







用py写爬虫也写过一些但是一直没有尝试过scrapy,大概自己写的项目都比较小,用beautifulsoup就搞定了不太需要用这种功能全面的框架,不过这两天还是接触了一下,用scrapy爬了一波堆糖的图片。
安装scrapy
在ubuntu上安装并不麻烦,不过似乎要装很多依赖的库,还是出了一些问题,把提示没有的库都装上就差不多行了,还有在我鼓捣了半天scrapy之后,第二天django版本莫名其妙变成了1.6.3,原来是1.7.3,不知道是不是这个原因,总之觉得很摸不着头脑,安装的scrapy是1.0版本。
创建项目
跟着文档一步一步来…先cd到某个文件夹下
scrapy startproject duitang
自动生成一个文件夹
duitang/
scrapy.cfg # deploy configuration file
duitang/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
...然后是创建spider,也就是实现具体抓取逻辑的文件,scrapy提供了一个便捷的命令行工具,cd到生成的项目文件夹下执行
scrapy genspider mydomain mydomain.com
会在spiders文件夹下生成一个.py文件。到这里差不多准备工作完成了,接下来需要人工找出图片链接的规律。
抓取逻辑
需求:
搜索一个topic然后把搜索出来的图片下载下来。
获取页面链接
在堆糖上搜索了一下,找到搜索结果页面链接格式为
keyword是搜索的关键词,然后这个页面会展示很多搜索到的结果,但是因为堆糖使用的是瀑布流的展示方式,拉到页面底部会加载出更多图片,但是spider并不能实现这一过程。
怎么实现不仅仅只抓取这一个页面呢,尝试了一下往下拉,在网页的network的console里面里面找到了加载下一页的链接
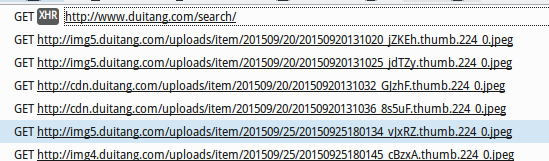
如图是之后加载出来的,最上面一行的完整链接是
http://www.duitang.com/search/?page=2&kw=%E5%A4%A7%E5%9C%A3&type=feed&_type=&_=1444971822370
在新标签页中打开是一堆json数据,尝试把&_type=&_=1444971822370删掉,果然出现了网页的页面,这时候网页链接和原来只差一个page=2,所以知道了只要加上page=x就可以爬到后面的页面了。
分析网页查找图片链接
接下来是在网页里面找到图片的链接,一般的图片就像上面图中加载出来的那样
http://img5.duitang.com/uploads/item/201509/20/20150920131020_jZKEh.thumb.224_0.jpeg
这样的格式
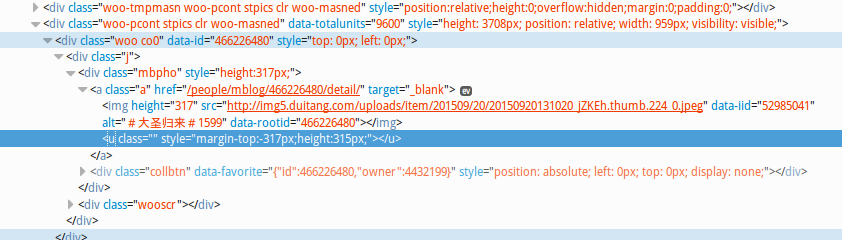
然而之后发现这是缩略图,所有的图都缩成了224宽度,之后点开大图,发现还是不对,虽然放大了也只是放大到700宽度,链接中的224全都变成了700,不过大图点开就是原图了。。。
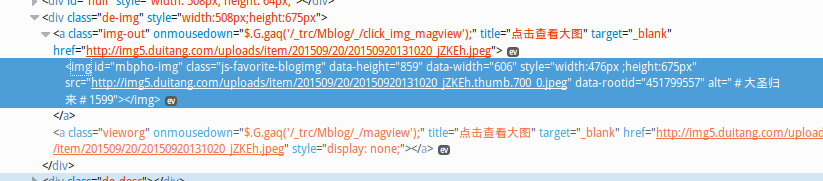
然而原图和缩略图链接的差别不过是没有.thumb.224_0这一段,所以就好处理了,把缩略图的链接抓取下来然后改一下链接字符串就可以得到原图链接。
抓取实现
获取链接
即scrapy的工作流程,首先在创建的spider文件中实现逻辑,我的爬虫名字叫dasheng,因为爬的是大圣归来的图,自动生成的代码里面是这样:
import scrapy
class $classname(scrapy.Spider):
name = "$name"
allowed_domains = ["$domain"]
start_urls = (
'http://www.$domain/',
)
def parse(self, response):
pass$classname是形似DashengSpider这样的的类名,当然也没有特别严格的命名要求,$name是这个爬虫的名字,很重要,后面执行程序的时候就是按照这个名字执行的。
allowed_domains是限制爬虫的抓取范围在某个站点内
start_urls是开始抓取的链接,也可以是list格式。
parse方法就是对页面信息进行处理,它的参数就是访问页面的response。
首先start_urls里面改成自己的链接,然后尝试在页面中获取图片链接,以前用beautifulsoup写的时候都是自己试一下改一下感觉很不方便,scrapy提供了一个shell可以轻松对response进行处理,命令行格式如下
scrapy shell [url]
执行会访问这个链接并获取response,之后就可以对response进行处理了。
scrapy提供xpath和css两种选择器来选择需要的元素,我这里用的是xpath,具体格式参考文档,感觉挺简单的。
需要的链接是在
response.xpath(‘//a[@class=”a”]/img/@src’)这个元素中,所以parse方法这样写
for sel in response.xpath('//a[@class="a"]/img/@src'):
detaillink = sel.extract().replace('.thumb.224_0', '')
print detaillinkresponse.xpath(‘//a[@class=”a”]/img/@src’)获取到的是一个选择器实例对象,而sel.extract()函数是把选择器其中的内容抽取出来,然后调用replace函数处理链接字符串。
这时候可以运行一下爬虫试试
scrapy crawl spider_name
这样就开始爬了,在终端可以看到输出的链接还有很多其他的信息。可能会有奇奇怪怪的报错?…对照着检查一下就好。
下载图片
当然我最后的目的是把图片下载到本地所以只获取图片链接还不够,百度了一下说可以用Item Pipeline中的Image Pipeline,这个pipeline,个人理解是对抓取获得的数据进行进一步处理的文件。要使用这一部分还需要一些准备工作。
首先在settings.py中找到设置管道的部分(大概60几行),改成如下:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'duitang.pipelines.SomePipeline': 300,
#}
ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1}
IMAGES_STORE = 'pic/' # 存储位置
IMAGES_EXPIRES = 15 # 15天内不抓取重复的图片然后在items.py中定义一个item,它是一个类似字典的东西,用来存储爬到的信息,储存在scrapy特有的Field里面,Image Pipeline要求两个必须的item属性image_urls和images,定义如下。
import scrapy
class DuitangItem(scrapy.Item):
# define the fields for your item here like:
image_urls = scrapy.Field()
images = scrapy.Field()接下来改写spider的部分,把爬到的链接储存在image_urls字段中
def parse(self, response):
for sel in response.xpath('//a[@class="a"]/img/@src'):
item = DuitangItem()
detaillink = sel.extract().replace('.thumb.224_0', '')
item['image_urls'] = [detaillink]
yield item接下来在pipleline.py中重写管道函数
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class DuitangPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item这样就完成了,接下来在运行一遍爬虫,就可以看到图片被下载到pic文件夹下的full文件夹了。
注意:imge_urls属性的格式是列表而不是字符串,因为这个问题栽了一坑。
但是到这时候,大概只爬到了第一页的图片,需要更改链接中的page数值。所以最终代码是这样的
# -*- coding: utf-8 -*-
import scrapy
from duitang.items import DuitangItem
class DtSpider(scrapy.Spider):
name = "cbl"
allowed_domains = ["duitang.com"]
page = 1
start_urls = []
for page in range(1,100):
start_urls.append("http://www.duitang.com/search/?page=%s&kw=keyword&type=feed" % page)
def parse(self, response):
for sel in response.xpath('//a[@class="a"]/img/@src'):
item = DuitangItem()
detaillink = sel.extract().replace('.thumb.224_0', '')
item['image_urls'] = [detaillink]
yield item完毕,100页大概能抓2000+图片的样子,速度很快。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}