤器中删除这个key
解决方式:你可以使用布谷鸟过滤器等其他支持删除操作的过滤器,或者设置一个空 key
第一种是最基本的策略,第二种其实并不常用,第三种比较常用。
为什么第二种并不常用呢?
因为如果黑客构造的请求id是随机数,第二种并不能起作用,反而由于缓存的清空策略,(例如清除最近没有被访问的缓存)导致有用的缓存被清除了。
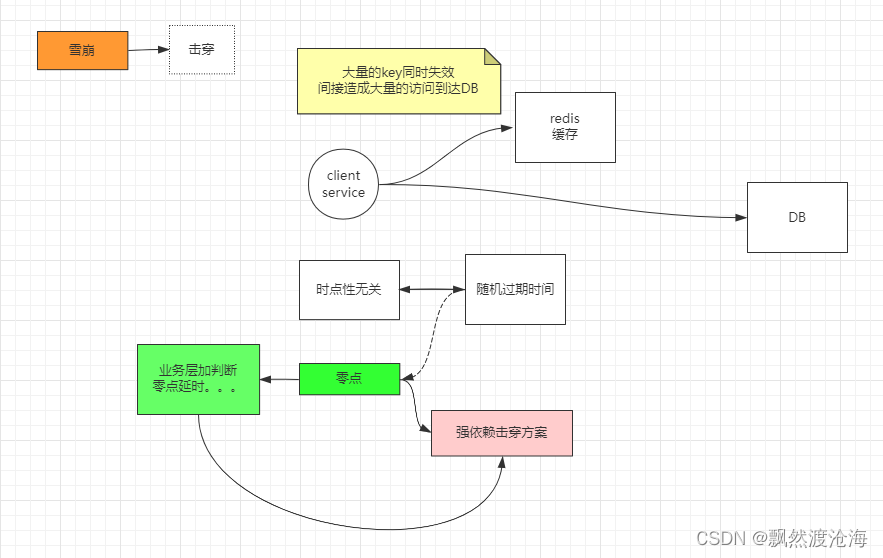
缓存雪崩
假设有如下一个系统,高峰期请求为5000次/秒,4000次走了缓存,只有1000次落到了数据库上,数据库每秒1000的并发是一个正常的指标,完全可以正常工作,但如果缓存宕机了,或者缓存设置了相同的过期时间,导致缓存在同一时刻同时失效,每秒5000次的请求会全部落到数据库上,数据库立马就死掉了,因为数据库一秒最多抗2000个请求,如果DBA重启数据库,立马又会被新的请求打死了,这就是缓存雪崩。
解决方法
- 事前:redis高可用,主从+哨兵,redis cluster,避免全盘崩溃
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL被打死
- 事后:redis持久化RDB+AOF,快速恢复缓存数据
- 缓存的失效时间设置为随机值,避免同时失效
redis 分布式锁
1,setnx
2,过期时间
3,多线程(守护线程)延长过期
可以使用j ava Sedisson API
参考地址:https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95/
也可以用 zookeeper 做分布式锁,这样是最容易的。虽然zookeeper没有redis快,但是比redis能够加强准确性。
这里面还是牵扯到CAP理论啊,兄弟萌,分布式环境下面,这个理论是逃不过去的
CAP指的是在一个分布式系统中:
一致性(Consistency)
可用性(Availability)
分区容错性(Partition tolerance)
这三个要素最多只能同时实现两点,不可能三者兼顾。
如果你的实际业务场景,更需要的是保证数据一致性。那么请使用CP类型的分布式锁,比如:zookeeper,它是基于磁盘的,性能可能没那么好,但数据一般不会丢。
如果你的实际业务场景,更需要的是保证数据高可用性。那么请使用AP类型的分布式锁,比如:redis,它是基于内存的,性能比较好,但有丢失数据的风险。
其实,在我们绝大多数分布式业务场景中,使用redis分布式锁就够了,真的别太较真。因为数据不一致问题,可以通过最终一致性方案解决。但如果系统不可用了,对用户来说是暴击一万点伤害。














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









