







目录

更多关于Python的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

公众号:CTO Plus
一个有深度和广度的技术圈,技术总结、分享与交流,我们一起学习。 涉及网络安全、C/C++、Python、Go、大前端、云原生、SRE、SDL、DevSecOps、数据库、中间件、FPGA、架构设计等大厂技术。 每天早上8点10分准时发文。
接下来的一段时间我将总结下关于【Python进阶系列】的一系列开发技术知识点的分享文章,主要为初学者从零基础到进阶再到高级和项目实战,结合目前最新的Python版本3.12来做代码示例的样式,并同时也会标注出与Python2的一些异同点。
原文:Python3基础之经典数据类型字符串(str)开发使用注意事项和使用技巧代码示例详解
然后关于Python的Web开发、爬虫开发、操作系统开发、网络安全开发应用领域这块,可以分别参考我的公众号CTO Plus【Flask进阶系列】、【Django进阶系列】、【DRF进阶系列】、【互联网分布式爬虫系列】和【网络安全系列】的内容,敬请关注,欢迎交流。
![]()
以下是【Python3进阶系列】的部分内容

在Python3中,字符串是一种非常常用的数据类型,它常用于表示文本信息,并提供了丰富的方法和操作符来处理字符串。
同样的除了字符串类型外,以下也是Python3中主要的数据类型,后面的文章我将一一为大家分享一些使用方法和开发技巧:
《Python3基础之经典数据类型字符串(str)开发使用注意事项和使用技巧代码示例详解》
《Python3基础之经典数据类型序列(sequence)的开发使用注意事项和代码示例详解》
《探索Python3中循环对象的迭代与循环:释放数据的魔法》
《Python3基础之经典数据类型列表(list)的开发使用注意事项和代码示例详解》
《Python3基础之经典数据类型元组(tuple)开发使用注意事项和代码示例详解》
《Python3基础之经典数据类型字典(dict)开发使用注意事项和代码示例详解》
《Python3基础之经典数据类型集合(set)开发使用注意事项和代码示例详解》
在本文中,我将为大家详细讨论Python3中字符串的基本操作、字符编码、开发使用技巧和一些需要注意的坑等内容。
字符串类型(str)
字符串是一种由字符组成的序列,它可以存储和操作文本数据。字符串类型用于表示文本数据,可以使用单引号(')、双引号(")、三单引号('''''')或三双引号(""" """)括起来,例如:"SteveRocket"。
在Python中,字符串是不可变的,即不能对字符串进行原地修改,意味着一旦创建就不能被修改。每次对字符串进行操作时,都会生成一个新的字符串。因此,在处理大量字符串时,需要注意内存的占用情况,避免频繁创建大量临时字符串。
代码示例
创建字符串:在Python3中,可以使用单引号、双引号或三引号来创建字符串。例如:
s1 = """ """
s2 = ''
s3 = ""
s4 = ''''''
print(type(s1)) # <class 'str'>
print(type(s2)) # <class 'str'>
print(type(s3)) # <class 'str'>
print(type(s4)) # <class 'str'>
我们使用前面文章《Python3基础之条件判断语句(分支结构)详解》中判断变量类型的方法来输出变量s1、s2、s3、s4的数据类型。
# 定义字符串变量
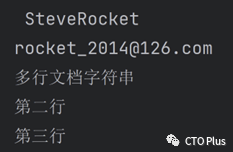
author = " SteveRocket "
email = "rocket_2014@126.com"
print(author)
print(email)
multi_line = """多行文档字符串
第二行
第三行"""
print(multi_line)
输出结果
字符串的基本操作
1. 字符串的+和*操作
在Python3中,字符串可以使用加号(+)来进行拼接,也可以使用乘号(*)来进行重复。例如:
plat = "微信公众号:"
name = "CTO Plus"
# 拼接字符串
new_platform = plat+name
print(len(new_platform), new_platform) # 14 微信公众号:CTO Plus
print(name*5) # CTO PlusCTO PlusCTO PlusCTO PlusCTO Plus
另外,字符串还支持使用索引和切片来访问和操作其中的字符。需要注意的是,Python中的字符串是不可变的,因此对字符串的操作都会返回一个新的字符串。
2. 访问字符串中的字符:可以使用索引来访问字符串中的单个字符,索引从0开始。例如:
platform = "微信公众号:CTO Plus"
print(platform[0]) # 微
print(platform[2]) # 公
print(len(platform)) # 14
3. 字符串切片:可以使用切片操作来获取字符串中的子串。例如:
platform = "微信公众号:CTO Plus"
print(platform[2:5]) # 公众号
print(platform[6:]) # CTO Plus
5. 字符串长度:可以使用len()函数来获取字符串的长度。例如:
email = "rocket_2014@126.com"
print(len(email)) # 19
platform = "微信公众号:CTO Plus"
print(len(platform)) # 14
字符串操作常用相关方法
Python3中的字符串类型提供了丰富的方法来处理字符串,包括大小写转换、查找子串、替换子串、去除空白字符等。例如:
str.split(sep=None, maxsplit=-1)
返回一个字符串中的单词组成的列表,使用sep作为分隔符。maxsplit 设置分隔的数量。如果没有声明maxsplit或者声明maxsplit的值为-1时,没有限制分隔的数量。
platform = " 微信公众号:CTO Plus "
# 生成一个新的字符串 移除字符串左右两边的所有空格
print(f'\"{platform.strip()}\"') #"微信公众号:CTO Plus"
# 原始字符串不变
print(f"\'{platform}\'") #' 微信公众号:CTO Plus '
# 移除字符串左边的所有空格
print(f"\'{platform.lstrip()}\'") # '微信公众号:CTO Plus '
# 移除字符串右边的所有空格
print(f"\'{platform.rstrip()}\'") # ' 微信公众号:CTO Plus'
# 按照空格拆分字符串(从左边开始拆),生成一个列表
print(platform.split()) # ['微信公众号:CTO', 'Plus']
print(platform.split(" ", 1)) # ['', ' 微信公众号:CTO Plus ']
# 按照空格拆分字符串(从右边开始拆),生成一个列表
print(platform.rsplit()) # ['微信公众号:CTO', 'Plus']
print(platform.rsplit(" ", 1)) # [' 微信公众号:CTO Plus ', '']
# 字符串转小写
print(platform.lower()) # 微信公众号:cto plus
# 字符串转大写
print(platform.upper()) # 微信公众号:CTO PLUS
# 判断字符串是否是大写
print(platform.isupper()) # False
# 判断字符串是否是小写
print(platform.islower()) # False
from inner_module_def_datastruct import AUTHOR
author = AUTHOR
print(author) # SteveRocket
print(author.isupper()) # False
print(author.islower()) # False
str.find(sub[, start[, end]])
返回在字符串切片s[start:end]中出现的子字符串sub的第一个最低的索引位置。如果子字符串sub没有被找到,则返回-1。
blog = "https://blog.csdn.net/zhouruifu2015/"
# 查找字符串(从左边开始找)
print(blog.find("o")) # 10
print(blog.find("steverocket")) #未找到返回-1
# 查找字符串(从右边开始找)
print(blog.rfind("o")) # 24
str.replace(old, new[, count])
把字符串中出现的所有old字符串替换成新的字符串new,如果有count,就只替换前count个字符串。
# 字符串替换
print(blog.replace("https","http")) # http://blog.csdn.net/zhouruifu2015/
# 如果要替换的字符串未找到 不会报错 而是原样输出
print(blog.replace("ftp", "http")) # https://blog.csdn.net/zhouruifu2015/
str.join(iterable)
这个可以和str.join(iterable)对应使用。返回一个可迭代的对象中的值组成的字符。str是元素间的间隔。
lis = ["steverocket", "28", "微信公众号:CTO Plus"] # 此处的数字28 必须是字符串的数字
print(" ".join(lis)) # steverocket 28 微信公众号:CTO Plus
字符串处理的方法非常多,比如以下为其他类型的字符串处理方法,下面的可以自行了解下,在需要用到时查一下使用手册即可:
str.count(sub) 返回:sub在str中出现的次数
str.find(sub) 返回:从左开始,查找sub在str中第一次出现的位置。如果str中不包含sub,返回 -1
str.index(sub) 返回:从左开始,查找sub在str中第一次出现的位置。如果str中不包含sub,举出错误
str.rfind(sub) 返回:从右开始,查找sub在str中第一次出现的位置。如果str中不包含sub,返回 -1
str.rindex(sub) 返回:从右开始,查找sub在str中第一次出现的位置。如果str中不包含sub,举出错误
str.isalnum() 返回:True, 如果所有的字符都是字母或数字
str.isalpha() 返回:True,如果所有的字符都是字母
str.isdigit() 返回:True,如果所有的字符都是数字
str.istitle() 返回:True,如果所有的词的首字母都是大写
str.isspace() 返回:True,如果所有的字符都是空格
str.islower() 返回:True,如果所有的字符都是小写字母
str.isupper() 返回:True,如果所有的字符都是大写字母
str.split([sep, [max]]) 返回:从左开始,以空格为分割符(separator),将str分割为多个子字符串,总共分割max次。将所得的子字符串放在一个表中返回。可以str.split(',')的方式使用逗号或者其它分割符
str.rsplit([sep, [max]]) 返回:从右开始,以空格为分割符(separator),将str分割为多个子字符串,总共分割max次。将所得的子字符串放在一个表中返回。可以str.rsplit(',')的方式使用逗号或者其它分割符
str.join(s) 返回:将s中的元素,以str为分割符,合并成为一个字符串。
str.strip([sub]) 返回:去掉字符串开头和结尾的空格。也可以提供参数sub,去掉位于字符串开头和结尾的sub
str.replace(sub, new_sub) 返回:用一个新的字符串new_sub替换str中的sub
str.capitalize() 返回:将str第一个字母大写
str.lower() 返回:将str全部字母改为小写
str.upper() 返回:将str全部字母改为大写
str.swapcase() 返回:将str大写字母改为小写,小写改为大写
str.title() 返回:将str的每个词(以空格分隔)的首字母大写
str.center(width) 返回:长度为width的字符串,将原字符串放入该字符串中心,其它空余位置为空格。
str.ljust(width) 返回:长度为width的字符串,将原字符串左对齐放入该字符串,其它空余位置为空格。
str.rjust(width) 返回:长度为width的字符串,将原字符串右对齐放入该字符串,其它空余位置为空格。
熟练掌握这些字符串方法可以让我们更加高效地处理字符串。
更多关于Python的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

字符串格式化输出
Python3中提供了多种字符串格式化的方式,包括使用百分号(%)、str.format()方法和f-string。其中,f-string是Python3.6引入的一种新的字符串格式化方式,它使用花括号{}和前缀f来表示格式化字符串。接下来我将详细介绍这三种字符串格式化方法。
字符串格式化(%操作符)
Python 支持格式化字符串的输出。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串(或%d的数字)中。在Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。在许多编程语言中都包含有格式化字符串的功能,比如C和Fortran语言中的格式化输入输出。Python中内置有对字符串进行格式化的操作%。
这也是我今天要为大家介绍的第一种字符串格式化:百分号
C/CPP的开发人员对这种字符串格式方式应该是最熟悉的。格式化字符串时,Python使用一个字符串作为模板。模板中有格式符,这些格式符为真实值预留位置,并说明真实数值应该呈现的格式。Python用一个tuple将多个值传递给模板,每个值对应一个格式符。
我们之前讲过,可以用下面的方式来格式化输出字符串。
num1, num2 = 11, 22
print("%s %d + %d = %d" % ("计算两数的和:", num1, num2, num1 + num2)) # 计算两数的和: 11 + 22 = 33
我们还可以用词典来传递真实值。如下:
print("my name is: %(name)s age is: %(age)d" % {"name": AUTHOR, "age": AGE}) # my name is: SteveRocket age is: 25
可以看到,我们对两个格式符进行了命名。命名使用()括起来。每个命名对应词典的一个key。
当然,我们也可以用字符串提供的方法来完成字符串的格式,代码如下所示。
print('计算两数的和:{0} * {1} = {2}'.format(num1, num2, num1 + num2)) # 计算两数的和:11 * 22 = 33
print(f'计算两数的和:{num1} * {num2} = {num1 + num2}') # 计算两数的和:11 * 22 = 33
这样一对比下来,还是f-strings的使用最简洁最方便了吧,后面的章节将详细介绍。
Python 字符串格式化符号:
格式符为真实值预留位置,并控制显示的格式。格式符可以包含有一个类型码,用以控制显示的类型,如下:
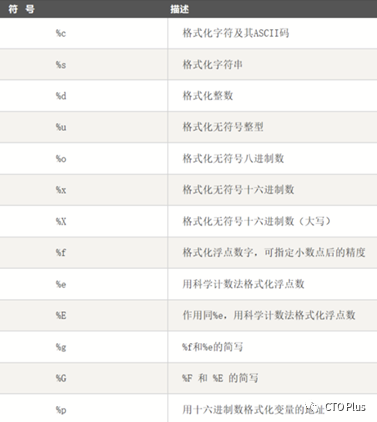
格式化操作符辅助指令:
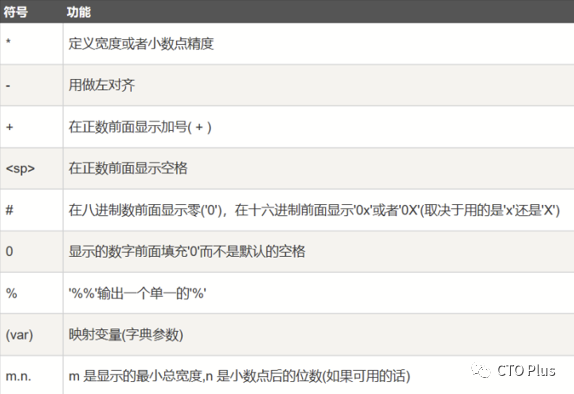
高级使用方法
可以用如下的方式,对格式进行进一步的控制:
%[(name)][flags][width].[precision]typecode
-
(name)为命名
-
flags可以有+,-,' '或0。+表示右对齐。-表示左对齐。' '为一个空格,表示在正数的左侧填充一个空格,从而与负数对齐。0表示使用0填充。
-
width表示显示宽度
-
precision表示小数点后精度
比如:
print("%+10x" % 10) # +a
print("%04d" % 5) # 0005
print("%6.3f" % 2.3) # 2.300
上面的width, precision为两个整数。我们可以利用*,来动态代入这两个量。比如:
print("%.*f" % (4, 1.2)) # 1.2000
Python实际上用4来替换*。所以实际的模板为"%.4f"。
format 格式化函数
接下来介绍下Python的第二种字符串格式化:str.format(args, kwargs)
-
Python2.6开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。基本语法是通过 {} 和 : 来代替以前的%。
-
format 函数用于执行一个格式化字符串操作可以接受不限个参数,位置可以不按顺序。str中可以包含文本字面量和{},{}里面是位置参数的索引或者是关键字参数的名字。
message = "{0} {name}".format(WEIXIN_URL, name=AUTHOR)
print(message) # https://mp.weixin.qq.com/s/0yqGBPbOI6QxHqK17WxU8Q SteveRocket
message = "{0} {0} {name} {name}".format(WEIXIN_URL, name=AUTHOR)
print(message) # https://mp.weixin.qq.com/s/0yqGBPbOI6QxHqK17WxU8Q https://mp.weixin.qq.com/s/0yqGBPbOI6QxHqK17WxU8Q SteveRocket SteveRocket
# 不设置指定位置,按默认顺序
print("{} {}".format(AUTHOR, AGE)) # SteveRocket 25
# 设置指定位置
print("{0} {1}".format(AUTHOR, AGE)) # SteveRocket 25
# 设置指定位置
print("{1} {0}".format(AUTHOR, AGE)) # 25 SteveRocket
同样的我们也可以使用字典来传递值:
print("my name is: {name} age is: {age}".format(name=AUTHOR, age = AGE)) # my name is: SteveRocket age is: 25
# 通过字典设置参数
information = {"name": AUTHOR, "age":AGE, "platform":"微信公众号:CTO Plus"}
print("name name is {name} age is {age} {platform}".format(**information)) # name name is SteveRocket age is 25 微信公众号:CTO Plus
# 通过列表索引设置参数
informations = [AUTHOR, AGE, "微信公众号:CTO Plus"] # 这里如果是set则会报错
print("{0[0]} {0[1]} {0[2]}".format(informations)) # SteveRocket 25 微信公众号:CTO Plus
f-strings而不是format
接下来是分享下目前最新最好用的第三种字符串格式化:f-strings。f-strings格式化的字符串文字写起来更自然,可读性更强,并且是前面提到的选项中最快的。同时,f-strings 被称为文字字符串格式。
如下示例:
from inner_module_def_datastruct import AGE, AUTHOR, WEIXIN_URLprint(f"My name is {AUTHOR}, and I am {AGE} years old. this is my blog {WEIXIN_URL}")# My name is SteveRocket, and I am 25 years old. this is my blog https://mp.weixin.qq.com/s/0yqGBPbOI6QxHqK17WxU8Qdef show():print("函数被调用")return AUTHORprint(f"{show()}:{11+22}") # SteveRocket:33
字符串格式化可以方便地将变量(或表达式或函数等对象)的值插入到字符串中,使得代码更加清晰和易读。
在某些情况下不能使用 f 字符串,比如使用 % 格式的唯一原因是用于记录:
importlogging
things= "something happened..."
logger= logging.getLogger(__name__)
logger.error("Message:%s", things) # 评估内部记录器方法
logger.error(f"Message:{things}") # 立即评估
在上面的示例中,如果你使用 f 字符串,则表达式将立即计算,而使用 C 样式格式,替换将被推迟到实际需要时,这对于消息分组很重要,其中具有相同模板的所有消息都可以记录为一个,这不适用于f字符串,因为模板在传递给记录器之前填充了数据。
还有一种情况是在运行时动态填充模板(即动态格式),这种情况就不适合使用f-strings来动态设置模板及其参数:
def func(tpl: str, param1: str, param2: str) -> str:return tpl.format(param1=param1, param2=param2)some_template = "First template: {param1}, {param2}"another_template = "Other template: {param1} and {param2}"print(func(some_template, "Hello", "CTO Plus")) # First template: Hello, CTO Plusprint(func(another_template, "Hello", "SteveRocket")) # Other template: Hello and SteveRocket# 动态重用具有不同参数的相同模板.inputs = ["公众号:CTO Plus", "SteveRocket", 25]template = "Here's some dynamic value: {value}"for value in inputs:print(template.format(value=value))# Here's some dynamic value: 公众号:CTO Plus# Here's some dynamic value: SteveRocket# Here's some dynamic value: 25
最重要的是,尽可能使用 f 字符串,因为它们更具可读性和更高性能,但请注意,在某些情况下仍然首选和/或需要其他格式样式。
更多关于Python的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

推荐使用现代化字符串格式化方法
但大部分场景,在需要格式化字符串时,推荐使用str.format()或f-strings。
# 不好的使用建议
metric_name = '%s_clsuter_id' % data_id
# 好的使用建议
metric_name = '{}_cluster_id'.format(data_id)
# 更好的使用建议
metric_name = f'{data_id}_cluster_id'
# 当需要重复键入格式化变量名时,使用f-strings。
# 不推荐
"{a}-{b}-{c}-{d}".format(a=a, b=b, c=c, d=d)
# 推荐
f"{a}-{b}-{c}-{d}"
字符串的编码与解码介绍
在Python3中,字符串的编码与解码是一个需要特别注意的问题。Python3中默认的字符串类型是Unicode字符串,Unicode是一种字符集,它包含了世界上几乎所有的字符,每个字符都有一个唯一的编码值。而在进行文件读写、网络传输等操作时,需要进行编码和解码。常见的编码方式除了UTF-8编码外,Python3还支持其他常见的字符编码,如ASCII、UTF-16、GBK等。需要注意字符集的转换,以避免出现乱码等问题。
在Python3中,可以使用encode()和decode()方法来进行字符编码和解码。例如:
str = "微信公众号:CTO Plus"
encoded_str = str.encode('utf-8')
print(encoded_str) # b'\xe5\xbe\xae\xe4\xbf\xa1\xe5\x85\xac\xe4\xbc\x97\xe5\x8f\xb7\xef\xbc\x9aCTO Plus'
decoded_str = encoded_str.decode('utf-8')
print(decoded_str) # 微信公众号:CTO Plus
通过前面的介绍,我们知道字符串的定义是:字符串为引号之间的字符集合,这里引号包括单引号、双引号,三引号(三个连续的单引号或双引号)。
在Python中,字符串前面可以加上u、r、b这三个字符,它们分别代表着不同的字符串类型。下面我们来详细介绍它们的含义:
1. u前缀:在Python2中,u前缀表示Unicode字符串,用于支持Unicode编码的字符串。但在Python3中,所有的字符串都是Unicode字符串,因此u前缀在Python3中已经不再需要或者说不再有特殊含义,因为所有的字符串都默认是Unicode编码的。
2. r前缀:r前缀表示原始字符串(raw string),原始字符串中的转义字符不会被转义。这意味着反斜杠字符\将被视为普通字符而不是转义字符。原始字符串通常用于正则表达式、文件路径等需要保留转义字符的场景。例如:
path = r'C:\Users\username\Documents'
print(path)# 输出C:\Users\username\Documents
r"\n\n\n\n” # 表示一个普通生字符串 \n\n\n\n,而不表示换行
作用:去掉反斜杠的转义机制,常用于正则表达式,对应着re模块。
3. b前缀:b前缀表示字符串是bytes 类型(字节字符串-byte string),字节字符串是以字节为单位进行操作的字符串,适用于处理二进制数据或者与底层C语言交互的情况。在字节字符串中,字符是以ASCII码或者其他指定的字符编码进行存储的,而不是Unicode编码。例如:
byte_str = b'hello' # 表示这是一个 bytes 对象
print(byte_str[0]) # 输出104
在网络编程中,服务器和浏览器只认bytes 类型数据。在 Python3 中,bytes 和str 的互相转换方式是str.encode(‘utf-8’)和bytes.decode(‘utf-8’)。
字符串操作常用方法案例
在Python中,我们还可以通过一系列的方法来完成对字符串的处理,代码如下所示。
str1 = 'hello, world!'
# 通过内置函数len计算字符串的长度
print(len(str1)) # 13
# 获得字符串首字母大写的拷贝
print(str1.capitalize()) # Hello, world!
# 获得字符串每个单词首字母大写的拷贝
print(str1.title()) # Hello, World!
# 获得字符串变大写后的拷贝
print(str1.upper()) # HELLO, WORLD!
# 从字符串中查找子串所在位置
print(str1.find('or')) # 8
print(str1.find('shit')) # -1
# 与find类似但找不到子串时会引发异常
# print(str1.index('or'))
# print(str1.index('shit'))
# 检查字符串是否以指定的字符串开头
print(str1.startswith('He')) # False
print(str1.startswith('hel')) # True
# 检查字符串是否以指定的字符串结尾
print(str1.endswith('!')) # True
# 将字符串以指定的宽度居中并在两侧填充指定的字符
print(str1.center(50, '*'))
# 将字符串以指定的宽度靠右放置左侧填充指定的字符
print(str1.rjust(50, ' '))
str2 = 'abc123456'
# 检查字符串是否由数字构成
print(str2.isdigit()) # False
# 检查字符串是否以字母构成
print(str2.isalpha()) # False
# 检查字符串是否以数字和字母构成
print(str2.isalnum()) # True
str3 = ' rocket_2014@126.com '
print(str3)
# 获得字符串修剪左右两侧空格之后的拷贝
print(str3.strip())
案例:下标运算和切片操作
在Python3中,字符串的下标运算和切片操作可以通过一些高级技巧来实现更灵活的操作。下面介绍一些常用的高级使用技巧:
1. 负数索引:可以使用负数索引来从字符串末尾开始访问字符,例如-1表示倒数第一个字符,-2表示倒数第二个字符,依此类推。例如:
msg = "欢迎关注公众号:CTO Plus"
print(msg[-1]) # 输出s
print(msg[-2]) # 输出u
2. 切片步长:除了基本的切片操作,还可以指定切片的步长。例如,使用`[start:end:step]`的形式来指定步长。例如:
msg = "欢迎关注公众号:CTO Plus"
print(msg[1:3]) # 迎关
print(msg[0:3:2]) # 欢关
3. 反转字符串:可以使用步长为-1的切片操作来反转字符串。例如:
msg = "欢迎关注公众号:CTO Plus"
print(msg[::-1]) # sulP OTC:号众公注关迎欢
更多关于Python的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

总结
总之,字符串在Python3中是一个非常重要的数据类型,它提供了丰富的操作和方法来处理文本信息。在使用字符串时,我们需要注意一些技巧和避免一些坑,以保证程序的正确性和性能。同时,Python3提供了丰富的字符串操作功能和字符编码支持,使得处理字符串变得非常方便。在实际开发中,我们可以灵活运用这些功能来处理各种字符串操作和字符编码的需求。
除了字符串,Python还内置了多种类型的数据结构,如果要在程序中保存和操作数据,绝大多数时候可以利用现有的数据结构来实现,最常用的包括列表、元组、集合和字典,后面的文章将详细介绍:
《Python3基础之经典数据类型列表(list)的开发使用注意事项和代码示例详解》
《Python3基础之经典数据类型元组(tuple)开发使用注意事项和代码示例详解》
《Python3基础之经典数据类型字典(dict)开发使用注意事项和代码示例详解》
《Python3基础之经典数据类型集合(set)开发使用注意事项和代码示例详解》
希望本文能够帮助大家更好地理解和使用Python3中的字符串。
Python专栏
https://blog.csdn.net/zhouruifu2015/category_5742543
欢迎关注公众号CTO Plus,有问题欢迎后台留言交流。
更多精彩,关注我公号,一起学习、成长

CTO Plus
一个有深度和广度的技术圈,技术总结、分享与交流,我们一起学习。 涉及网络安全、C/C++、Python、Go、大前端、云原生、SRE、SDL、DevSecOps、数据库、中间件、FPGA、架构设计等大厂技术。 每天早上8点10分准时发文。
公众号
标准库系列-推荐阅读:
推荐阅读:
最后,不少粉丝后台留言问加技术交流群,之前也一直没弄,所以为满足粉丝需求,现建立了一个关于Python相关的技术交流群,加群验证方式必须为本公众号的粉丝,群号如下:

















 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











