






 本文分享了作者作为IBMXIV存储维护工程师的经验,包括散热问题、网络交换机更换、管理IP配置、TA工具的重要性以及UPS维护注意事项,提醒读者在处理XIV存储时需注意的关键点。
本文分享了作者作为IBMXIV存储维护工程师的经验,包括散热问题、网络交换机更换、管理IP配置、TA工具的重要性以及UPS维护注意事项,提醒读者在处理XIV存储时需注意的关键点。
IBM 存储XIV作为在全闪存存储问世以前一代存储之王,在存储界有很重要的地位。
作为整体、单体存储,能够做到分布式计算、分布式存储、自有电池防止数据丢失,而且最重要的是在机械式硬盘的时代,通过SATA低速(7200RPM)硬盘,达到、甚至超过了同期的其他存储,真是神一样的存在。
但是,作为IBM全资收购的一款存储,也有自己的一些问题,作为可能是维护XIV存储较多的工程师,本人走过了大半个中国,维护超过30台XIV存储,总结一点经验吧,分享给大家。
1、作为分布式存储,又是集中式存储,XIV存储的每个硬盘笼子都是完全紧贴着安装在一起的,这样对散热提出了很高的要求。
我曾经见过一台XIV存储的硬盘笼子损坏,在更换下来后,打开硬盘笼子,发现主板中间部分已经被高温烤黑了,全部烧坏了。这还是第一次见到主板会这样损坏。
2、作为分布式存储,需要内部的数据交换,所以内部的两个网络交换机很重要。
二代XIV使用的是电口的万兆交换机,通过RJ45网线连接,每一个交换机的端口都有定义,如果端口损坏那么需要更换交换机;如果网线损坏,可以使用现有XIV存储上没有使用的网线替换,但是要更换标签。
三代XIV使用的是IB交换机,带宽更高。相互连接的线缆最好是使用内部闲置的线缆替换。
以上两种交换机都是侧面散热,对于现有机柜前后散热的设计,有一定的弊端。我总是能见到内部交换机的风扇报警,这时可以单独更换风扇,而不是更换整个交换机。
更换内部交换机无论是二代还是三代,都需要使用TA工程师助手操作,才能正确更换。
3、一般客户都是通过更改管理IP地址,将XIV存储连接至内网管理。
这时需要注意我们的笔记本连接的是XIV存储哪个端口,是管理口,还是tech端口,二代、三代需要不同的端口来管理。二代一般是管理口,三代一般是tech口管理。如果端口连接的有问题,会提示你,需要连接到IBM管理网络才能正常工作。
如果客户链接到了他们的内网,最好是通过与客户内网同网段的IP地址进行管理,这样最方便。
4、关于TA工程师助手。
这个是维护XIV必备的一个工具,相对应的还有一个管理软件GUI。GUI只能是一般的查看XIV状态、管理XIV,比如设置卷、分配卷等等。TA是我们维护XIV存储必备工具,除了维护硬盘以外,其他的部件更换都需要通过TA来完成。对于不同的二代、三代XIV存储,不同的微码版本的XIV存储,需要的TA版本是不一样的,如果不能登录或者登录后提示认证失败,那就是TA版本不匹配,需要更新版本的TA。
5、关于XIV存储中的UPS。
XIV存储作为集中式的分布式存储,有自己UPS,就是机器最下方的三个UPS,它们作为XIV存储的后备电源,在供电出现问题时,会给XIV存储供电,直到XIV存储正常关机,将所有缓存中的数据回写到硬盘中。
XIV存储中UPS的品牌是APC的,作为APC的独立UPS,这个型号的UPS每半个月会测试一次电池,将电池充放电。XIV存储的UPS在整个机柜的最下方,散热还算可以,以我的经验,一般电池组在这样的环境下,一年至二年左右就会出现UPS报警,这时要查看,是UPS本身损坏还是电池测试失败。一般都是UPS外表的告警灯亮起,这时需要登录到系统中,通过GUI和Xcli命令查看是哪个部分的问题。
更换UPS整体很麻烦,因为下方留给我们操作的空间很小,UPS后面还有一个ATS挡在那里,需要仔细操作。UPS的网络接口、串口,输入电缆、输出电缆,都需要相对应的一一更换。
而且对于UPS、电池,都是属于强电范围,需要更加小心。
实际上在更换UPS或者UPS电池中,我们操作的并不多,都是TA在做一些检测、测试和更换操作,包括更改UPS电池维护时间,所以没有TA,我们是不能更换UPS或者UPS电池的。
下图是比较惨烈的故障了,可以看到右下角已经处于橘黄色,系统处于服务模式,已经不对外提供数据服务了。
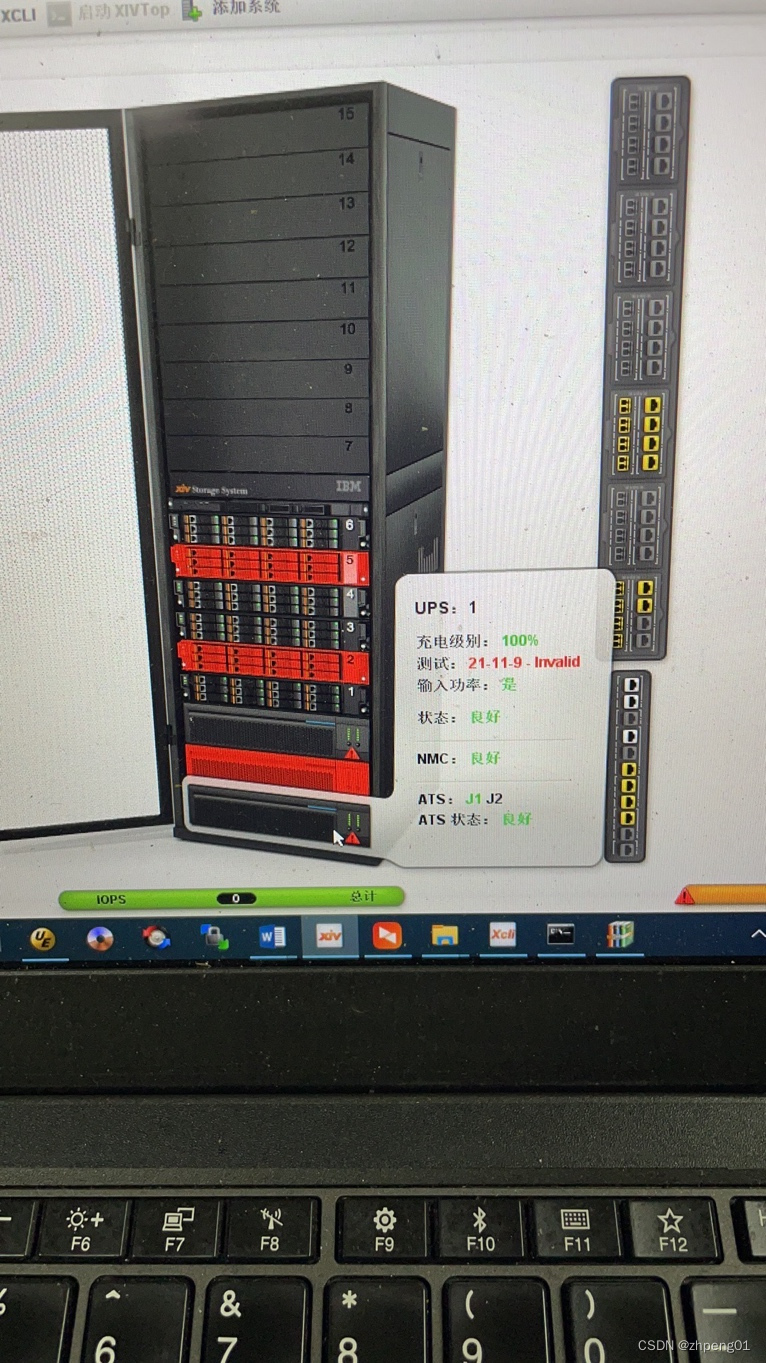
综上根据这么多年维护XIV存储经验所写的,希望有一定的帮助。

















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









