







一、什么是分布式锁?
分布式锁是控制分布式系统或不同系统之间共同访问共享资源的一种锁实现,如果不同的系统或同一个系统的不同主机之间共享了某个资源时,往往需要互斥来防止彼此干扰来保证一致性。
二、分布式锁需要解决的问题
1、互斥性:任意时刻,只能有一个客户端获取锁,不能同时有两个客户端获取到锁。
2、安全性:锁只能被持有该锁的客户端删除,不能由其它客户端删除。
3、死锁:获取锁的客户端因为某些原因(如down机等)而未能释放锁,其它客户端再也无法获取到该锁。
4、容错:当部分节点(redis节点等)down机时,客户端仍然能够获取锁和释放锁。
三、常见的分布式锁方案
3.1 数据库唯一性索引
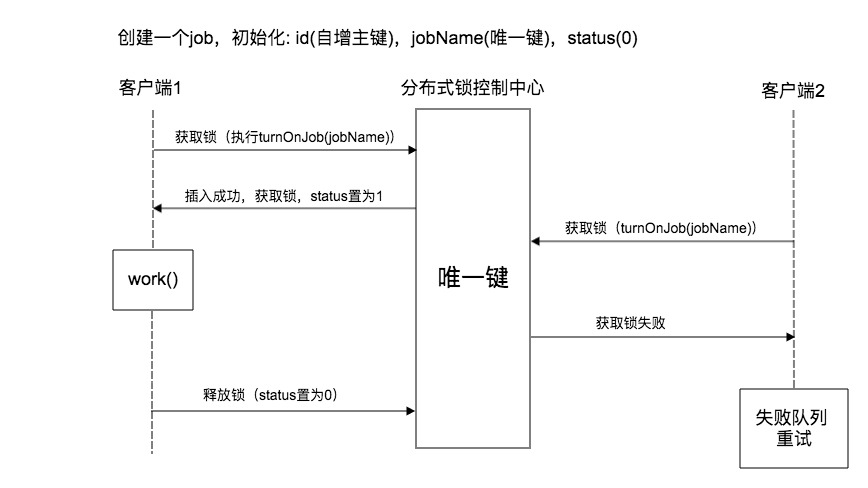
3.1.1 方案流程
(1)创建一个job,初始化: id(自增主键),jobName(唯一键),status(0)
(2)客户端1执行turnOnJob(jobName)请求锁,
(3)当前status=0,获得锁成功,将status置为1
(4)客户端1进行业务处理
(5)客户端2执行turnOnJob(jobName)请求锁
(6)当前status=1,获得锁失败
(7)客户端2捕获得到锁失败,进入重试队列,由重试作业来进行下次锁的获取已及业务逻辑的处理。
3.1.2 方案解决问题
(1)互斥性:利用数据库的唯一性索引,使得锁不会由两个客户端在同一时刻获得锁。
(2)安全性:数据库插入成功后,会将status置为1,并只会在业务执行完之后才会将status置为0。所以其他客户端是无法删除客户端所持有的锁的。
(3)死锁:由于一些异常情况(重启)使得锁没有释放,这样会导致死锁,通过设置过期时间机制,来避免这种异常死锁。通过一个Job,定时的清除已经过期的锁,过期条件:Math.floor(|Now-CreatedTime|)>ExpiredTime
(4)容错:利用数据库主从来进行容错的处理。主节点发生故障时,从节点切换成主节点,从而不影响分布式锁服务的运行。
3.1.3 方案优势
(1)轻量级:可以快速实现分布式锁的功能,快速上线。
3.1.4 方案不足
(1)由于需要不断的读写数据库,系统开销比较大,依赖数据库的性能,对数据库有一定程度的影响。对于小并发的场景下满足要求,但是在大并发或者在分布式集群下可能会有性能问题。
(2)跟数据库的某些特性耦合的太紧,首先是不同的数据库会有不同的特性,其次数据库的连接等都是紧俏的资源,没有针对分布式锁这种场景做特殊定制和优化。
3.2 Zookeeper分布式锁
链接:http://zookeeper.apache.org/doc/trunk/recipes.html
3.1.1 ZK实现分布式锁的优势
分布式系统在某些场景下,必须对客户端请求确定顺序、分清主次,因为有些资源在同一时间只允许被一个进程/线程处理,这时就需要分布式锁。利用分布式锁能保证数据一致性,避免出现负库存、撞单等错误。
虽然很多数据库都提供了锁的功能,但是DB锁的效率极低,而且在高并发下把压力都堆到DB上显然是极其危险的行为,在应用层实现分布式锁可以有效的减轻DB的压力,从而提高系统的稳定性和可用性。
zk主要是用来提供分布式一致性的,所以很自然的想到利用zk来实现分布式锁。因为分布式锁是应用在高并发场景下的(低并发场景也需要锁,但不需要分布式),分布式+高并发自然地要引入集群,锁就存在于集群内的各个节点上,分布式锁在逻辑上只有一把,但物理上存在多把,必须保证各节点上同一把锁的状态一致,这正是分布式一致性算法要做的事。
3.1.2 实现原理
zk实现分布式锁是利用对节点的操作来进行的,锁操作主要涉及加锁和解锁,对应到zk里,加锁就是创建节点(临时节点),解锁就是删除节点,所有客户端都在同一父节点下进行加锁和解锁操作。具体实现思路有以下两种:
一、单节点锁
以某一固定节点为锁,所有客户端争抢这个节点,抢到即为加锁成功。
(1)某个client加锁时,先尝试创建这个节点,如果创建成功,说明该节点不存在,即当前无锁,此client获得锁;
(2)如果创建失败,说明该节点已存在,即有其它client已获得锁,此client阻塞(等待节点删除的通知)或循环重试;
(3)client获得锁并执行完业务逻辑后,删除该节点(即解锁),zk通知其它client(唤醒阻塞或跳出重试循环)。
二、多节点锁
在单节点锁中,所有client操作同一节点,当持有锁的client释放琐时,其它所有client都从阻塞中唤醒,将以竞争的方式来争抢锁,谁先获得锁取决于各client的网络状况和zk集群节点的cpu调度等不可控因素,和client的先来后到完全无关。如果希望各client能按先后顺序(至少在网络差异不大的情况下)来获得锁,就需要多节点锁来实现,即每个客户端创建自己的专属节点(所有节点在同一父节点下),在满足特定条件时,自己的节点会成为锁。
zk有三种节点:永久节点、临时节点和顺序节点,可以组合成四种节点类型(永久、临时、永久顺序和临时顺序),为了实现先进先出的功能(先加锁的先获得锁),选择临时顺序节点来充当锁的角色。临时节点的特点是当会话失效时节点会被zk自动清除,顺序节点的特点是zk会为节点加上一个递增的序号作为后缀,序号按节点创建时间的先后顺序递增。基本原理如下:
(1)某个client尝试加锁时,直接创建一个顺序节点;
(2)load出父节点下的所有子节点(getChildren),判断刚才的节点序号是否最小,如果最小则表示当前client是第一个尝试加锁的,它将获得锁,如果不是最小则阻塞;
(3)获得锁并执行完业务逻辑后,删除自己创建的节点,zk通知其它client;
(4)从阻塞中唤醒后,执行2中的操作
3.1.3 死锁
分布式锁中的死锁,不是指多线程中的无线回路等待,而是指出现一个“幽灵锁”,这把锁在被创建后就和加锁者失去联系,加锁者也不知道自己创建过这把锁,当然也就无法对其进行解锁,进而导致其它client无法获得锁。有两种典型场景:
(1)client发送创建节点的请求后因异常(如网络故障)和zk断开连接,zk服务端接收到请求并成功创建节点,这个节点就成为一个“幽灵节点”,它不与任何client关联,无法释放(可以设置失效时间,通过定时任务来清理,但显然增加了系统的复杂度)。
(2)client创建节点成功后,在做业务逻辑的过程中出现异常,和zk断开连接,未能执行解锁操作。
在单节点锁和多节点锁中,应对死锁的方案有所不同,但核心思想都是重试+校验。重试就是client在异常断开后发起重试,再次尝试加锁,直到成功为止(无限重试),校验就是在创建节点前先检查当前节点(如果存在)是否是自己之前创建的。
具体来说,对于单节点锁,可以把client的私有信息(如ip)写入节点关联的字符串,每次加锁前先比较当前节点字符串中的信息是否和自己匹配,如果匹配就表示当前节点是自己之前创建的,直接视为加锁成功。对于多节点锁,每个client持有一个唯一ID(比如java的uuid),将此ID作为节点名称的前缀,也就是用于判断节点归属的依据,每次创建节点前先load出父节点下的所有子节点,遍历子节点列表判断每个子节点名称中是否包含此id,如果包含说明这个子节点就是自己之前创建的,然后才判断序号是否最小。
3.1.4 代码实现
一、单节点锁实现

/** * 单节点分布式锁 */ public class SingleNodeLock { private String clientId; private String nodeName; private ZKClient zkClient; //锁节点全路径名称 private static final String LOCK_NAME = "/zk/lock/publiclock"; public SingleNodeLock() throws Exception { clientId = UUID.randomUUID().toString().replaceAll("-", "") + "-"; zkClient = new ZKClient(); } /** * 加锁 * @return */ public boolean lock() { //先尝试获取现有锁节点数据 String lockInfo = zkClient.getData(LOCK_NAME); if ("nonode".equals(lockInfo)) { System.out.println("当前无锁," + clientId + "尝试加锁"); //节点不存在(即无锁),当前客户端可以尝试加锁(即创建节点) String lockNode = zkClient.Create(LOCK_NAME, clientId, CreateMode.PERSISTENT); if (LOCK_NAME.equals(lockNode)) { //创建节点成功即加锁成功 setNodeName(lockNode); return true; } /*即使开始判断锁节点不存在,当前客户端也不一定能成功创建节点,在多线程下可能被其它线程抢先创建*/ return false; } else { System.out.println("当前有锁,client标记:" + lockInfo); //锁存在且属于当前客户端 return clientId.equals(lockInfo) ? true : false; } } /** * 解锁 */ public void unlock() { System.out.println(clientId + "解锁"); zkClient.delete(nodeName); } //5个客户端线程争锁 public static void main(String[] args) { for (int i = 0; i < 5; i++) { Thread t = new Thread(new Runnable() { public void run() { try { SingleNodeLock snl = new SingleNodeLock(); while(true) { if (snl.lock()) { System.out.println(snl.getClientId() + "获得锁,3s后解锁"); Thread.sleep(3000); snl.unlock(); snl.getZkClient().close(); break; } System.out.println(snl.getClientId() + "未获得锁,等待2s"); Thread.sleep(2000); } } catch (Exception e) { e.printStackTrace(); } } }); t.start(); } } }
3.3 Redis分布式锁
3.3.1 方案1
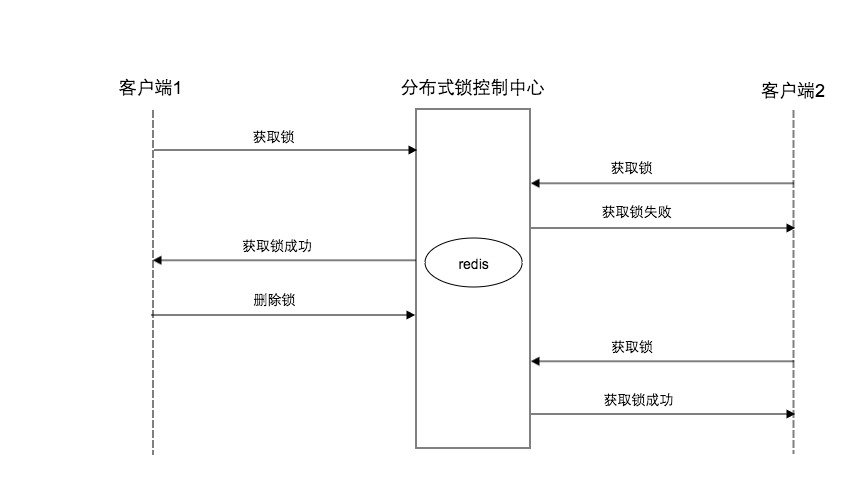
redis命令:SET resource_name my_value KEYX EXPTIME 30000
KEYX:如果缓存中不存在key值,则在缓存中设置该key值。
EXPTIME:过期时间,key值将在过期时间过后失效。
my_value:该key设置的对应的值。这个值必须在所有的客户端和所有的 lock request 之间唯一。这个唯一值可以用来保证删除锁时的安全性:删除锁时只有key值相等,并且key值对应的value相等的客户端,才可以删除锁。
3.3.1.1 方案流程
(1)客户端1向redis申请锁(key=1, value=1)
(2)redis中无锁的记录,客户端1插入成功,获得锁成功
(3)客户端1进行业务逻辑处理
(4)客户端2向redis申请锁(key=1, value=2)
(5)redis中已经有此锁记录,客户端2插入失败,获得锁
(6)客户端2捕获获得锁失败的异常,进入重试队列,由重试作业来进行下次所的获取以及逻辑得处理
(7)客户端1释放锁(key=1, value=1)
(8)客户端2重新获得锁成功,并进行业务逻辑处理
3.3.1.2 方案解决问题
(1)互斥性:redis的命令可以保证只有一个客户端可以写入成功,其他客户端会写入失败。
(2)安全性:设置key的value时,通过构造全局唯一的 my_random_value,在删除锁时key和value都相等时才可以进行删除,以此来保证本客户端的锁不会被其他客户端删除。
(3)死锁:由于一些异常情况(比如:服务器重启)使得锁没有释放,这样会导致死锁,通过设置redis的key过期时间,来避免这种异常死锁。
(4)容错:没解决
3.3.1.3 方案优势
(1)redis基于内存设置KV,性能好,可靠性高,对大并大可以有很好的支持,单机QPS可以达到5w。
3.3.1.4 方案不足
(1)单点故障,当单机redis出现故障时,无法做到故障切换,会导致整个分布式的服务不可用。
(2)需要人为监控单机redis的机器状态,有一定的维护成本。
3.3.2 方案2
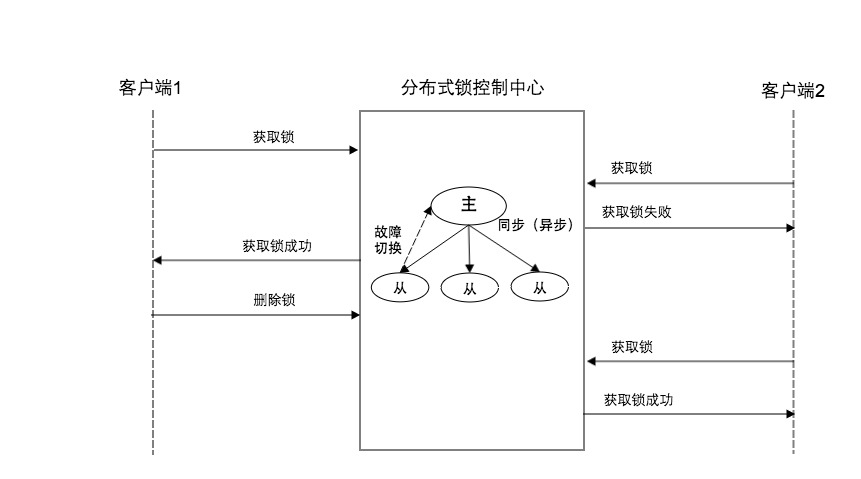
3.3.2.1 方案流程
同3.1.1
3.3.2.2 方案解决问题
(1)互斥性:没解决
(2)安全性:设置key的value时,通过构造全局唯一的my_value,在删除锁时key和value否相等时才可以进行删除,以此来保证客户端的锁不会被其它客户端删除。
(3)死锁:由于一些异常情况(比如:服务器重启)使得锁没有释放,这样会导致死锁,通过设置redis的key过期时间来避免这种异常的死锁。
(4)容错:当redis主节点down机时,redis从节点晋升为主节点,继续提供分布式锁服务。
3.3.2.3 方案优势
同3.3.1相比,redis主从模式提供了故障切换机制,可以保证分布式服务的正常提供。
3.3.2.4 方案不足
(1)互斥性无法保证。redis主从复制是异步复制,当客户端1在redis主节点设置锁成功后,当还没有同步到从节点时,主节点down机,从节点升级为主节点提供分布式锁服务,客户端2再次申请获得取锁服务,而刚刚升级完主节点的机器因为没有key值,客户端2会申请锁成功,而此时客户端1的业务逻辑并没有处理完成,在这种情况下,客户端1和客户端2就同时拥有了分布式锁,互斥性的条件无法满足。
3.3.3 方案3
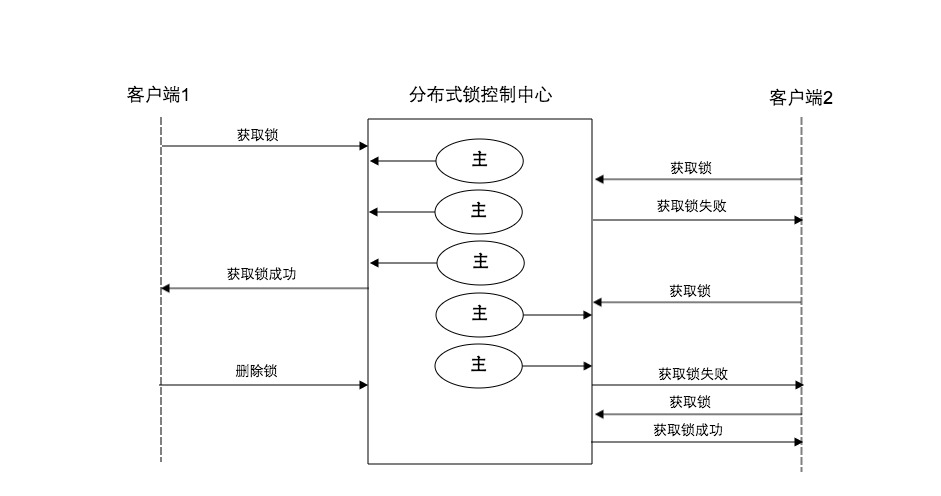
3.3.2.1 方案流程
(1)客户端1获取系统当前时间 current_time(ms)
(2)客户端1轮流用相同的key在N个redis节点上请求锁。客户端1在每个master节点请求锁时,会有一个比锁的过期时间相比小很多的超时时间。比如锁的过期时间是10s,那每个节点锁请求的超时时间可能是5-50ms的范围,这样可以防止客户端在某个down掉的master节点上阻塞过长时间,如果一个master节点不可用,应尽快尝试下一个master节点。
(3)客户端1计算在第二步中获取锁所花费的时间cost_time_get_lock,只有当客户端在大多数master节点上(N/2+1)成功获取了锁,而且锁花费的时间不超过锁的过期时间,那么这个锁就认为是分配成功了。
(4)如果所获取成功了,那么锁的自动释放时间为 锁的过期时间- 获得锁所花费的时间(expire_time - cost_time_get_lock)
(5)客户端2获取锁失败,可能是因为成功获取的锁不超过 N/2+1,可能是因为获取锁的时间超过了锁过期时间,客户端都必须在每个master节点上释放锁,包括那些客户端2认为没有成功获取到的锁。
3.3.2.2 方案解决问题
(1)互斥性:只有在大多数节点都获取锁成功时,才认为客户端获取锁成功,没有获取锁成功的客户端释放所有已经持有的锁。
(2)安全性:设置key的value时,通过构造全局唯一的my_value,在删除锁时key和value都相等时才可以进行删除,以此来保证本客户端的锁不被其他客户端删除。
(3)死锁:由于一些异常情况(比如:服务器重启)使得锁没有释放,这样会导致死锁,通过设置redis的key过期时间来避免这种异常死锁。
(4)容错:当redis主节点down机时,其他redis节点继续组成集群,提供分布式锁服务。
3.3.2.3 方案优势
基本上解决了分布式锁应该解决的问题。
3.3.2.4 方案不足
(1)算法复杂,开发成本高,维护代价大。















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









