






1 需要更新ComfyUI到最新版本,更新起来也非常方便
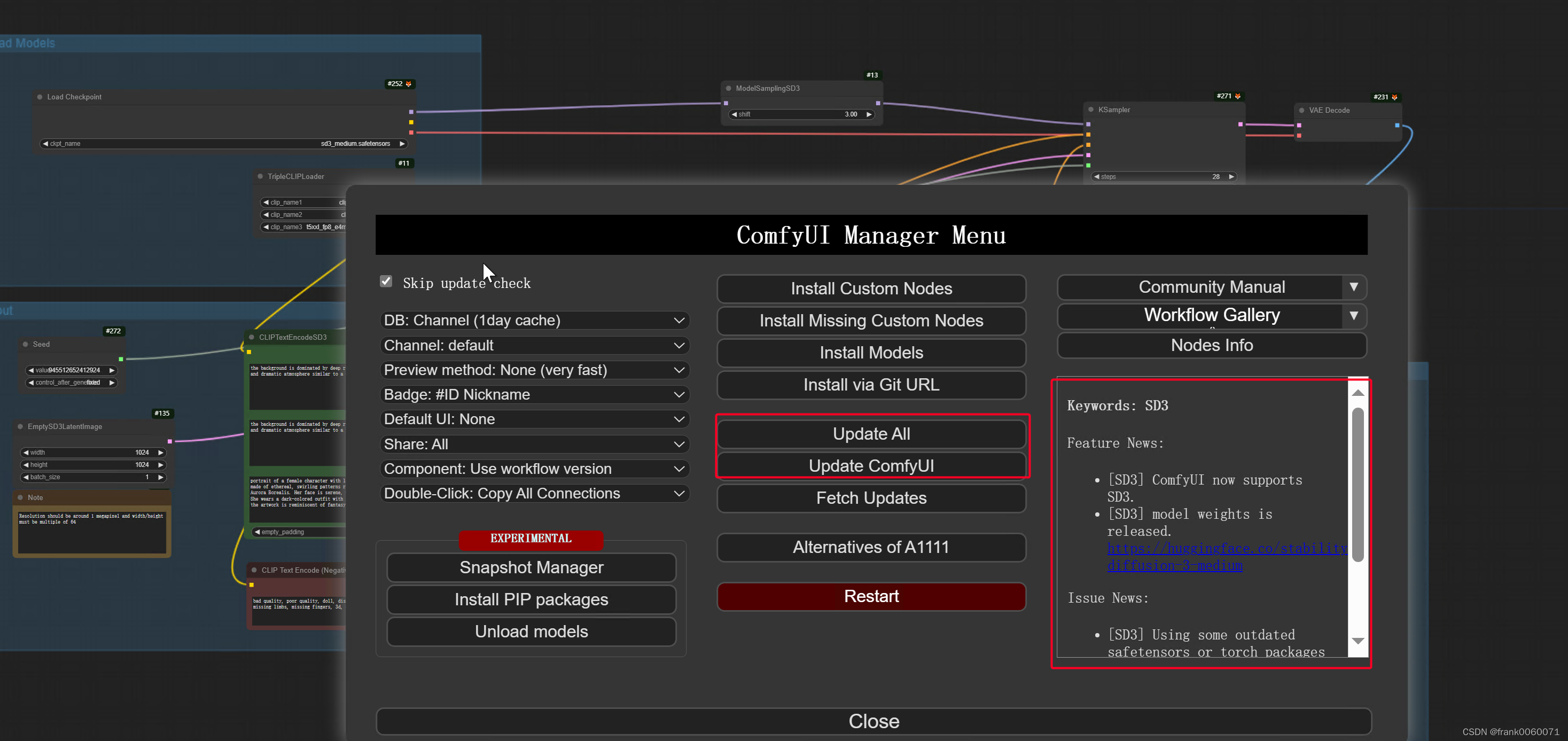
或者到目录下 git full即可
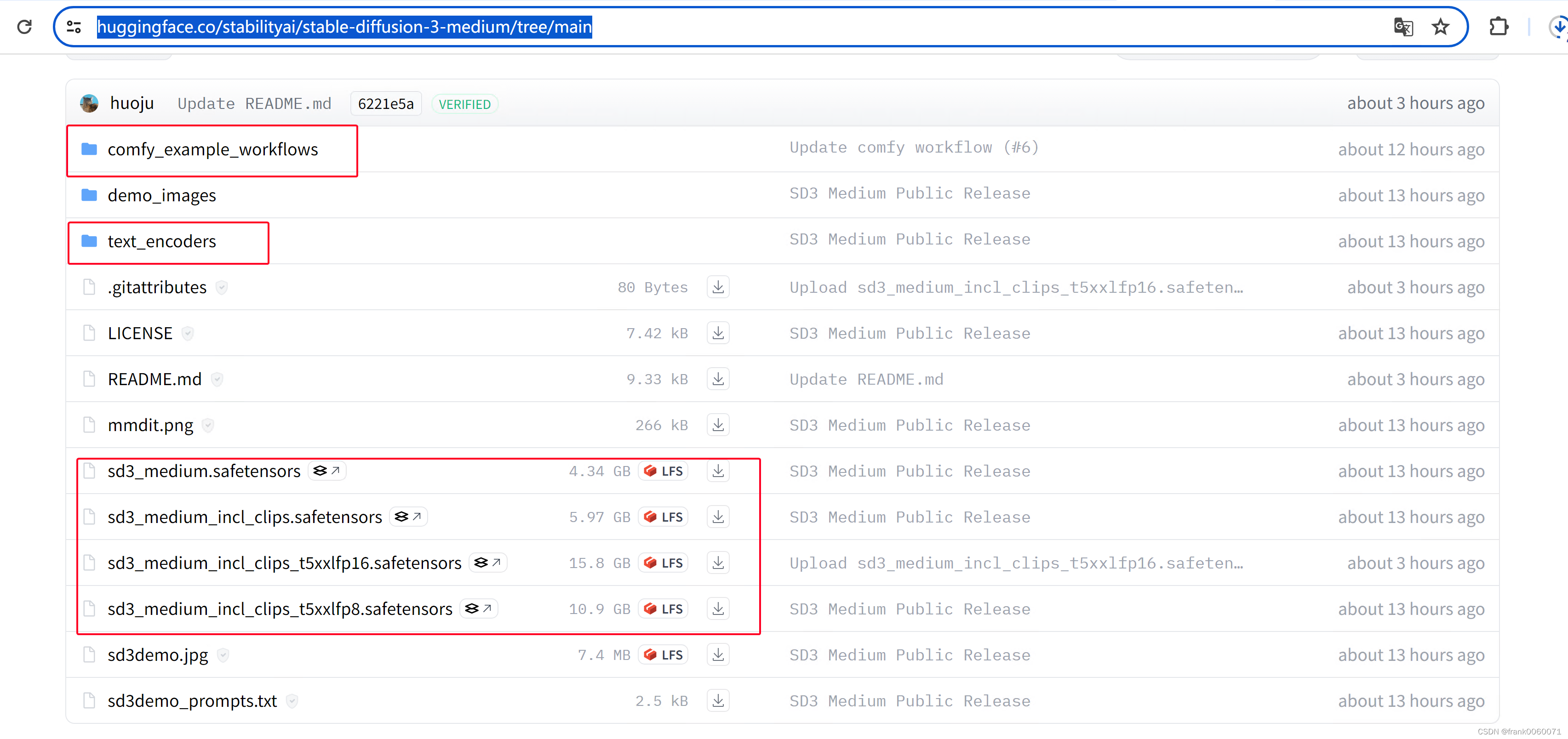
2 ComfyUI更新完成后,便是开始下载需要的模型和案例
https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main
当然也可以网盘进行下载
SD3 百度网盘 模型下载链接 : https://pan.baidu.com/s/1gRA3ezoP-rUbLAYM07lU6Q
提取码:5gw6
差异2-prompt提示词:由于text-encoder模型换成了带有微调T5模型的3个Clip模型组,因此这就导致了当前开源的这一版本的SD3模型输入提示词的方式和之前有了重大差异。原本采用1girl,UHD, realistic, 3D等等关键字形式的prompt全部失去意义,现在SD3正确的打开方式应该是和DALLE3或MJ-V6类似的自然语言描述方式,比如这种prompt:
a female character with long, flowing hair that appears to be made of ethereal, swirling patterns resembling the Northern Lights or Aurora Borealis. The background is dominated by deep blues and purples, creating a mysterious and dramatic atmosphere. The character's face is serene, with pale skin and striking features. She wears a dark-colored outfit with subtle patterns. The overall style of the artwork is reminiscent of fantasy or supernatural genres.
并且,负面提示词也可以基本不需要写一大串,甚至可以完全不写负面提示词。本来负面提示词的存在就是因为之前Clip模型输入长度和理解能力受限才采用的方式,目前因为T5强大的性能,完全可以不需要再使用负面提示词来保证输出质量了。
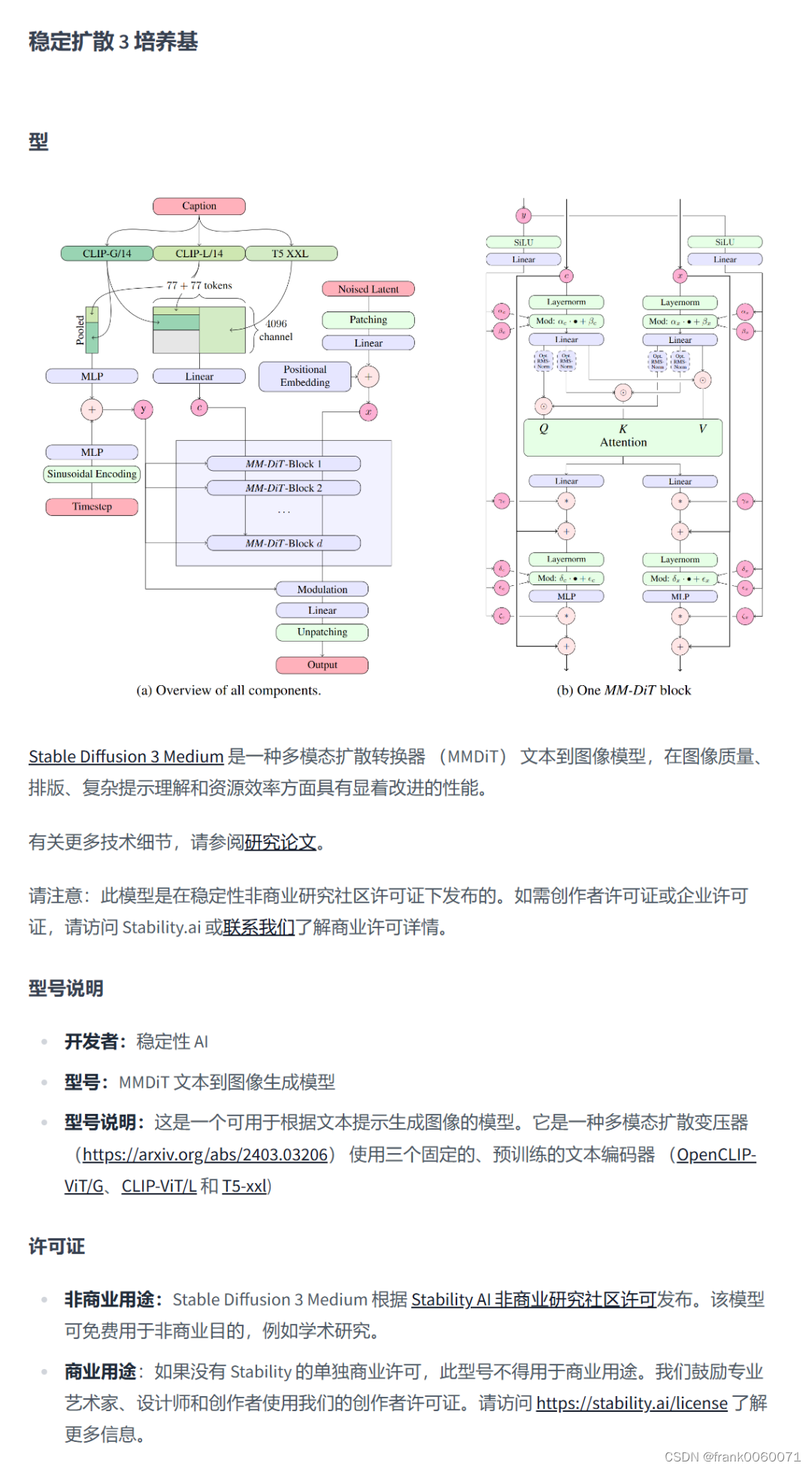
网上有人整理了部分信息如下
差异1-text-encoder模型:也是我认为这次SD3和之前的SDXL和1.5最核心的差异其实是文本对齐方式不同。从这张测试对比图可以看到上面效果比较好的图片SD3模型和text-encoder模型是分开加载的。我们从之前公布的技术报告可以看到这次SD3的text-encoder模型从原本的Clip模型换成了著名的Google开源的encoder-decoder架构的T5模型,换成T5最大的一个优势在于可以支持更长、更详细的文本作为prompt了。
差异2-prompt提示词:由于text-encoder模型换成了带有微调T5模型的3个Clip模型组,因此这就导致了当前开源的这一版本的SD3模型输入提示词的方式和之前有了重大差异。原本采用1girl,UHD, realistic, 3D等等关键字形式的prompt全部失去意义,现在SD3正确的打开方式应该是和DALLE3或MJ-V6类似的自然语言描述方式,比如这种prompt:
a female character with long, flowing hair that appears to be made of ethereal, swirling patterns resembling the Northern Lights or Aurora Borealis. The background is dominated by deep blues and purples, creating a mysterious and dramatic atmosphere. The character's face is serene, with pale skin and striking features. She wears a dark-colored outfit with subtle patterns. The overall style of the artwork is reminiscent of fantasy or supernatural genres.
并且,负面提示词也可以基本不需要写一大串,甚至可以完全不写负面提示词。本来负面提示词的存在就是因为之前Clip模型输入长度和理解能力受限才采用的方式,目前因为T5强大的性能,完全可以不需要再使用负面提示词来保证输出质量了。
差异3-VAE:SD3模型开源之后,我第一时间去寻找的并非是SD3的基础模型,而是想看看这次重新训练的VAE模型文件到底多大,结果非常让我意外的是,这次SD3的VAE直接内置到了base model里面了,并没有单独提供VAE模型。这样我们也就没办法拿SD3的VAE模型用于其他的训练任务中了
差异4-文本生成能力:如前面所述,因为VAE模型的通道数增加,使得SD3生成带有文字的图片效果大大强于之前SD系列模型,这也是之前Stablity AI重点宣传和介绍的模型能力。当然这还是仅限于生成英文内容而非中文,并且可以预估的未来SD系列模型的中文生成能力也不会太好,这一点恐怕还有指望与开源社区的各路大神来微调训练来解决了。
差异5-多模型集成:与之前SDXL和1.5系列模型还有一个显著区别是这一开源的SD3-2B包括3个不同的模型版本,按照集成模型的类型分别如下:
sd3_medium.safetensors 包括 MMDiT 和 VAE 权重,但不包括任何文本编码器。使用该模型需要配置额外的clip 模型
sd3_medium_incl_clips_t5xxlfp8.safetensors 包含所有必要的权重,包括 T5XXL 文本编码器的 fp8 版本,提供质量和资源需求之间的平衡。所以使用该模型 则不需要额外的clip 信息
sd3_medium_incl_clips.safetensors 包括所有必要的权重,除了 T5XXL 文本编码器。它需要最少的资源,但模型的性能将在没有 T5XXL 文本编码器的情况下有所不同。
也可以看看如下链接的对论文的解读
https://zhuanlan.zhihu.com/p/685447966
提示词的差异
https://www.zhihu.com/question/658752661/answer/3528705649
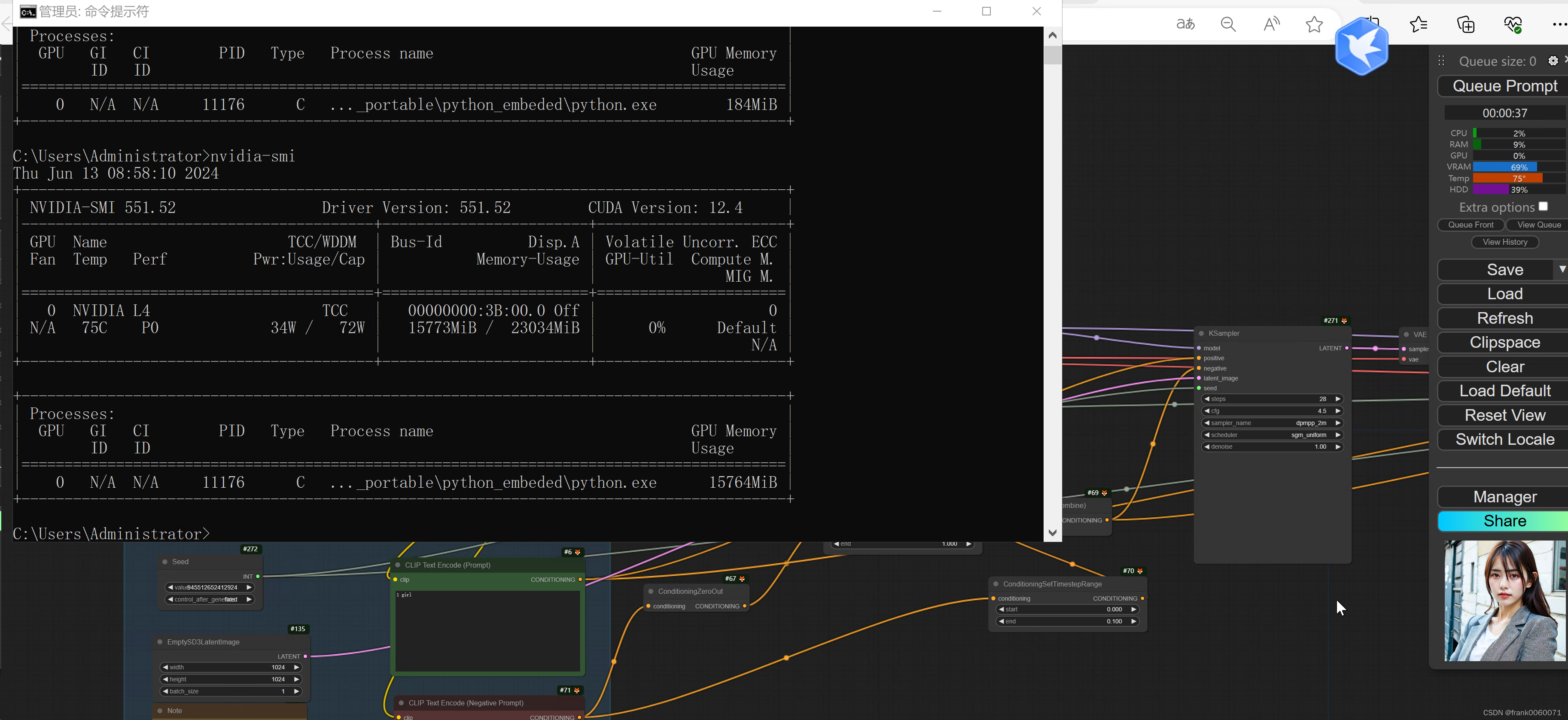
在实际使用过程中 如下还是要注意对GPU 资源的消耗,基本都超过12GB显存以上了



















 7714
7714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











