







Elasticsearch
多字段特性及配置自定义Analyzer
多字段类型

Exact Values v.s Full Text
- Excat values V.S Full Text
- Exact Value:包括数字/日期/具体一个字符串(例如“Apple Store”)
- Elasticseach 中的keyword
- 全文本, 非结构化的文本数据
- Elasticsearch 中的text
- Exact Value:包括数字/日期/具体一个字符串(例如“Apple Store”)
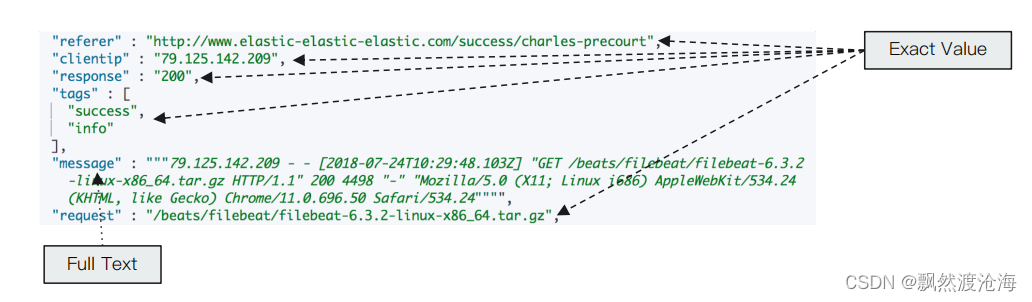
Exact Values不需要被分词
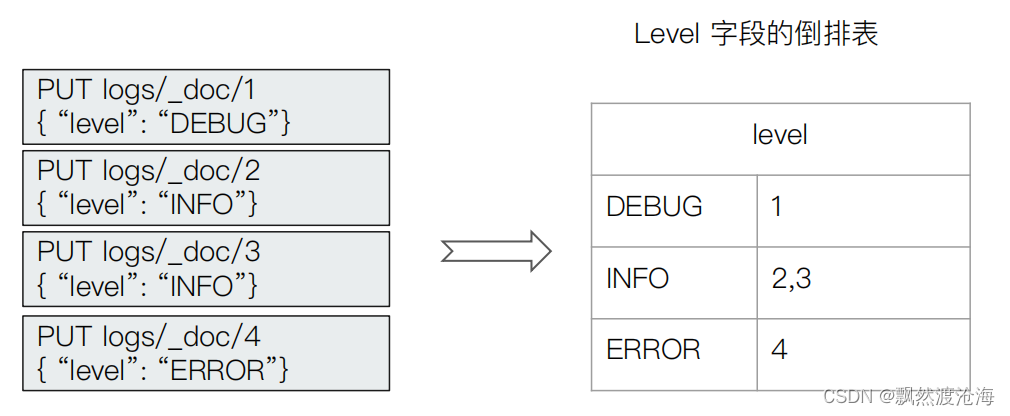
- Elasticsearch 为每一个字段创建一个倒排索引
- Exact Value在索引时,不需要做特殊的分词处理
自定义分词
- 当 Elasticsearch自带的分词器无法满足时,可以自定义分词器。通过自组合不同的组
件实现.- Character Filter
- Tokenizer
- Token Filter
Character Filters
- 在Tokenizer之前对文本进行处理,例如增加删除及替换字符。可以配置
多个Character Filters。 会影响Tokenizer的position和offset信息 - 一些自带的Character Filters
- HTML strip 一出除html标签
- Mapping -字符串 替换
- Pattern replace - -正则匹配替换
Tokenizer
-
将原始的文本按照一 定的规则,切分为词(term or token)
-
Elasticsearch 内置的Tokenizers
- whitespace/ standard / uax_ ur _email / pattern / keyword / path hierarchy
-
可以用Java开发插件,实现自己的Tokenizer
Token Filters
- 将Tokenizer输出的单词( term ),进行增加,修改,删除
- 自 带的Token Filters
- Lowercase / stop / synonym (添加近义词)
设置一个Custom Analyzer

API
PUT logs/_doc/1
{"level":"DEBUG"}
GET /logs/_mapping
POST _analyze
{
"tokenizer":"keyword",
"char_filter":["html_strip"],
"text": "<b>hello world</b>"
}
POST _analyze
{
"tokenizer":"path_hierarchy",
"text":"/user/ymruan/a/b/c/d/e"
}
#使用char filter进行替换
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ "- => _"]
}
],
"text": "123-456, I-test! test-990 650-555-1234"
}
//char filter 替换表情符号
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ ":) => happy", ":( => sad"]
}
],
"text": ["I am felling :)", "Feeling :( today"]
}
// white space and snowball
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
// whitespace与stop
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The rain in Spain falls mainly on the plain."]
}
//remove 加入lowercase后,The被当成 stopword删除
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["lowercase","stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
//正则表达式
GET _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "pattern_replace",
"pattern" : "http://(.*)",
"replacement" : "$1"
}
],
"text" : "http://www.elastic.co"
}
Index Template和Dynamic Template
管理很多的索引|
- 集群上的索引会越来越多, 例如,你会为你的日志每天创建-个索引
- 使用多个索引可以让你更好的管理你的数据,提高性能
- logs-2019-05-01
- logs- -2019-05- -02
- logs- 2019-05-03
什么是Index Template
- Index Templates -帮助你设定Mappings和Settings,并按照一定 的规则,
自动匹配到新创建的索引之上- 模版仅在一个索引被新创建时, 才会产生作用。修改模版不会影响已创
建的索引 - 你可以设定多 个索引模版,这些设置会被“merge”在一起
- 你可以指定 “order”的数值,控制“merging”的过程
- 模版仅在一个索引被新创建时, 才会产生作用。修改模版不会影响已创
两个Index Templates

Index Template的工作方式
- 当一个索|被新创建时
- 应用Elasticsearch默认的settings和mappings
- 应用order数值低的Index Template中的设定
- 应用order高的Index Template中的设定,之前的设定会被覆盖
- 应用创建索引时,用户所指定的Settings和Mappings, 并覆盖之前模版中的设定
什么是Dynamic Template
-
根据Elasticsearch识别的数据类型,结合字段名称,来动态设定字段类型
+ 所有的字符串类型都设定成Keyword, 或者关闭keyword字段 + is开头的字段都设置成boolean + long_ 开头的都设置成long类型
Dynamic T emplate

匹配规则参数

API
#数字字符串被映射成text,日期字符串被映射成日期
PUT ttemplate/_doc/1
{
"someNumber":"1",
"someDate":"2019/01/01"
}
GET ttemplate/_mapping
#Create a default template
PUT _template/template_default
{
"index_patterns": ["*"],
"order" : 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas":1
}
}
PUT /_template/template_test
{
"index_patterns" : ["test*"],
"order" : 1,
"settings" : {
"number_of_shards": 1,
"number_of_replicas" : 2
},
"mappings" : {
"date_detection": false,
"numeric_detection": true
}
}
#查看template信息
GET /_template/template_default
GET /_template/temp*
#写入新的数据,index以test开头
PUT testtemplate/_doc/1
{
"someNumber":"1",
"someDate":"2019/01/01"
}
GET testtemplate/_mapping
get testtemplate/_settings
PUT testmy
{
"settings":{
"number_of_replicas":5
}
}
put testmy/_doc/1
{
"key":"value"
}
get testmy/_settings
DELETE testmy
DELETE /_template/template_default
DELETE /_template/template_test
#Dynaminc Mapping 根据类型和字段名
DELETE my_index
PUT my_index/_doc/1
{
"firstName":"Ruan",
"isVIP":"true"
}
GET my_index/_mapping
DELETE my_index
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string",
"match":"is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
DELETE my_index
#结合路径
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
PUT my_index/_doc/1
{
"name": {
"first": "John",
"middle": "Winston",
"last": "Lennon"
}
}
GET my_index/_search?q=full_name:John















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









