







Spark Streaming applications tend to run forever, so their log files should be properly handled, to avoid exploding server hard drives. This article will give some practical advices of dealing with these log files, on both Spark on YARN and standalone mode.
Log4j’s RollingFileAppender
Spark uses log4j as logging facility. The default configuraiton is to write all logs into standard error, which is fine for batch jobs. But for streaming jobs, we’d better use rolling-file appender, to cut log files by size and keep only several recent files. Here’s an example:
|
|
This means log4j will roll the log file by 50MB and keep only 5 recent files. These files are saved in /var/log/spark directory, with filename picked from system property dm.logging.name. We also set the logging level of our package com.shzhangji.dmaccording to dm.logging.level property. Another thing to mention is that we set org.apache.spark to level WARN, so as to ignore verbose logs from spark.
Standalone Mode
In standalone mode, Spark Streaming driver is running on the machine where you submit the job, and each Spark worker node will run an executor for this job. So you need to setup log4j for both driver and executor.
For driver, since it’s a long-running application, we tend to use some process management tools like supervisor to monitor it. And supervisor itself provides the facility of rolling log files, so we can safely write all logs into standard output when setting up driver’s log4j.
For executor, there’re two approaches. One is using spark.executor.logs.rolling.strategy provided by Spark 1.1 and above. It has both time-based and size-based rolling methods. These log files are stored in Spark’s work directory. You can find more details in the documentation.
The other approach is to setup log4j manually, when you’re using a legacy version, or want to gain more control on the logging process. Here are the steps:
- Make sure the logging directory exists on all worker nodes. You can use some provisioning tools like ansbile to create them.
- Create driver’s and executor’s log4j configuration files, and distribute the executor’s to all worker nodes.
- Use the above two files in
spark-submitcommand:
|
|
Spark on YARN
YARN is a resource manager introduced by Hadoop2. Now we can run differenct computational frameworks on the same cluster, like MapReduce, Spark, Storm, etc. The basic unit of YARN is called container, which represents a certain amount of resource (currently memory and virtual CPU cores). Every container has its working directory, and all related files such as application command (jars) and log files are stored in this directory.
When running Spark on YARN, there is a system property spark.yarn.app.container.log.dir indicating the container’s log directory. We only need to replace one line of the above log4j config:
|
|
And these log files can be viewed on YARN’s web UI:
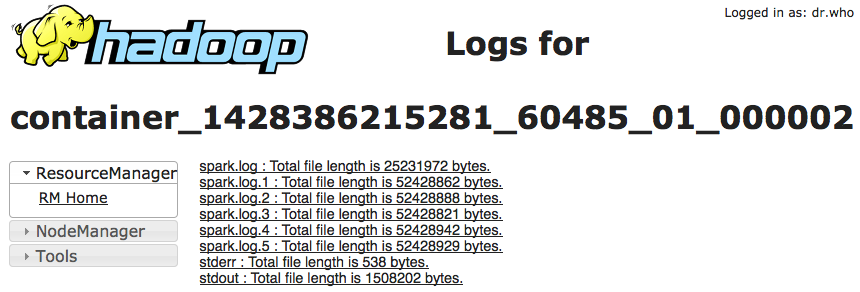
The spark-submit command is as following:
|
|
As you can see, both driver and executor use the same configuration file. That is because in yarn-cluster mode, driver is also run as a container in YARN. In fact, the spark-submit command will just quit after job submission.
If YARN’s log aggregation is enabled, application logs will be saved in HDFS after the job is done. One can use yarn logs command to view the files or browse directly into HDFS directory indicated by yarn.nodemanager.log-dirs.
ref:http://shzhangji.com/blog/2015/05/31/spark-streaming-logging-configuration/















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









