







 本文介绍了一种基于指数衰减函数来计算用户邮件缺失度的方法。该方法通过定义一个衰减函数并根据用户当天的收件量计算其邮件缺失度,以反映收件量增多时每封邮件对用户价值的影响逐渐减小的现象。
本文介绍了一种基于指数衰减函数来计算用户邮件缺失度的方法。该方法通过定义一个衰减函数并根据用户当天的收件量计算其邮件缺失度,以反映收件量增多时每封邮件对用户价值的影响逐渐减小的现象。
1、应用背景:
实际业务场景,我们会遇到一些特征随着时间(量)的变大,实际值的意义成指数衰减或增加。例如:
- 用户收到的邮件越多,每封邮件对用户的影响越小,因此计算每封邮件的价值时,我们不能等同计算,需要做一种衰减处理。
- 用户邮件缺失度:我们期期望收件越少用户确实度越大,当收件量大到一定程度时,邮件缺失度不变。
2、常见的应用函数
- 指数函数:y=a^x
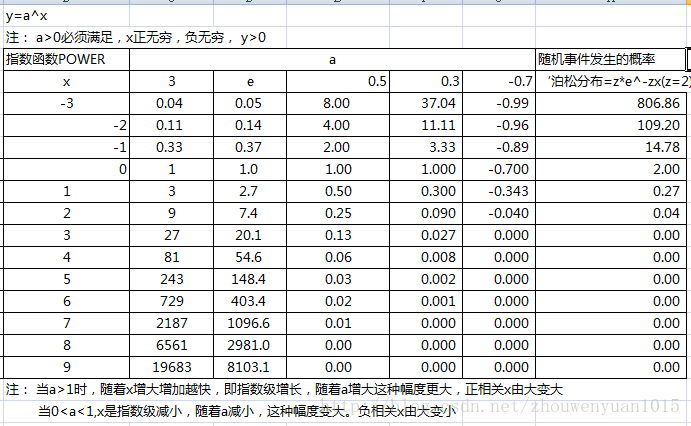
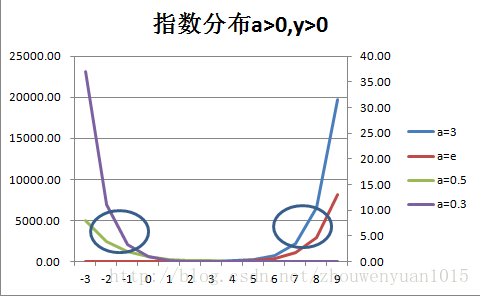
- 对数函数:y=log(x)
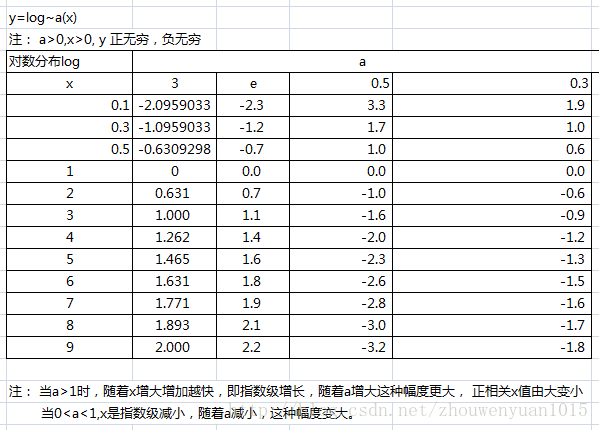
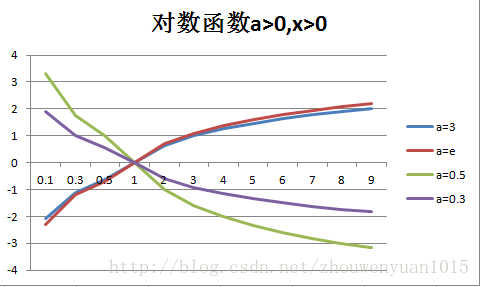
3.实际应用案例:
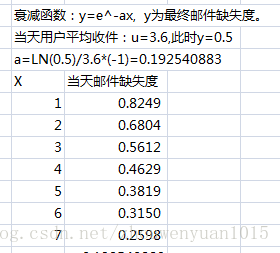
计算用户邮件缺失度: 根据当天收件量,计算用户当天邮件缺失度。
1)计算当天所有活跃用户平均收件u
2)当用户当天收件量=u时,设用户邮件缺失度为0.6.
3)定义衰减函数: y=exp(-aX),其中X为用户当天截止目前收件量,a为变化幅度。
4)根据:exp(-aX)=exp(-au)=0.6, 计算出a值。
5)然后利用y=exp(-aX),计算所有用户的邮件缺失度。具体如下:

















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









