







目录
GNU Linker 链接器(ld)是用于将程序目标文件(.o)组合在一起,生成可执行目标文件的过程;官方针对 ld 的说明有专门的文档介绍:
Using ld
有兴趣的朋友可以网上搜索一下看看;
1、铺垫
链接,是生成可执行文件的最后一步,为了更好的描述后面的内容,这里想先做一些简单的铺垫内容;
程序代码(.s 和 .c)源文件会经过预编译、编译、汇编、链接最后生成目标可执行文件;
下面简单的说一下这几个过程,以便更好的进行下面的内容;
1.1、预编译
程序的预编译阶段,只对程序进行文本处理,进行一些变量的替换操作,简单的说,就是如果你定义了一个宏:
#define SRAM_BASE_ADDR 0x20000000那么在所有用到这个宏的地方,在预编译阶段,会直接进行文本替换,形成下一级编译的输入;
值得一提的是,编译器支持很多预定义的关键字,在预编译阶段,都会进行直接文本替换行为;比如:
- __FILE__
- __LINE__
- __DATE__
- __TIME__
- __STDC__
- #define
- #include
- 条件编译 #if、#elif、#else、#ifdef、#ifndef、#endif
使用 gcc 编译的时候,导入一个宏定义,使用 -D 命令,比如:
-DSRAM_BASE_ADDR不导入某个宏使用 -U
-USRAM_BASE_ADDR使用 gcc,手动执行这一步的方法为:
gcc -E hello.c -o hello.i
或者
cpp hello.c > hello.i1.2、编译
预编译结束后,就开始编译,编译过程就是把预处理完的文件进行一系列词法分析,语法分析,语义分析,优化后生成相应的汇编代码文件;这一步会将预编译后的内容,翻译成为和 CPU 体系架构相关的汇编代码;
可以手动执行:
gcc -S hello.i -o hello.s1.3、汇编
汇编器是将汇编代码转变为机器可执行指令,每一汇编语句几乎对应一条机器指令;
可以使用 gcc -c 或者 as 汇编器 -o 来生成 .o 目标文件;生成的目标文件是二进制文件;
gcc -c hello.s -o hello.o
或者
as hello.s -o hello.o1.4、链接
将目标文件 .o 通过 ld 链接器和链接脚本的描述,进行重定向生成可执行二进制文件;总体的过程大致如下所示:
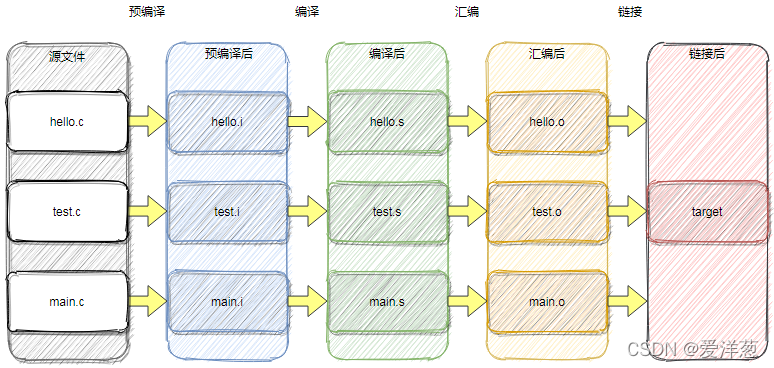
针对链接部分呢,稍微展开说一些内容,如上面所示,最后的 target 文件,由 hello.o、test.o 和 main.o 通过链接得来;这个过程叫做 静态链接;与之对应的还有一个叫 动态链接,动态链接还需要装载器参与,现在仅仅讨论静态链接;
从宏观的角度上来讲,可执行文件中,都包含很多 符号(函数和变量),这些符号在编译链接完成后,地址都是唯一并且固定的;
说明:这里指的地址,是逻辑地址;因为不同 CPU 和操作系统上,对地址的定义有所区别,比如 Cortex-M 的处理器 上,访问的都是物理地址,所以 ”地址“ 在这种 CPU 上的含义就是实实在在的物理地址;
而在比如 Cortex-A 的处理器上,链接器所指定的地址,是虚拟地址,不是真正的物理地址;
在链接之前,这些符号都是单独存在于每一个 .o 文件中的,所以链接器的第一个任务就是需要给这些个 .o 里面的符号揉在一起,并且指定地址,也就是为这些符号做 Layout;
通常情况下,我们将符号们进行分类,分为代码和数据,这两大类,对于数据呢,进一步分为三类:未初始化的全局数据、读写数据段和只读数据段;
Text :代码段,里面包含的是代码部分;
RW Data:读写数据段,已经初始化的全局变量和静态变量;
RO Data:只读数据段,被 const 修饰的数据段或者字符串;
BSS:未初始化的全局变量;
当然,还有一些其他的段,用于别的用处,这里只列举出了必须的部分;
符号就符号,为啥不能揉在一起,却要分这么多类型呢?
针对 Text 段(代码段)是 Read Only 的(不要问我为什么),和数据(数据在程序运行中,可以修改)的属性不一样,在某些场景下 Text 段可能会 Layout 到不同的地方(比如系统有可以片上运行代码的 Flash ,那么代码段可以放置到 Flash 的地址上,如果系统没有片上可以运行代码的 Flash,代码只能放置在 RAM 里面运行);
针对数据,分为了 Read Only,Read Write,和一个 BSS;首先,你想,代码里面,已经被初始化了的全局变量,它是不是已经有值了?这个值是不是应该随着我们编译,一起打包到二进制文件中?明显是需要的;如果这些值不随着二进制被打包,那么你定义的初值不就没了吗?所以,RO/RW 变量有必要和 BSS 区分,并且数据打包进入二进制;
好的,那 BSS 呢?本身就是未被初始化的全局变量,我们认为他初值就是 0,数据是什么,数据就是 ”地址和地址里面的值“,所以针对 BSS,我们是没有必要将其打包到二进制,只需要告诉我 BSS 的地址,我在使用这些地址之前,去把他们写 0 就好了;
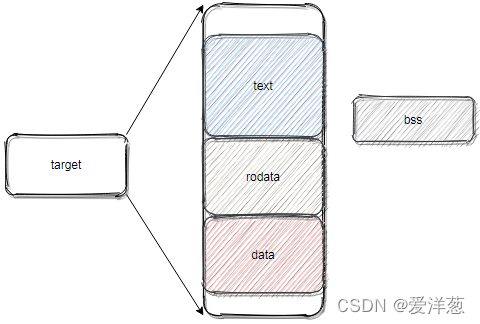
好了,交代了太多额外的东西,回来继续讲链接;链接需要组织每个 .o 文件中的符号,把这些个玩意揉成一个目标二进制文件;
每个 .o 文件中的符号,没有分配地址,也分配不了地址(因为还没链接嘛),可以理解为,只是标记了段和内容;等到链接的时候,再交给链接器来统领;
多个 .o 都各自有各自的 .text、.data、rodata、bss 等,链接器把他们揉在一起的时候,是将每个 .o 的 text 放一起,data放一起,rodata放一起,这样存放的;
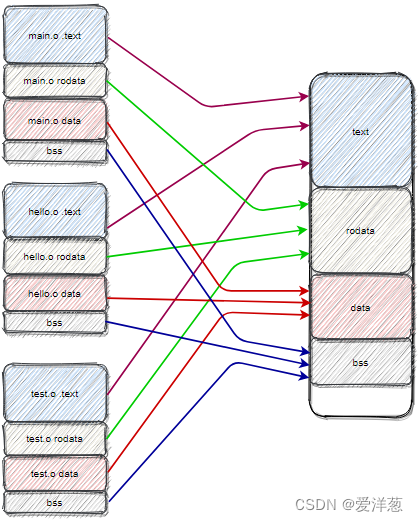
放置完毕后,赋予他们地址信息;
还有一件事,需要记得,比如上面那个例子,3个源文件,分别编译成为 3个 .o 文件,那么如果一个文件调用了另一个文件的函数,或者引用了另一个文件的变量,这种情况怎么处理呢?事实上,编译器只负责了语法和词法解析,这种跨文件的函数或者变量引用,最终由链接器在链接多个 .o 的时候,再最终确定,也就是编译器把这部分活儿甩给了链接器,自己只打个标记在这;所以呢,链接器还要做一件事,就是符号解析;
所以呢,看起来,链接器需要做至少如下几件事:
- 符号解析;
- 空间和地址指定;
- 重定位;
这里多啰嗦两句,链接器将 .o 组织,链接起来后的地址,我们叫做链接地址;针对静态链接而言(链接多个 .o 并生成可执行文件 elf),链接地址就是程序的运行地址;
还有一个概念叫做加载地址,加载地址指的是你的可执行二进制程序放的位置;我们举两个例子来说说:
嵌入式设备中,存储介质分为 Flash 和 RAM,Flash 掉电非易失,可以用来存储我们的程序;而需要频繁修改的数据,则放到 RAM 里面;
Flash 呢,又有很多类别,有的 Flash 可以随机访问,这样的特性意味着我们可以直接在 Flash 上跑代码(比如 NOR Flash),有的 Flash 呢,只能够支持基于 Block/Sector/Page 这样的方式访问(比如 Nand Flash,eMMC),我们可以将代码放到这种 Flash 上,启动的时候,把代码拷贝到 RAM(或者叫 DDR)中去运行;
第一种情况,Flash 上可以跑代码的情况,我们可以将代码段 Layout 到 Flash 的地址空间上去,数据段 Layout 到 RAM 的地址空间上;此刻,代码的加载地址就等于运行地址;
第二种情况,Flash 上的代码被拷贝到内存中去跑,那么代码的加载地址指的是 CPU 视角上,Flash 的地址空间,运行地址是内存地址空间;
也就是说,链接地址就是实际的程序运行地址,加载地址指的是程序被运行之前,被放置的位置的地址;
2、GNU ld
GNU 使用 ld 来处理链接过程;
2.1、binutils
GNU 的 ld 隶属于一个叫 binutils 的工具集,这个工具是 GNU 的二进制工具集;从命名上来看,就可以知道,这些工具的目的是用于操作二进制文件的,而不是针对于文本或者源代码;
官方的链接为:
binutils 工具集中还包含了很多二进制工具,其中最重要的要数:
- ld - the GNU linker.
- as - the GNU assembler.
还有很多其他的工具,包括:
- addr2line - Converts addresses into filenames and line numbers.
- ar - A utility for creating, modifying and extracting from archives.
- c++filt - Filter to demangle encoded C++ symbols.
- dlltool - Creates files for building and using DLLs.
- gold - A new, faster, ELF only linker, still in beta test.
- gprof - Displays profiling information.
- nlmconv - Converts object code into an NLM.
- nm - Lists symbols from object files.
- objcopy - Copies and translates object files.
- objdump - Displays information from object files.
- ranlib - Generates an index to the contents of an archive.
- readelf - Displays information from any ELF format object file.
- size - Lists the section sizes of an object or archive file.
- strings - Lists printable strings from files.
- strip - Discards symbols.
- windmc - A Windows compatible message compiler.
- windres - A compiler for Windows resource files.
这里,咱们聚焦到 ld 这个玩意本身来;ld 支持将多个 .o 和一个链接脚本作为输入;链接脚本(Linker Script)中描述这个目标二进制文件的 layout 规则;
简单情况下,使用 ld 的方式如下:
ld test.o main.o hello.o -o main2.2、Linker script
当然,上面看起来,ld 将 3 个 .o 文件链接后,成为了一个 main 可执行文件,事实上,这儿还有一个隐藏的输入,就是链接脚本,链接脚本确定了链接器以何种方式将文件进行链接;如果不指定,那么会使用系统默认的链接脚本,当然,也可以手动指定他:
ld -T <file>一般情况下,我们会吧这个链接脚本命名为 xxx.lds,即,以 .lds 结尾;
链接脚本中,需要描述一些啥信息呢?主要是各个段的地址 Layout;
2.2.1、基本语法
GNU 官方针对链接脚本的语法,大致做了如下描述:
SECTIONS
{
...
secname start BLOCK(align)(NOLOAD) : AT(ldadr)
{ contents } >region :phdr =fill
...
}其中:
SECTIONS:是链接脚本的关键字,代表这开始描述段了;
secname:段名,一般使用数据段.data 段,代码段.text 段等等;
start:表示本段链接(或者称为运行)的地址,如果没有使用AT(ldadr),本段存储的地址也是start,也就是说存储地址与运行地址相等;
AT(ldadr):AT 是关键字,ldadr 表示该段存储地址,也就是加载地址;
contents:表示目标文件(比如.o目标文件)中的哪些段放在本段,也可以是整个目标文件全部放在这个段内
比如:
SECTIONS
{
...
.text 0x30000 : AT ( 0x0000 )
{ *(.text) }
.data 0x3FFFF : AT ( 0xFFFF )
{ *(.data) }
...
}固件的代码段的存储地址为0,数据段存储地址为0xFFFF,而运行地址分别为0x30000和0x3FFFF;
链接脚本还可以简单的写成:
SECTIONS
{
.=0x1000;
.text:{*(.text)}
.=0x8000000;
.data:{*(.data)}
.bss:{*(.bss)}
}这个代表了,首先,当前地址从 0x1000 开始,放置 text 段,然后从 0x8000000 开始放置 .data;
2.2.2、定义入口 ENTRY
我们在组织多个 .o 的 text 段的时候,哪个段文件的哪个函数放到最前面呢?
程序执行的第一条指令被称为程序的入口,这个入口通常就是在链接脚本指定的,链接脚本中的 ENTRY() 命令可以指定入口地址,关于程序入口地址的指定规则和优先级依次是这样的(优先级从高到低):
- 命令行通过 -e entry 指令入口地址为 entry,这个 entry 可以是一个符号。
- 链接脚本中的 ENTRY(symbol) 命令,这个 symbol 是一个符号
- 如果程序中定义了 start 符号,以这个符号作为入口地址
- .text 段的起始地址
- CPU 的 0 地址处开始
2.2.3、定义 MEMORY
可以在链接脚本中,使用 MEMORY 定义内存区域:
MEMORY
{
NAME [(ATTR)] : ORIGIN = ORIGIN, LENGTH = LEN
...
}
其中:
NAME:是用在连接脚本中引用内存区域的名字。出了连接脚本,区域名就没有任何实际意义。区域名存储在一个
单独的名字空间中,它不会和符号名,文件名,节名产生冲突,每一块内存区域必须有一个唯一的名字。
ATTR:字符串是一个可选的属性列表,它指出是否为一个没有在连接脚本中进行显式映射地输入段使用一个特定
的内存区域。如果你没有为某些输入段指定一个输出段,连接器会创建一个跟输入段同名的输出段。如果你定
义了区域属性,连接器会使用它们来为它创建的输出段选择内存区域。
ATTR 字符串必须包含下面字符中的一个:
- 'R':只读段
- 'W':读写段
- 'X':可执行段
- 'A':需要分配内存的段
- 'I','L':初始化段
- '!':和上述的属性合并使用,表示反转给出的属性
ORIGIN:表示区域的开始地址,也可以写成 org 或者 o,
LENGTH :表示区域的长度.,也可以写成 len 或者 l,
基于内存区域定义后的链接脚本可以写成:
MEMORY
{
rom (rx) : ORIGIN = 0, LENGTH = 256K
ram (!rx) : org = 0x40000000, l = 4M
}
SECTIONS
{
. = 0x80000000;
.text : { *(.text) } > rom
.data : { *(.data) } > ram
.bss : { *(.bss) }
}在上述示例中,定义了两个内存区域,rom 区域从 0 开始,占据 256K 字节,而 ram 区域从 0x40000000 开始,占用 4M 空间;
而输出段 .text 指定放在 rom 中, .data 放在 ram 区域, .bss 没有指定,但是由于 .bss 段的属性是 'w' 类型的,所以匹配的区域是 ram,被放在 .data 随后的地址处.
而地址定位符的赋值语句 ". = 0x80000000;" 会被忽略,编译完成之后可以通过 readelf -S 命令查看输出文件,可以看到各个段对应的虚拟地址.
2.2.4、定义 MEMORY 别名
上面定义了内存区域,ld 支持定义内存区域的别名,语法为;
REGION_ALIAS(alias, region)比如我们定义一个文件叫做:linkcmds.memory,他的内容我们定义为:
MEMORY
{
RAM : ORIGIN = 0, LENGTH = 4M
}
REGION_ALIAS("REGION_TEXT", RAM);
REGION_ALIAS("REGION_RODATA", RAM);
REGION_ALIAS("REGION_DATA", RAM);
REGION_ALIAS("REGION_BSS", RAM);
这个里面,我们定义了一个内存区域,叫做 RAM,使用 REGION_ALIAS 定了 4 个别名:
REGION_TEXT、REGION_RODATA、REGION_DATA、REGION_BSS;
在链接脚本中,我们这样引用这别名:
INCLUDE linkcmds.memory
SECTIONS
{
.text :
{
*(.text)
} > REGION_TEXT
.rodata :
{
*(.rodata)
rodata_end = .;
} > REGION_RODATA
.data : AT (rodata_end)
{
data_start = .;
*(.data)
} > REGION_DATA
data_size = SIZEOF(.data);
data_load_start = LOADADDR(.data);
.bss :
{
*(.bss)
} > REGION_BSS
}
这样做有什么好处呢?可以使得我们的链接脚本更加健壮!
上面的定义,事实上,所有的东西都被 Layout 到 RAM 中;试想一下,如果是另外一个系统,带 ROM(或者是 Flash)的,并且 ROM (可以片上跑代码)我们希望代码放到 ROM 上,岂不是又要改这个链接脚本?
如果使用这种方式,就不用,直接改这个存储描述文件为:
MEMORY
{
ROM : ORIGIN = 0, LENGTH = 3M
RAM : ORIGIN = 0x10000000, LENGTH = 1M
}
REGION_ALIAS("REGION_TEXT", ROM);
REGION_ALIAS("REGION_RODATA", ROM);
REGION_ALIAS("REGION_DATA", RAM);
REGION_ALIAS("REGION_BSS", RAM);
看明白了吧,类似于你在 C 代码中使用宏!
甚至于,在你今后系统升级后,硬件变化了,多了一个 ROM 区域,你也可以仅仅更新这个内存分布文件:
MEMORY
{
ROM : ORIGIN = 0, LENGTH = 2M
ROM2 : ORIGIN = 0x10000000, LENGTH = 1M
RAM : ORIGIN = 0x20000000, LENGTH = 1M
}
REGION_ALIAS("REGION_TEXT", ROM);
REGION_ALIAS("REGION_RODATA", ROM2);
REGION_ALIAS("REGION_DATA", RAM);
REGION_ALIAS("REGION_BSS", RAM);
2.2.5、定义文件格式
有两个链接器脚本命令可以用来处理对象文件格式:
OUTPUT_FORMAT(bfdname)
OUTPUT_FORMAT(default, big, little)
OUTPUT_FORMAT 命令使用BFD格式的命名方式(请参见BFD)。使用 OUTPUT_FORMAT(bfdname) 与在命令行上使用 ‘–oformat bfdname ’ 完全相同。如果两者都使用,则命令行选项优先。
当该命令只有一个参数时,直接指定文件格式,当命令带三个参数时,分别表示:默认格式,指定输出文件为大端时的格式,指定输出文件为小端时的格式;
2.2.6、定义输出文件的架构
OUTPUT_ARCH 用于指定输出架构;
2.2.7、对齐
使用 ALIGN 来表示对齐操作:比如
.text ALIGN(0x10) : { *(.text) }
2.2.8、其他
链接脚本中,还有很多很多其他的关键字和用法,这里也没法全不列举出,有兴趣的朋友可以自行读一下官方的文档,或者也可以看下这个老哥的链接:
2.3、例子
我们以一个 ARM 平台的 u-boot 为例子:
/*
* January 2004 - Changed to support H4 device
* Copyright (c) 2004-2008 Texas Instruments
*
* (C) Copyright 2002
* Gary Jennejohn, DENX Software Engineering, <garyj@denx.de>
*
* See file CREDITS for list of people who contributed to this
* project.
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License as
* published by the Free Software Foundation; either version 2 of
* the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place, Suite 330, Boston,
* MA 02111-1307 USA
*/
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm")
OUTPUT_ARCH(arm)
ENTRY(_start)
SECTIONS
{
. = 0x00000000;
. = ALIGN(4);
.text :
{
cpu/arm_cortexa9/start.o (.text)
cpu/arm_cortexa9/s5pc210/cpu_init.o (.text)
board/samsung/smdkc210/lowlevel_init.o (.text)
common/ace_sha1.o (.text)
*(.text)
}
. = ALIGN(4);
.rodata : { *(SORT_BY_ALIGNMENT(SORT_BY_NAME(.rodata*))) }
. = ALIGN(4);
.data : { *(.data) }
. = ALIGN(4);
.got : { *(.got) }
__u_boot_cmd_start = .;
.u_boot_cmd : { *(.u_boot_cmd) }
__u_boot_cmd_end = .;
. = ALIGN(4);
__bss_start = .;
.bss : { *(.bss) }
_end = .;
}
3、ld 命令和参数
ld 命令支持带很多参数:
ld --help 可以查看所有的链接器参数,下面我们就来介绍几个比较常用的链接参数:
- -T:-T 参数表示指定链接脚本,用户可以通过 ld -T file 来指定使用自己的链接脚本,而不使用系统默认的,在一些特殊的场景中适用。
- @file: 从文件中读取命令行参数,而不是手动指定,通常在脚本编程时使用这种做法。
- -e entry、--entry=entry:这两个命令是同等效果,显示地指定程序开始的位置,通常情况下,需要指定程序内部的符号,如果给定的参数不是一个符号,链接器会尝试将参数解析成数字,表示从指定的地址开始执行程序。
- -EB、-EL:指定大小端,这会覆盖掉系统默认的大小端设置。
- -L、--library-path=searchdir:指定搜索的目录
- -l :链接指定的库,库名通常是 libname.a 或者 libname.so,使用该参数时去掉库的前后缀,即 -lname
- -o output、--output=output:指定输出文件名
- -s、--strip-all:丢弃可执行文件中的符号,以减小尺寸。
- -static:不使用动态库,静态地链接
- -nostdlib:默认情况下链接标准库,该参数显示地指明不链接标准库。
- -shared:创建一个动态库
当然,也可以通过 -T 来单独为不同的段指定地址,比如:
-Ttext <startaddr>
-Tdata <startaddr>
-Tbss <startaddr>这样的话,会覆盖链接脚本中定义的值;
同样情况,ld 命令行的很多命令,都会覆盖链接脚本中指定的内容,比如你链接脚本中定义了 ENTRY 入口,但是呢,你 ld 也使用 -e ,那么 ld 会优先使用你命令行的参数,而不用你链接脚本中通过 ENTRY 定义的值;

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









