







论文地址:BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection
代码地址:https://github.com/HuangJunJie2017/BEVDet
1、引言
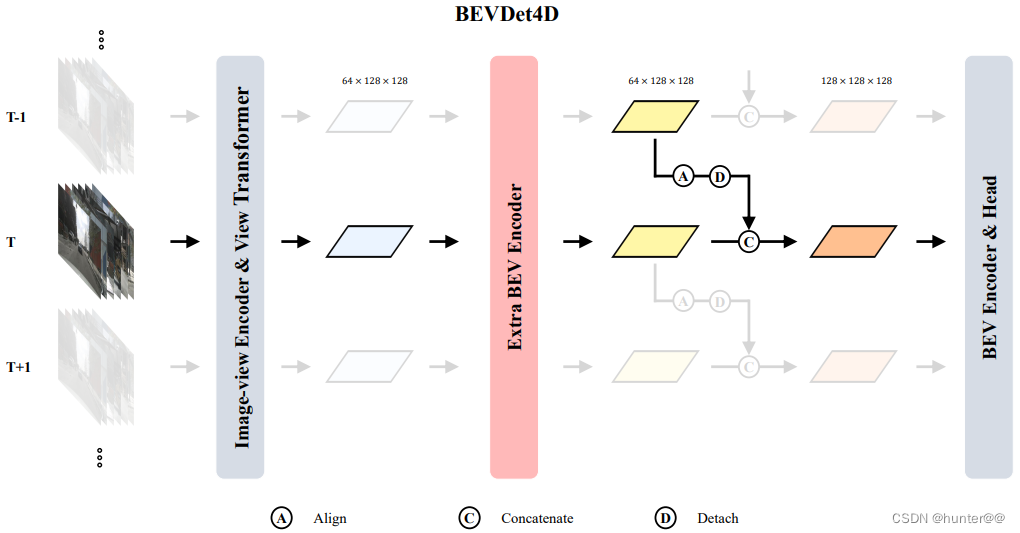
BEVDet4D是BEVDet在时间维度上拓展的一次尝试,通过保留过去帧的中间BEV特征,将其与当前帧的BEV特征进行融合构建BEV特征。极大地减小了速度的预测误差,使得其到达了和基于激光雷达和毫米波雷达方法的一样的预测精度。
2、方法
2.1 pipeline
BEVDet4D的网络结构基本与BEVDet的网络结构基本类似,都包含4大基本模块:image-view encoder、view transformer、BEV encder、task-specific head。
同时。为了融入历史t-1帧的信息,BEVDet4D 保留了 view transformer 对历史t-1帧生成的BEV特征。然后进行对齐,和当前t帧的BEV特征完成融合。
注意:这里的融合方式是将t-1时刻的BEV特征和t时刻的BEV特征在Channel维度进行concat拼接。
2.2 历史t-1帧和当前t帧对其模块:速度简化预测模块
这一小节主要讲解一下对其操作,也是BEVDet4D中的核心模块(也就是代码中的self.shift_feature函数)。
Symbol Definition(符号定义)
| 全局坐标系(以世界坐标系为中心) | |
| T时刻的自车坐标系(以自车为中心) | |
| T时刻的目标坐标系(以目标为中心) | |
| 全局坐标系下的静态物体(s) | |
| 全局坐标系下的动态物体(m) | |
| 表示在其中定义位置的坐标系 | |
| 时刻表(T表示当前时刻,T-1表示上一时刻) | |
| 从源坐标系到目标坐标系的转换矩阵 |
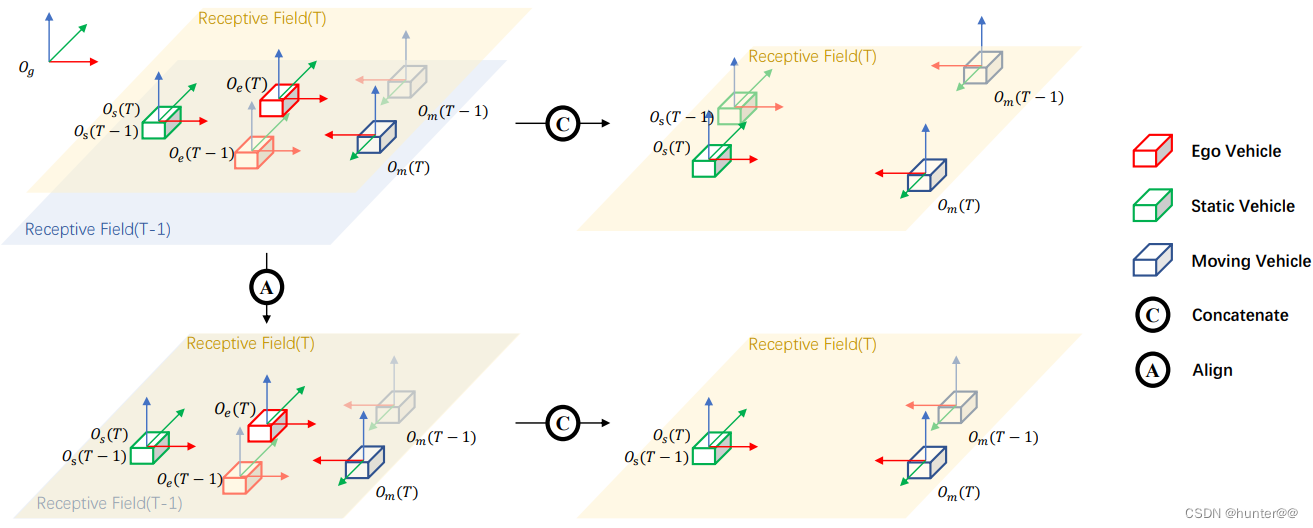
图2的具体解释:
Receptive Field(T-1)表示的是T-1时刻的BEV特征图,Receptive Field(T)表示是T时刻的BEV特征图,现在需要将T和T-1时刻的BEV特征都利用起来,那么应该怎么做呢??
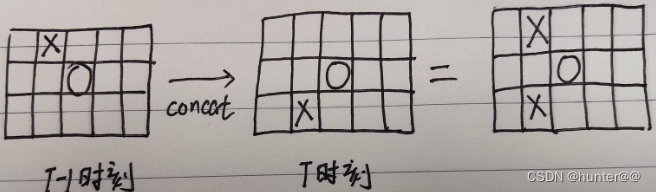
注意这里并不能直接将T时刻的BEV特征和T-1时刻的BEV特征直接concat起来(图2的C分支),因为这样会导致特征错位的问题,具体可以用图3来表示,X表示的就是障碍物,T-1时刻在车的左前方有一个障碍物X,由于其是静止不动的,随着时间的变化,到T时刻的时候,X就移动到车的左后了,此时的BEV特征就发生了变化,如果将其直接concat的话,那T时刻的BEV特征图上车的左前和左后方都出现了障碍物,这显然是不对的。因此在T时刻和T-1时刻特征拼接之前,先进行一个特征对齐就很关键(图2的A分支)。
用公式来解释的话:
- 对于自车坐标系中的静止物体来说,它在T、T-1时刻自车坐标系下的位置偏差可以用(1)式来表示:
![]()
将其从自车坐标系转换到世界坐标系下(左乘一个转换矩阵):
![]()
对T-1时刻的世界坐标系到自车坐标系的转换矩阵在进行一次变换,将其变为T-T-1时刻的自车坐标系自身的转换矩阵和T时刻世界坐标系到T时刻自车坐标系相乘的组合。
![]()
全过程如下:
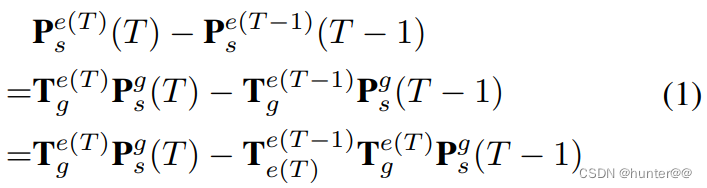
- 在(1)式中,可以看出T和T-1时刻的BEV特征与自我运动高度相关,因此为了消除自我运动的影响,也就是
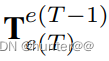 的影响,在(1)式的T-1的BEV特征前左乘一个
的影响,在(1)式的T-1的BEV特征前左乘一个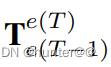 ,这样随着
,这样随着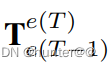 和相乘为0,就消除了自我运动的影响。
和相乘为0,就消除了自我运动的影响。
全过程如下:
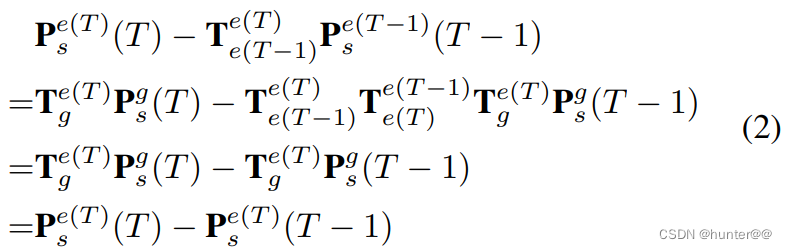
代码
extract_img_feat函数
def extract_img_feat(self,
img, # [[8,12,3,256,704],[8,12,4,4],[8,12,4,4],[8,12,3,3],[8,12,3,3],[8,12,3],[8,4,4]]
img_metas, # box信息
pred_prev=False, # False
sequential=False, # False
**kwargs):
if sequential:
return self.extract_img_feat_sequential(img, kwargs['feat_prev'])
# imgs : [[8,6,3,256,704],[8,6,3,256,704]]
# sensor2keyegos : [[8,6,4,4],[8,6,4,4]]
# ego2globals : [[8,6,4,4],[8,6,4,4]]
# intrins : [[8,6,3,3],[8,6,3,3]]
# post_rots : [[8,6,3,3],[8,6,3,3]]
# post_trans : [[8,6,3],[8,6,3]]
# bda : [8,4,4]
# _ : None
imgs, sensor2keyegos, ego2globals, intrins, post_rots, post_trans, bda, _ = self.prepare_inputs(img)
"""Extract features of images."""
bev_feat_list = []
depth_list = []
key_frame = True
# back propagation for key frame only
# 遍历时刻
for img, sensor2keyego, ego2global, intrin, post_rot, post_tran in zip(imgs, sensor2keyegos, ego2globals, intrins, post_rots, post_trans):
if key_frame or self.with_prev:
if self.align_after_view_transfromation:
sensor2keyego, ego2global = sensor2keyegos[0], ego2globals[0]
# None
mlp_input = self.img_view_transformer.get_mlp_input(sensor2keyegos[0], ego2globals[0], intrin, post_rot, post_tran, bda)
inputs_curr = (img, sensor2keyego, ego2global, intrin, post_rot,post_tran, bda, mlp_input)
if key_frame:
bev_feat, depth = self.prepare_bev_feat(*inputs_curr) # bev_feat:[8,80,128,128] depth:[48,59,16,44]
else:
with torch.no_grad():
bev_feat, depth = self.prepare_bev_feat(*inputs_curr) #
else:
bev_feat = torch.zeros_like(bev_feat_list[0])
depth = None
bev_feat_list.append(bev_feat)
depth_list.append(depth)
key_frame = False
if pred_prev: # False
assert self.align_after_view_transfromation
assert sensor2keyegos[0].shape[0] == 1
feat_prev = torch.cat(bev_feat_list[1:], dim=0)
ego2globals_curr = ego2globals[0].repeat(self.num_frame - 1, 1, 1, 1)
sensor2keyegos_curr = sensor2keyegos[0].repeat(self.num_frame - 1, 1, 1, 1)
ego2globals_prev = torch.cat(ego2globals[1:], dim=0)
sensor2keyegos_prev = torch.cat(sensor2keyegos[1:], dim=0)
bda_curr = bda.repeat(self.num_frame - 1, 1, 1)
return feat_prev, [imgs[0],sensor2keyegos_curr, ego2globals_curr,intrins[0],sensor2keyegos_prev, ego2globals_prev,post_rots[0], post_trans[0],bda_curr]
if self.align_after_view_transfromation: # False
# 是否对齐 前后两帧的 BEV特征。默认情况下,BEV 在视图转换期间,前一帧将对齐。
for adj_id in range(1, self.num_frame):
# bev_feat_list[i] : [8,80,128,128]
bev_feat_list[adj_id] = self.shift_feature(bev_feat_list[adj_id],[sensor2keyegos[0], sensor2keyegos[adj_id]], bda)
bev_feat = torch.cat(bev_feat_list, dim=1) # [8,160,128,128]
x = self.bev_encoder(bev_feat) # [8,256,128,128]
return [x], depth_list[0]self.prepare_inputs函数
def prepare_inputs(self, inputs, stereo=False):
# split the inputs into each frame
B, N, C, H, W = inputs[0].shape # [8,12,3,256,704]
N = N // self.num_frame # 6
imgs = inputs[0].view(B, N, self.num_frame, C, H, W) # [8,6,2,3,256,704]
imgs = torch.split(imgs, 1, 2) # [[8,6,1,3,256,704],[8,6,1,3,256,704]]
imgs = [t.squeeze(2) for t in imgs] # [[8,6,3,256,704],[8,6,3,256,704]]
sensor2egos, ego2globals, intrins, post_rots, post_trans, bda = inputs[1:7]
sensor2egos = sensor2egos.view(B, self.num_frame, N, 4, 4) # [8,2,6,4,4]
ego2globals = ego2globals.view(B, self.num_frame, N, 4, 4) # [8,2,6,4,4]
# calculate the transformation from sweep sensor to key ego
keyego2global = ego2globals[:, 0, 0, ...].unsqueeze(1).unsqueeze(1) # [8,1,1,4,4]
global2keyego = torch.inverse(keyego2global.double()) # [8,1,1,4,4]
sensor2keyegos = global2keyego @ ego2globals.double() @ sensor2egos.double()# [8,2,6,4,4]
sensor2keyegos = sensor2keyegos.float() # [8,2,6,4,4]
curr2adjsensor = None
if stereo:
sensor2egos_cv, ego2globals_cv = sensor2egos, ego2globals
sensor2egos_curr = sensor2egos_cv[:, :self.temporal_frame, ...].double()
ego2globals_curr = ego2globals_cv[:, :self.temporal_frame, ...].double()
sensor2egos_adj = sensor2egos_cv[:, 1:self.temporal_frame + 1, ...].double()
ego2globals_adj = ego2globals_cv[:, 1:self.temporal_frame + 1, ...].double()
curr2adjsensor = torch.inverse(ego2globals_adj @ sensor2egos_adj) @ ego2globals_curr @ sensor2egos_curr
curr2adjsensor = curr2adjsensor.float()
curr2adjsensor = torch.split(curr2adjsensor, 1, 1)
curr2adjsensor = [p.squeeze(1) for p in curr2adjsensor]
curr2adjsensor.extend([None for _ in range(self.extra_ref_frames)])
assert len(curr2adjsensor) == self.num_frame
extra = [
sensor2keyegos, # [8,2,6,4,4]
ego2globals, # [8,2,6,4,4]
intrins.view(B, self.num_frame, N, 3, 3), # [8,2,6,3,3]
post_rots.view(B, self.num_frame, N, 3, 3), # [8,2,6,3,3]
post_trans.view(B, self.num_frame, N, 3) # [8,2,6,3]
]
extra = [torch.split(t, 1, 1) for t in extra] # [[{8,1,6,4,4}、{8,1,6,4,4}]、[....]、[....]、[....]、[....]]
extra = [[p.squeeze(1) for p in t] for t in extra] # [[{8,6,4,4}、{8,6,4,4}]、[...]、[...]、[...]、[...]]
sensor2keyegos, ego2globals, intrins, post_rots, post_trans = extra
return imgs, sensor2keyegos, ego2globals, intrins, post_rots, post_trans, bda, curr2adjsensor
self.prepare_bev_feat函数
def prepare_bev_feat(self, img, rot, tran, intrin, post_rot, post_tran,bda, mlp_input):
x, _ = self.image_encoder(img) # x:[8,6,256,16,44] _:[]
bev_feat, depth = self.img_view_transformer([x, rot, tran, intrin, post_rot, post_tran, bda, mlp_input]) # bev_feat:[8,80,128,128] ,depth:[48,59,16,44]
if self.pre_process:
bev_feat = self.pre_process_net(bev_feat)[0] # [8,80,128,128]
return bev_feat, depth # bev_feat:[8,80,128,128] ,depth:[48,59,16,44]self.shift_feature函数
def shift_feature(self, input, sensor2keyegos, bda, bda_adj=None):
grid = self.gen_grid(input, sensor2keyegos, bda, bda_adj=bda_adj) # [8,128,128,2]
output = F.grid_sample(input, grid.to(input.dtype), align_corners=True) # [8,80,128,128]
return outputself.gen_grid函数
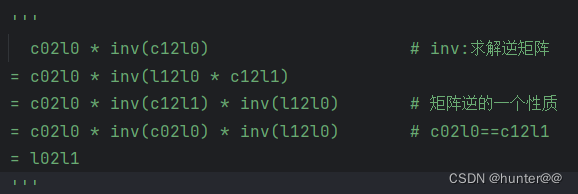
2.2小节讲的特征对齐操作主要体现在这里,sensor2keyegos中保存的是T和T-1时刻的自车到世界坐标系的齐次转换矩阵。通过 c02l0 = sensor2keyegos[0][:, 0:1, :, :] 和 c12l0 = sensor2keyegos[1][:, 0:1, :, :] 分别获取第一个相机的T、T-1时刻的 e->g转换矩阵,再进行 c02l0 * inv(c12l0)。
def gen_grid(self, input, sensor2keyegos, bda, bda_adj=None):
# 主要用于生成或获取一个网格(grid),并根据给定的传感器到关键帧(ego frame)的变换矩阵以及可能的边界框数据增强
#(Bounding Box Data Augmentation, BDA)来计算从一个ego frame到另一个相邻ego frame的变换矩阵。
n, c, h, w = input.shape # [8,80,128,128]
_, v, _, _ = sensor2keyegos[0].shape # [8,6,4,4]
if self.grid is None:
# generate grid
# 生成或获取网络
xs = torch.linspace(0, w - 1, w, dtype=input.dtype,device=input.device).view(1, w).expand(h, w)
ys = torch.linspace(0, h - 1, h, dtype=input.dtype,device=input.device).view(h, 1).expand(h, w)
grid = torch.stack((xs, ys, torch.ones_like(xs)), -1) # [128,128,3]
self.grid = grid # [128,128,3]
else:
grid = self.grid
# 网格拓展
grid = grid.view(1, h, w, 3).expand(n, h, w, 3).view(n, h, w, 3, 1) # [8,128,128,3,1]
# get transformation from current ego frame to adjacent ego frame
# transformation from current camera frame to current ego frame
# 计算变换矩阵
c02l0 = sensor2keyegos[0][:, 0:1, :, :] # [8,1,4,4] 获取第一个相机的第0帧的变换矩阵
# transformation from adjacent camera frame to current ego frame
c12l0 = sensor2keyegos[1][:, 0:1, :, :] # [8,1,4,4] 获取第一个相机的第1帧的变换矩阵
# add bev data augmentation 添加bev数据增强
bda_ = torch.zeros((n, 1, 4, 4), dtype=grid.dtype).to(grid) # [8,1,4,4]
bda = bda.unsqueeze(1) # [8,1,4,4]
bda_[:, :, :3, :3] = bda[:, :, :3, :3] # [8,1,4,4]
bda_[:, :, 3, 3] = 1 # [8,1,4,4]
c02l0 = bda_.matmul(c02l0) # [8,1,4,4]
if bda_adj is not None:
bda_ = torch.zeros((n, 1, 4, 4), dtype=grid.dtype).to(grid)
bda_[:, :, :3, :3] = bda_adj.unsqueeze(1)
bda_[:, :, 3, 3] = 1
c12l0 = bda_.matmul(c12l0) # [8,1,4,4]
# transformation from current ego frame to adjacent ego frame 从当前自我框架到相邻自我框架的转换
l02l1 = c02l0.matmul(torch.inverse(c12l0))[:, 0, :, :].view(n, 1, 1, 4, 4) # [8,1,1,4,4]
'''
c02l0 * inv(c12l0) inv:求解逆矩阵
= c02l0 * inv(l12l0 * c12l1)
= c02l0 * inv(c12l1) * inv(l12l0)
= l02l1 # c02l0==c12l1
'''
l02l1 = l02l1[:, :, :,[True, True, False, True], :][:, :, :, :,[True, True, False, True]] # [8,1,1,3,3]
# 定义一个用来相乘归一化的矩阵feat2bev
feat2bev = torch.zeros((3, 3), dtype=grid.dtype).to(grid) # [3,3]
feat2bev[0, 0] = self.img_view_transformer.grid_interval[0] # 网格间隔的 x 坐标
feat2bev[1, 1] = self.img_view_transformer.grid_interval[1] # 网格间隔的 y 坐标
feat2bev[0, 2] = self.img_view_transformer.grid_lower_bound[0] # 网格下界的 x 坐标
feat2bev[1, 2] = self.img_view_transformer.grid_lower_bound[1] # 网格下界的 y 坐标
feat2bev[2, 2] = 1 # []
feat2bev = feat2bev.view(1, 3, 3) # [1,3,3]
tf = torch.inverse(feat2bev).matmul(l02l1).matmul(feat2bev) # [8,1,1,3,3]
# transform and normalize 归一化
grid = tf.matmul(grid) # [8,128,128,3,1]
normalize_factor = torch.tensor([w - 1.0, h - 1.0],dtype=input.dtype,device=input.device) # [127,127]
grid = grid[:, :, :, :2, 0] / normalize_factor.view(1, 1, 1,2) * 2.0 - 1.0 # [8,128,128,2]
return grid总结
(1)BEVDet4D是在BEVDet的基础上加入了时序特征信息来进一步提高速度预测的精度。
(2)考虑到时序特征会出现错位的问题,引入了特征对齐模块来对齐T、T-1时刻的BEV特征。
参考
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection 论文笔记-CSDN博客
















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









