







主要是个人学习使用,如有问题,烦请指正。
Elasticsearch 中explain评分分析:
-
解释document评分怎么来的。即query与doc匹配得分。
-
原理:
综合query中每个term与文档的打分。 对query, doc进行综合打分排序。
term 与query打分: 主要参考: term自身tfidf, doc自身特性, query特性。 总体为: query weight, field weight(这里的field理解为doc可能更好些)
文章末尾: https://www.cnblogs.com/forfuture1978/archive/2010/03/07/1680007.html。 通过向量余玄计算,对lucene公式进行了推导,特别好。 -
公式解释(lucene打分公示):此公式总科可分为两部分:query weight, field weight。

公式每部分介绍:
(1)queryNorm: 查询归一化
queryNorm(q) = 1/ sum of Squared wights
sum of Squared wights = idf(t1) * idf(t1) + idf(t2) * idf(t2) + … , 其中n为query中包含的term个数。 此处默认是在一个数据域中。如果是多个的话。
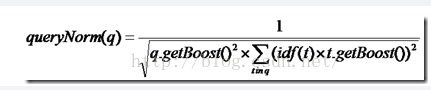
注意: 以上主要是对query做归一化处理。反应每个query自身统计信息。
(2)coord(q,d): 协调因此
coord(q, d) = overlap/maxoverlap . overlap: 文档d检索命中query中term个数。 maxoverlap: query中term个数。 即, query中term覆盖率。
(3)tf(t in d): term在文档中出现的个数:
tf(t in d) = √frequency。 出现的个数开方。
(4) idf(t) : 逆文档率
idf(t) = 1 + log ( numDocs / (docFreq + 1)) 。 docFreq : 包含该term的文档出. numDocs: 总文档数。log以e为低
(5)lengthNorm(t.field in d): 即norm(t, d)。 衡量 文档长度对打分的影响。

此处假设文档越长,则该文档重要性越低。因此加了这个凸显短文档,但感觉也不合理。所以lucene将该借口开发,可以根据业务自由定义,文档长度term打分的影响
,
各类Boost值
t.getBoost():查询语句中每个词的权重,可以在查询中设定某个词更加重要,common^4 hello
d.getBoost():文档权重,在索引阶段写入nrm文件,表明某些文档比其他文档更重要。
f.getBoost():域的权重,在索引阶段写入nrm文件,表明某些域比其他的域更重要
因为各种boost是先验知识, 因次norm(t,d) 可减缓为lengthNorm(f) 。
因为在索引中,不同的文档长度不一样,很显然,对于任意一个term,在长的文档中的tf要大的多,因而分数也越高,这样对小的文档不公平,举一个极端的例子,在一篇1000万个词的鸿篇巨著中,"lucene"这个词出现了11次,而在一篇12个词的短小文档中,"lucene"这个词出现了10次,如果不考虑长度在内,当然鸿篇巨著应该分数更高,然而显然这篇小文档才是真正关注"lucene"的。
所以在Lucene中,Similarity的lengthNorm接口是开放出来,用户可以根据自己应用的需要,改写lengthNorm的计算公式。比如我想做一个经济学论文的搜索系统,经过一定时间的调研,发现大多数的经济学论文的长度在8000到10000词,因而lengthNorm的公式应该是一个倒抛物线型的,8000到 10000词的论文分数最高,更短或更长的分数都应该偏低,方能够返回给用户最好的数据。
(6)boost(t.field in d) : t 在field中的重要性。
(7) 简化后公式:

公式来源推导:
原理: score(q, d) 是query中每个term与doc的匹配得分和。 因此需要算每个term与doc的得分。
此处以“无线通信” 为案例,基于分词, 可分为 无,线,通,信,(t1, t2, t3, t4) 推导“无”score的由来,记为score(t1, d).
从而推导出 score(q, d)即luence公示。
score(t1, d) = query weight * field weight.
query weight = idf(t1) * queryNorm(q)
idf(t1) = 1 + log ( numDocs / (docFreq(t1) + 1))。 doc Freq: 包含t1的doc数。 num Docs : 总doc数目。
queryNorm = idf(t1) * idf(t1) + idf(t2) * idf(t2) + idf(t3) * idf(t3) + idf(t4) * idf(t4)。 四个t的idf。 注意: query做归一化, quer中所有term该值一样
field weight= idf(t1) * tf(1) * fieldNorm()
idf(t1) : 上面已算出。
tf1(1): 当前文档包含t1的个数。然后开平方。
fieldNorm : 可用lengthNorm替代。
score(t1,d) = query weight * field weight = idf(t1) * queryNorm(q) * idf(t1) *tf(t1) * fieldNorm = tf(t1) * idf(t1)^2 * fieldNorm * queryNorm * coor(q,d)
因此score(q,d) = sum(tf(ti) * idf(ti)^2 * fieldNorm) * queryNorm * coor(q,d)
案例: 可参考https://blog.csdn.net/molong1208/article/details/50623948, 有具体案例说明。 挺具体的。
4. 参考说明:
https://www.cnblogs.com/forfuture1978/archive/2010/03/07/1680007.html
https://blog.csdn.net/molong1208/article/details/50623948
https://www.cnblogs.com/clonen/p/6674955.html?utm_source=itdadao&utm_medium=referral















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









