







第一、ElasticSearch 简介
1、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
2、 Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
3、 Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
4、Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch第二、Windows 安装ElasticSearch 服务



第三、安装ElasticSearch的图形化界面插件
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效 果,完成索引数据的查看。安装插件的方式有两种,在线安装和本地安装。本文档采用本地安装方式进行head插 件的安装。elasticsearch-5-*以上版本安装head需要安装node和grunt





安装完毕,可以通过cmd控制台输入:node -v 查看版本号
npm install ‐g grunt‐cli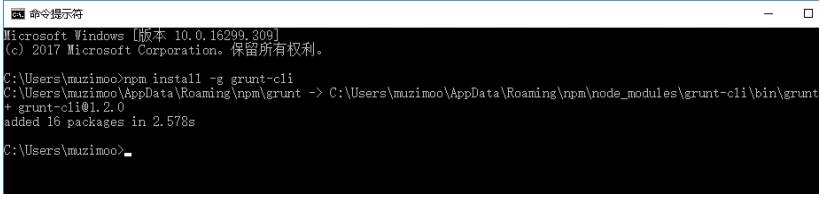


http.cors.enabled: true
http.cors.allow-origin: "*"
第四、ElasticSearch相关概念(术语)
4.1 概述

4.2 ElasticSearch 核心概念
第五、ElasticSearch客户端操作之Postman
1、ElasticSearch的接口语法
curl ‐X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' ‐d '<BODY>'参数说明:

2、Postman 操作之创建索引库index = 新增索引库blog1

3、Postman 操作之创建索引库index 添加映射mapping =为bolg1索引库添加hello 的映射
请求URL: post http://localhost:9200/blog1/hello/_mapping
请求体:
{
"hello": {
"properties": {
"id":{
"type":"long",
"store":true
},
"title":{
"type":"text",
"store":true,
"index":true,
"analyzer":"standard"
},
"content":{
"type":"text",
"store":true,
"index":true,
"analyzer":"standard"
}
}
}
}
postman 截图:

4、postman 操作之删除索引库
请求URL: delete http://localhost:9200/blog1
postman截图:

5、postman 操作之创建index 索引库和映射mapping = 创建blog2 索引库并指定article 的相关映射
请求URL: put http://localhost:9200/blog2
请求体:
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true
},
"title": {
"type": "text",
"store": true
},
"content": {
"type": "text",
"store": true
}
}
}
}
}
postman 截图:

6、postman 操作之新增文档
请求URL: post http://localhost:9200/blog2/article/1
请求体:
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java 开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时 搜索,稳定,可靠,快速,安装使用方便。"
}
postman 截图:

7、postman 操作之更新文档
请求URL: post http://localhost:9200/blog2/article/1
请求体:
{
"id":1,
"title":"【修改】ElasticSearch是一个基于Lucene的搜索服务器",
"content":"【修改】它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch 是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够 达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
postman 截图:

8、postman 操作之删除文档
请求URL: delete http://localhost:9200/blog2/article/1
postman 截图:

9、postman 操作之删除文档
请求URL: delete http://localhost:9200/blog2/article/1
postmane 截图:

10、postman 操作之根据文档ID进行查询
请求URL: get localhost:9200/blog2/article/1
postmane 截图:

11、postman 操作之根据文档querystring进行查询
请求URL: post localhost:9200/blog2/article/_search
请求体:
{ "query": { "query_string": { "default_field": "title", "query": "搜索服务器" } } }postmane 截图:

12、postmane 操作之 根据文档term进行查询
请求URL: post localhost:9200/blog2/article/_search
请求体:
{ "query": { "term": { "title": "搜索" } } }posmane 截图:

第六、ElasticSearch服务端集成IK分词
6.1 IK分词器简介:


6.3 IK分词功能测试
{
"analyzer":"ik_smart",
"text":"我是程序员"
}postmane 截图:


2)最细切分:在浏览器地址栏输入地址
请求URL: post http://127.0.0.1:9200/_analyze?pretty=true
请求体:
{
"analyzer":"ik_max_word",
"text":"我是程序员"
}postman 截图:


6.4 修改索引库的mapping 映射
1、删除原有的blog2 索引库
delete http://localhost:9200/blog2put http://localhost:9200/blog2请求体:
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true
},
"title": {
"type": "text",
"store": true,
"index":true,
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":true,
"analyzer":"ik_max_word"
}
}
}
}
}
3、创建文档
post http://localhost:9200/blog2/article/1请求体:
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java 开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时 搜索,稳定,可靠,快速,安装使用方便。"
}


5、再次执行trem 测试

检索结果:
















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









