







注意:后续技术分享,第一时间更新,以及更多更及时的技术资讯和学习技术资料,将在公众号CTO Plus发布,请关注公众号:CTO Plus

在前面的文章中自定义了一个简单的 ArticleSerializer2类, 并分别以函数视图(FBV)和基于类的视图(CBV)编写了博客文章列表资源和单篇文章资源的API,支持客户端以各种请求方式对文章资源进行增删查改。本文详细介绍DRF的序列化器,如何修改序列化器控制序列化后响应数据的输出格式,以及如何在反序列化时对客户端提供过来的数据进行验证(validation)以及如何重写序列化器类自带的create和update方法,如何通过一个序列化器创建两个模型对象。
参考文章:
2、DRF实战总结:基于函数的视图API以及自定义序列化器(附源码)_SteveRocket的博客-CSDN博客
3、DRF实战总结:基于类的视图APIView, GenericAPIView和GenericViewSet视图集(附源码)_SteveRocket的博客-CSDN博客
序列化器特点
- 将复杂的数据结构与python对象之间进行转换;
- 可以根据输入和输出数据的需要进行多级嵌套。
- 改变序列化输出数据的格式可以通过指定字段的source来源,使用SerializerMethodField自定义方法以及使用嵌套序列化器。
- 支持可以自定义验证和转换方法:反序列化时需要对客户端发送的数据进行验证。可以通过自定义validate方法进行字段或对象级别的验证,还可以使用自定义的validators或DRF自带的验证器。
- 当使用嵌套序列化器后,多个关联模型同时的创建和更新的行为并不明确,需要显示地重写create和update方法。
Article模型和自定义的序列化器ArticleSerializer2类分别引用前面两章的内容,如下所示。
# drf_pro/models.py
# drf_pro/serializers.py
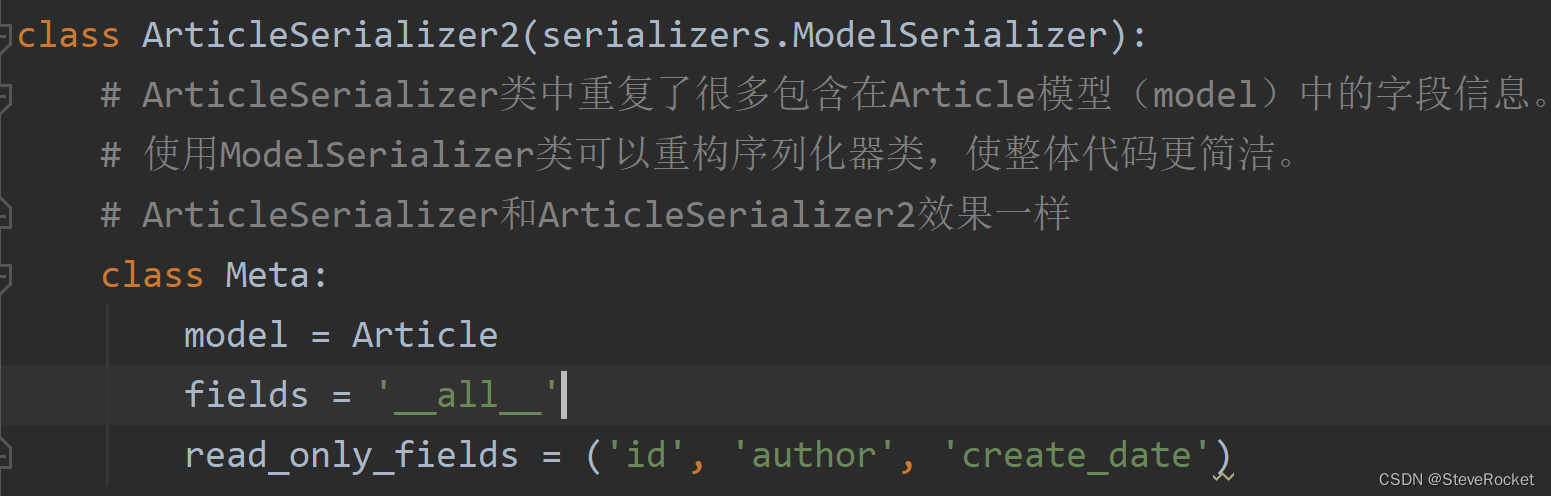
自定义的序列化器ArticleSerializer2类包括了Article模型的所有字段,但由于不希望用户自行修改id, author和create_date三个字段,把它们设成了仅可读read_only_fields。
使用ModelSerializer序列化器后的方式,发送GET请求到/v1/articles
[GET] http://127.0.0.1:8000/v1/articles
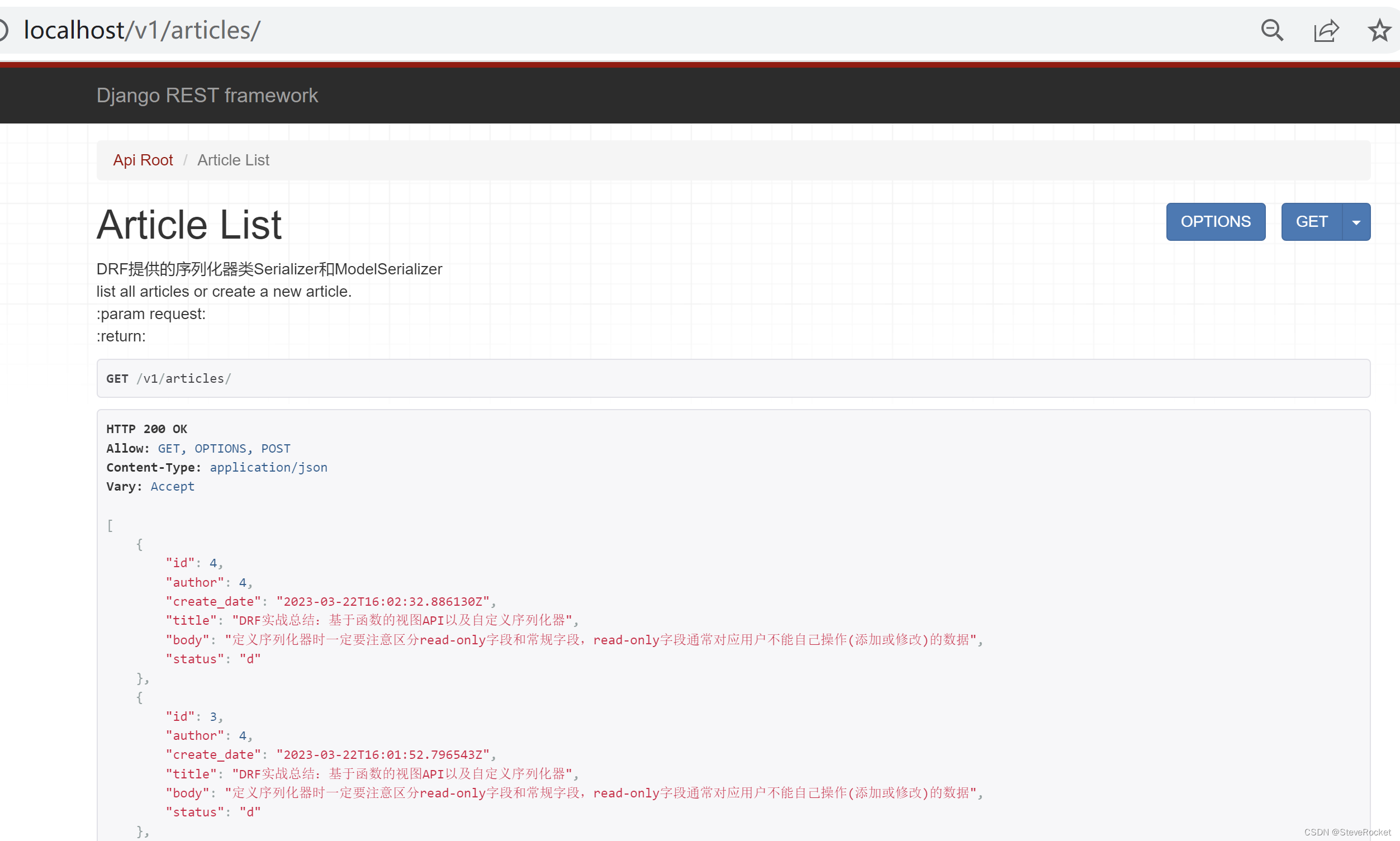
在这里可以看到序列化后输出的json格式数据里author字段输出的是用户id,而不是用户名,status输出的是p或者d,而不是输出Published或Draft这样的完整状态,这显然对用户不是很友好的。这时就要修改序列化器,控制序列化后的数据输出格式。
通过指定source来源
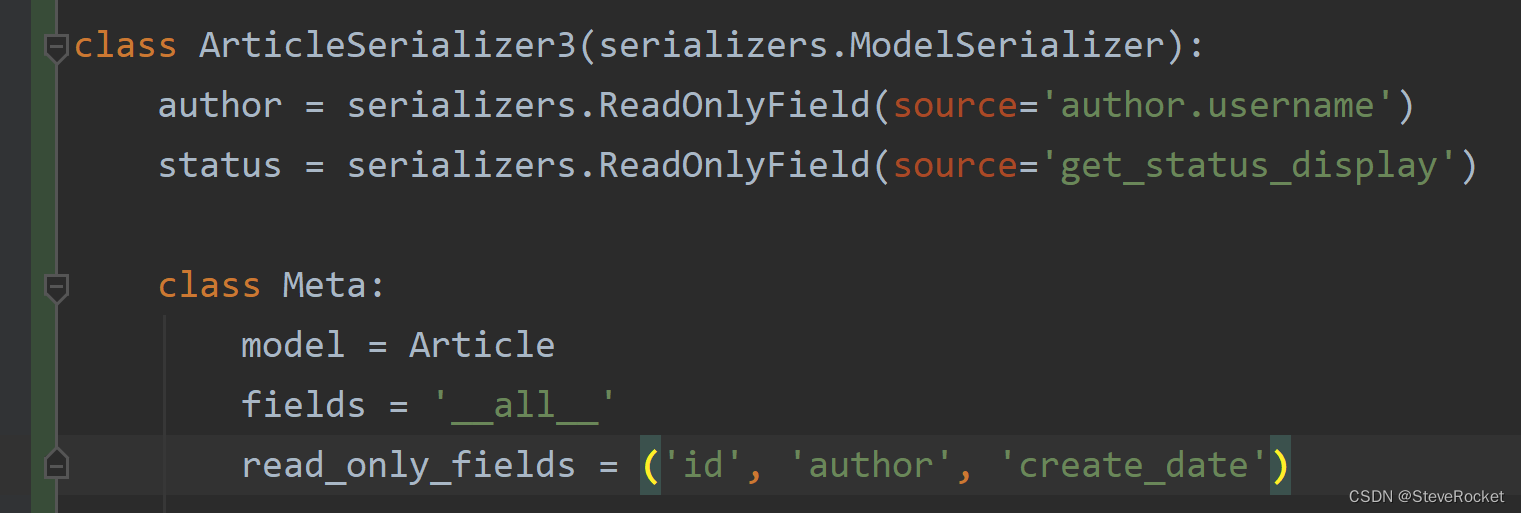
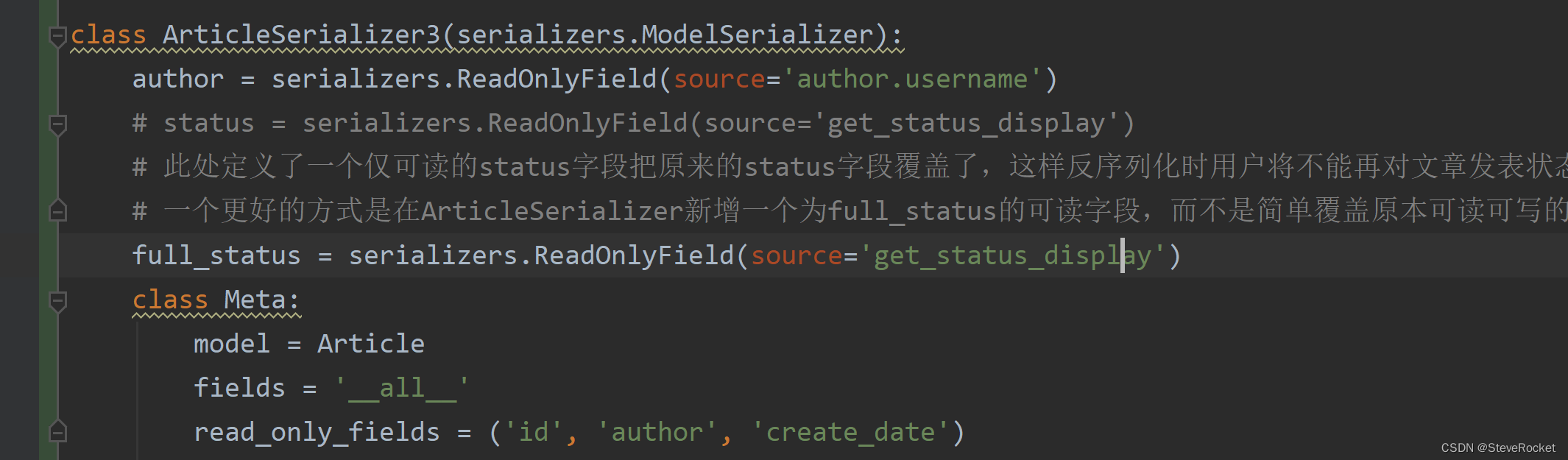
打开drf_pro/serializers.py,新建两个可读字段author和status字段,用以覆盖原来Article模型默认的字段,其中指定author字段的来源(source)为原单个author对象的username,status字段为get_status_display方法返回的完整状态。
请求查看输出的数据格式
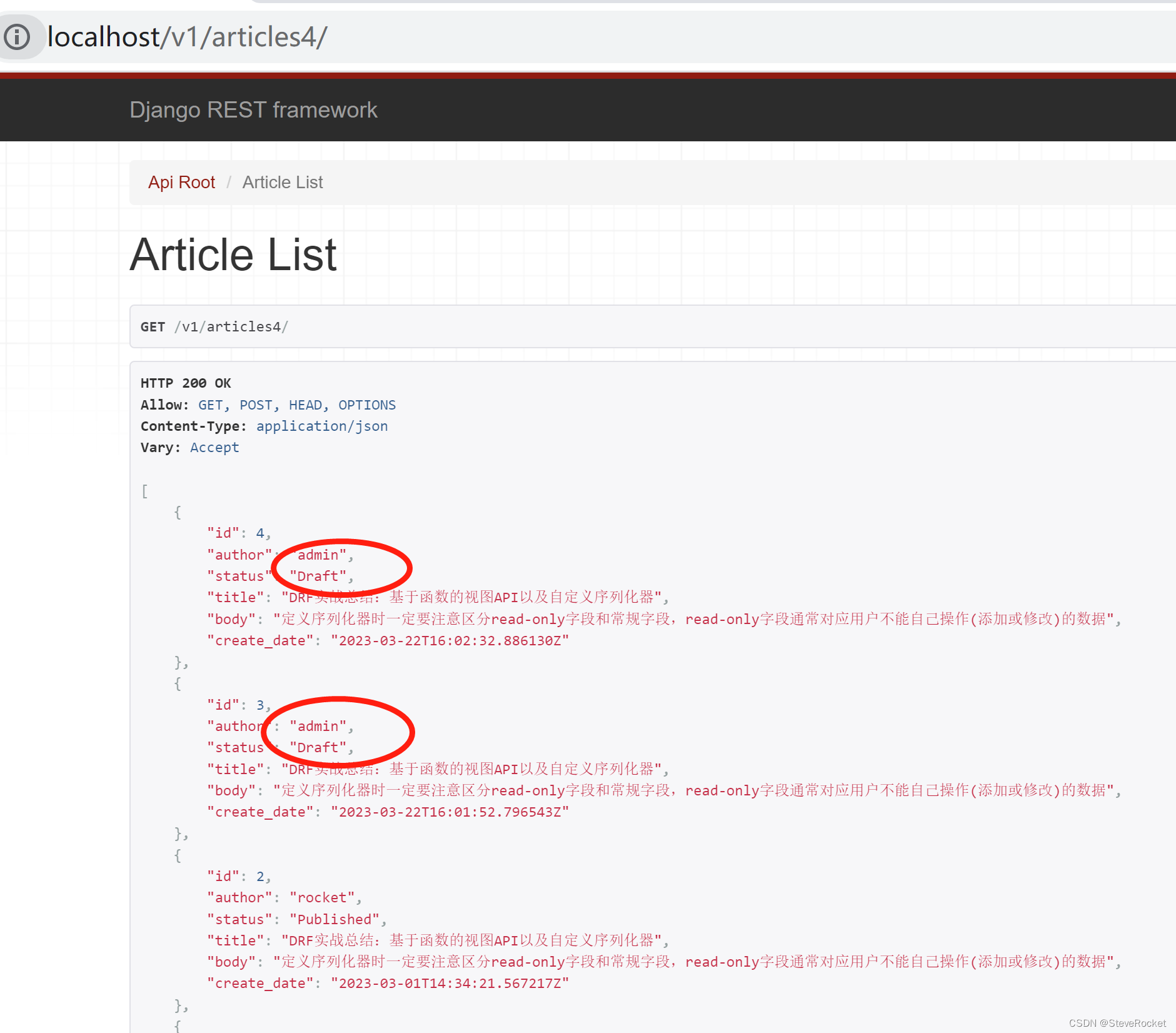
注意:此处定义了一个仅可读的status字段把原来的status字段覆盖了,这样反序列化时用户将不能再对文章发表状态进行修改(原来的status字段是可读可修改的)。一个更好的方式在ArticleSerializer新增一个为full_status的可读字段,而不是简单覆盖原本可读可写的字段。
通过使用SerializerMethodField自定义方法
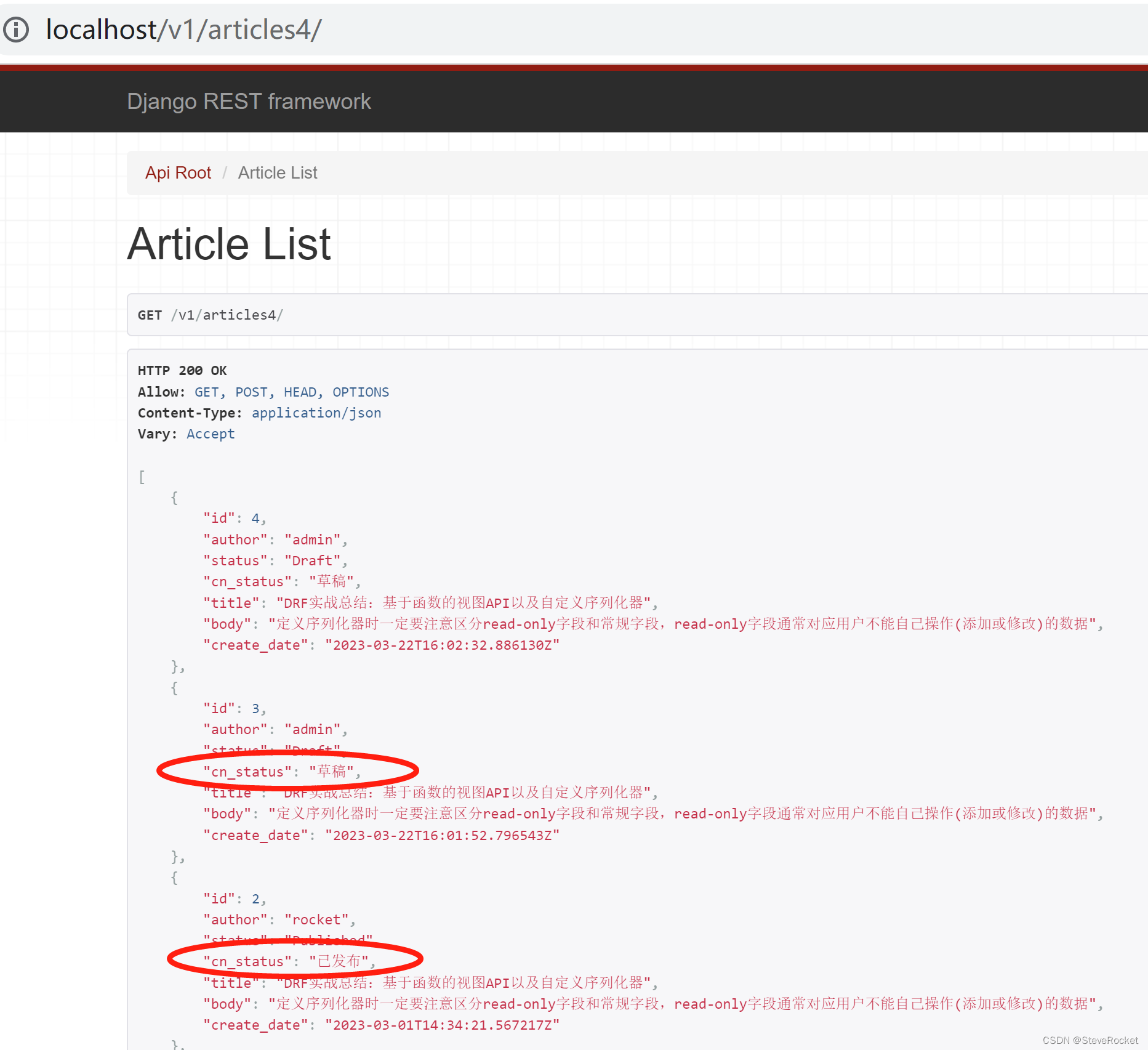
上面例子中文章状态status都是以Published或Draft英文字符串表示的,但是如果想在输出的json格式数据中新增cn_status字段,显示中文发表状态。但cn_status本身并不是Article模型中存在的字段,此时应该使用SerializerMethodField,它可用于将任何类型的数据添加到对象的序列化表示中, 非常有用。
修改drf_pro/serializers.py,新建cn_status字段,格式为SerializerMethodField,然后再自定义一个get_cn_status方法输出文章中文发表状态即可。

再次请求查看输出的数据格式
注意:SerializerMethodField通常用于显示模型中原本不存在的字段,类似可读字段,不能通过反序列化对其直接进行修改。
使用嵌套序列化器
嵌套序列化器指的是在一个序列化器中,再嵌套一个或多个序列化器,来完成复杂数据结构的序列化,比如:
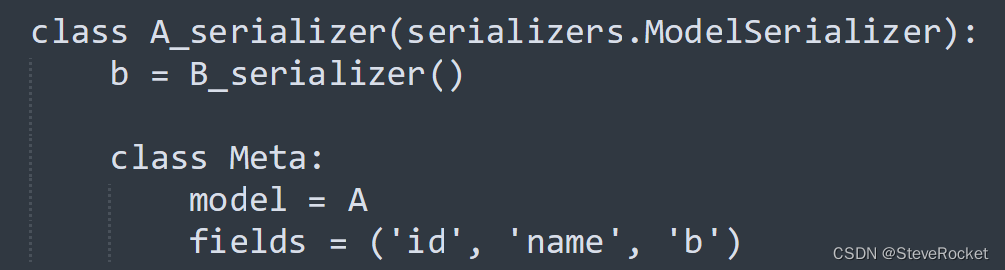
A_serializer中嵌套了B_serializer,用于完成A与B之间的一对一嵌套关系的序列化。
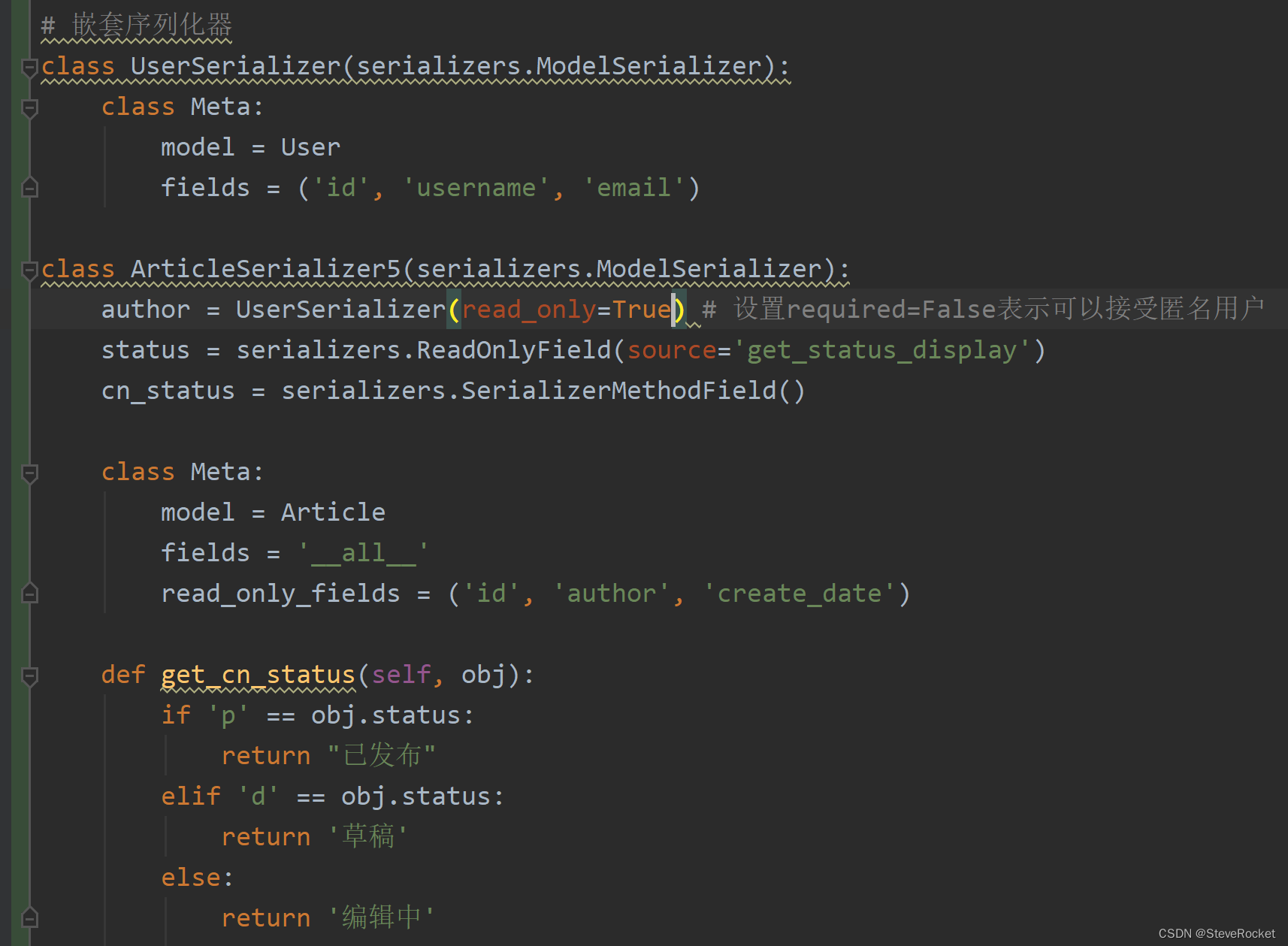
文章中的author字段实际上对应的是一个User模型实例化后的对象,既不是一个整数id,也不是用户名这样一个简单字符串,如果想显示更多用户对象信息,就可以使用嵌套序列化器。
展示效果如下所示:
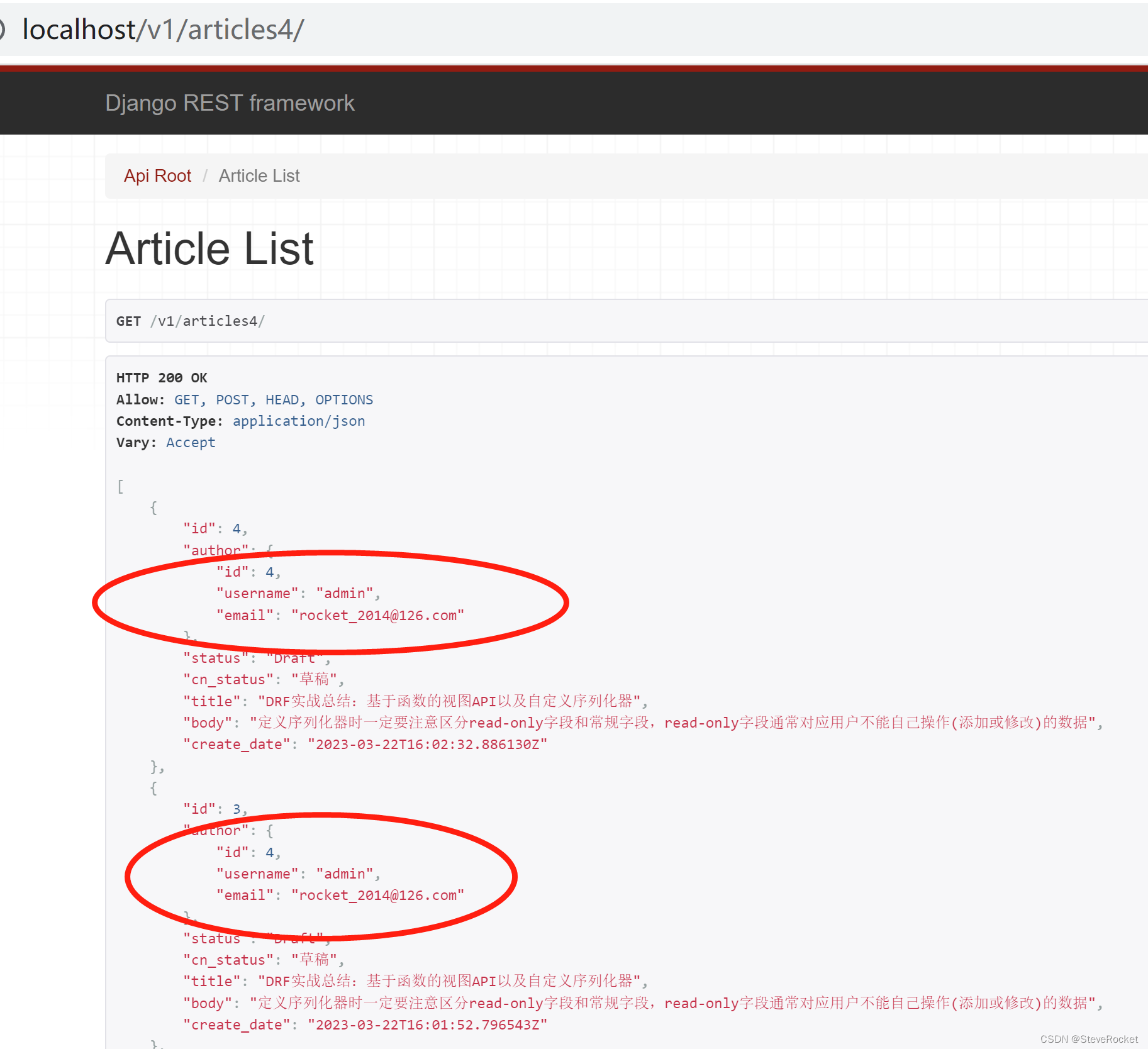
此时发送GET请求展示文章列表资源是没问题的,但如果希望发送POST请求到v1/articles/提交新文章将会收到author字段是required的这样一个错误。为了使代码正确工作,还需要手动指定read_only=True这个选项。尽管在Meta选项已经指定了author为read_only_fields, 但使用嵌套序列化器时还需要重新指定一遍。
- author = UserSerializer(read_only=True)
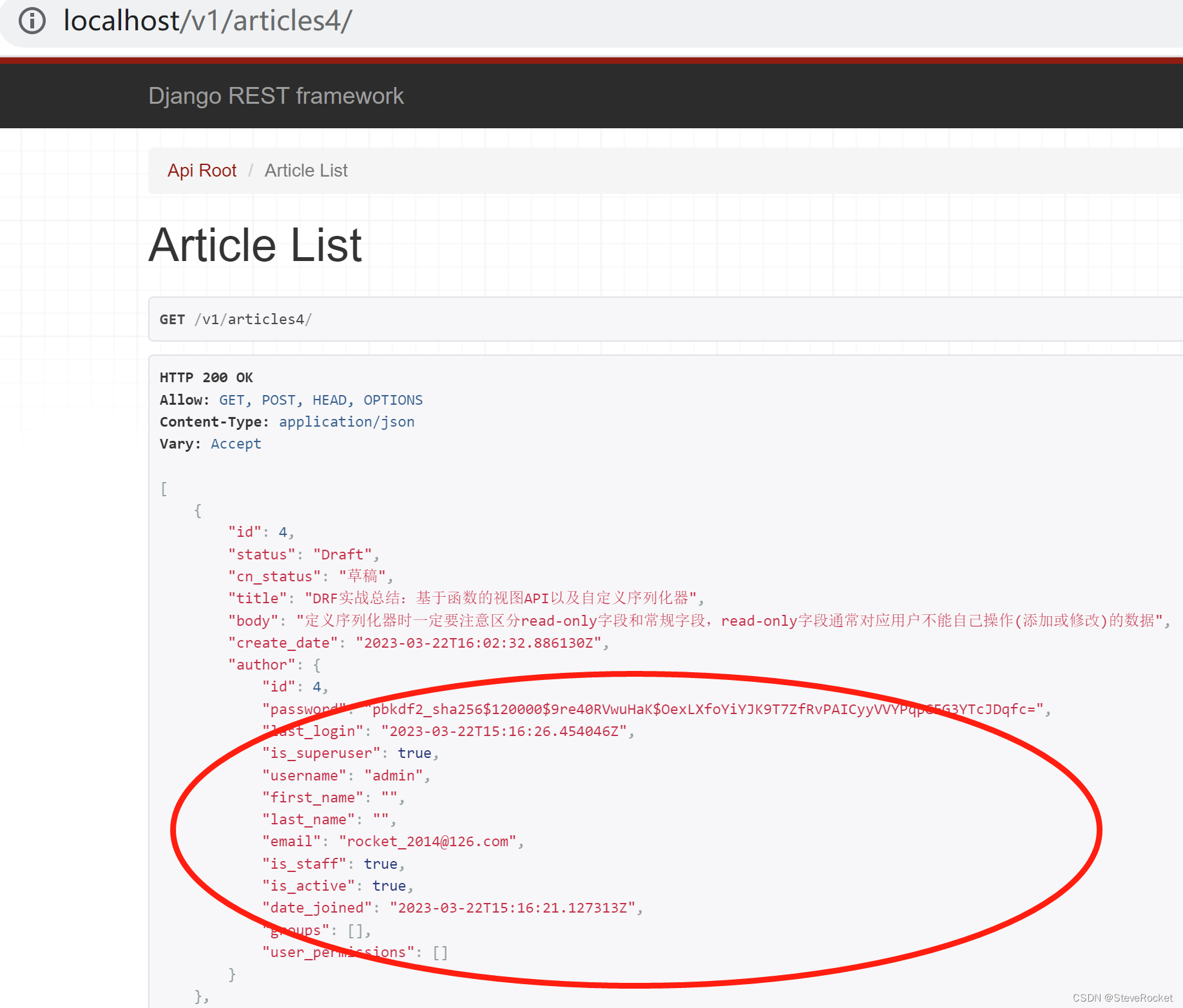
另一个解决方式是不使用嵌套序列化器,通过设置关联模型的深度depth(通常1-4)实现, 如下所示:
展示效果如下。这种方法虽然简便,但使用时要非常小心,因为它会展示关联模型中的所有字段。比如下例中连密码password都展示出来了,显然不是想要的。
前面介绍的都是如何通过修改序列化器来控制输出数据的展现形式,接下来着重看如何在反序列化时对客户端提供过来的数据进行验证(validation)以及如何重写序列化类自带的save和update方法。由于官方文档中有更好的例子,将会使用这些案例。
数据验证 (Validation)
在反序列化数据时,在尝试访问经过验证的数据或保存对象实例之前,总是需要调用 is_valid()方法。如果发生任何验证错误,.errors 属性将包含表示结果错误消息的字典,如下所示:
serializer = CommentSerializer(data={'email': 'foobar', 'content': 'baz'})
serializer.is_valid()
# False
serializer.errors
# {'email': [u'Enter a valid e-mail address.'], 'created': [u'This field is required.']}字典中的每个键都是字段名称,值是与该字段对应的任何错误消息的字符串列表。non_field_errors 键也可能存在,并将列出任何常规验证错误。可以使用REST framework设置中的NON_FIELD_ERRORS_KEY来自定义 non_field_errors 键的名称。
当反序列化项目列表时,错误将作为表示每个反序列化项目的字典列表返回。
引发无效数据的异常 (Raising an exception on invalid data)
.is_valid() 方法使用可选的 raise_exception 标志,如果存在验证错误,将会抛出 serializers.ValidationError 异常。这些异常由REST framework提供的默认异常处理程序自动处理,默认情况下将返回 HTTP 400 Bad Request 响应。
# Return a 400 response if the data was invalid.
serializer.is_valid(raise_exception=True)字段级别验证 (Field-level validation)
可以通过向 Serializer 子类中添加 .validate_<field_name> 方法来指定自定义字段级的验证。这些类似于 Django 表单中的 .clean_<field_name> 方法。这些方法采用单个参数,即需要验证的字段值。
validate_<field_name> 方法应该返回已验证的值或抛出 serializers.ValidationError 异常。例如:
注意:如果在序列化器上声明了 <field_name> 的参数为 required=False,那么如果不包含该字段,则此验证步骤不会发生。
对象级别验证 (Object-level validation)
要执行需要访问多个字段的任何其他验证,需要添加名为 .validate() 的方法到 Serializer 子类中。此方法采用单个参数,该参数是字段值的字典。如果需要,它应该抛出 ValidationError 异常,或者只返回经过验证的值。例如:
验证器 (Validators)
序列化器上的各个字段都可以包含验证器,通过在字段实例上声明,例如:
DRF还提供了很多可重用的验证器,比如:
1. `UniqueValidator`:用于验证字段的唯一性;
2. `UniqueTogetherValidator`:用于验证一组字段的组合唯一性;
3. `RegexValidator`:用于验证字段与给定的正则表达式匹配;
4. `EmailValidator`:用于验证邮箱格式是否正确;
5. `MaxLengthValidator`:用于验证字段长度是否超过最大长度限制;
6. `MinLengthValidator`:用于验证字段长度是否小于最小长度限制;
7. `URLValidator`:用于验证URL地址是否合法。
8. DecimalValidator
9. FileExtensionValidator
这些验证器可以用来实现一些通用的数据验证逻辑,提高了代码的可重用性和编写效率。
通过在内部 Meta 类上声明来包含这些验证器,如下例中会议房间号和日期的组合必须要是独一无二的。
重写序列化器的create和update方法
假设有个Profile模型与User模型是一对一的关系,当用户注册时希望把用户提交的数据分别存入User和Profile模型,这时就不得不重写序列化器自带的create方法了。
通过一个序列化器创建两个模型对象示例:
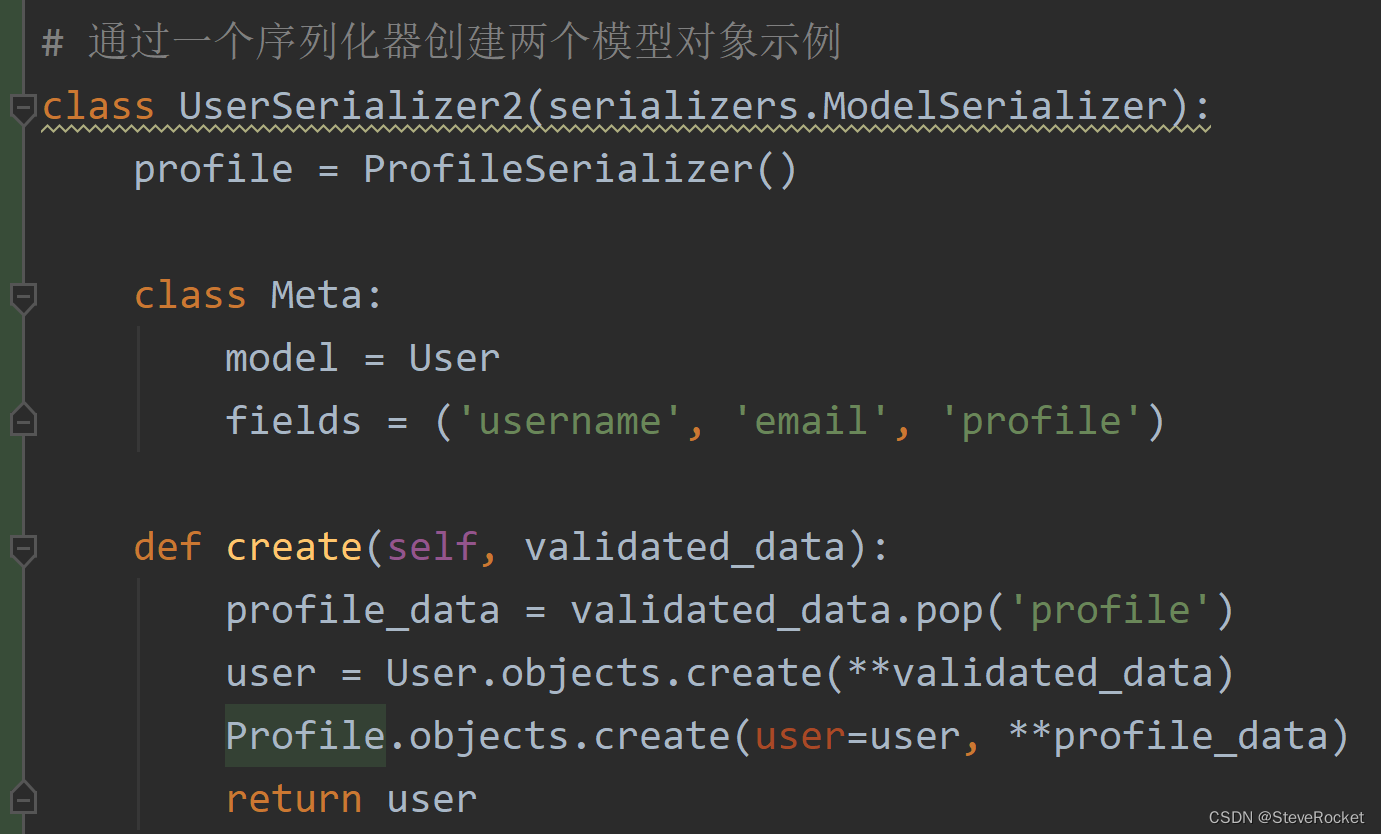
同时更新两个关联模型实例时也同样需要重写update方法。

因为序列化器使用嵌套后,创建和更新的行为可能不明确,并且可能需要相关模型之间的复杂依赖关系,REST framework 3 要求始终显式的编写这些方法。默认的 ModelSerializer.create() 和 .update() 方法不包括对可写嵌套表示的支持,所以总是需要对create和update方法进行重写。
代码地址:https://download.csdn.net/download/zhouruifu2015/87652849
参考文章
Validators | Django documentation | Django

输入才有输出,吸收才能吐纳。——码字不易![]()

















 1601
1601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











