






 文章讲述了作者在第二届猿人学web端攻防赛中遇到的问题,包括如何绕过无限debugger,逆向工程获取token,以及处理内存爆破和环境缺失等问题,最终通过JavaScript和Python编程解决。
文章讲述了作者在第二届猿人学web端攻防赛中遇到的问题,包括如何绕过无限debugger,逆向工程获取token,以及处理内存爆破和环境缺失等问题,最终通过JavaScript和Python编程解决。
猿人学第二届的题目明显比第一届要难的多,但前几道题走对路子其实还是比较简单的。
2 - 感知 - 第二届猿人学web端攻防赛![]() https://match2023.yuanrenxue.cn/topic/2打开页面先打开开发工具的话,会调到一个无限debugger,往上跟一步是构造器生成的,我试着用游猴hook构造器但是不成功,总卡死,如果有知道怎么弄的还望告知。但先进页面再打开f12按分页就没了无限debugger,
https://match2023.yuanrenxue.cn/topic/2打开页面先打开开发工具的话,会调到一个无限debugger,往上跟一步是构造器生成的,我试着用游猴hook构造器但是不成功,总卡死,如果有知道怎么弄的还望告知。但先进页面再打开f12按分页就没了无限debugger,
每次分页明显抓到两个包,一个数据包一个图片包,但这个图片包很奇怪,每次返回同样的,明显不合理,用fidder抓包或者python逆向下这个包,可以看到是返回一个时间戳。
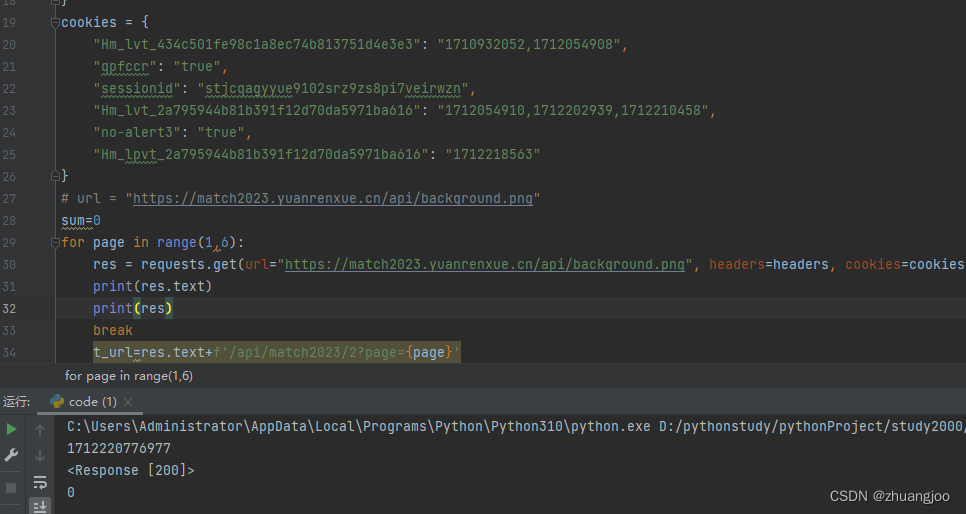
不用怀疑,这个时间戳肯定有用处!
看下抓数据那个包,来回翻页会发现只有请求体的token需要逆向,而这个请求体是在params里,拼接到url里,那我们就直接用游猴hook url里的关键字token=。这里说一下,打开游猴后需要刷新页面,同样可以关掉f12,刷新页面后在打开f12进行翻页,跳过无限debugger。
// ==UserScript==
// @name hookparams
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @match https://match2023.yuanrenxue.cn/topic/2
// @icon https://www.google.com/s2/favicons?sz=64&domain=yuanrenxue.cn
// @grant none
// @run-at document-start
// ==/UserScript==
(function () {
var open = window.XMLHttpRequest.prototype.open;
window.XMLHttpRequest.prototype.open = function (method, url, async) {
if (url.indexOf("token") != -1) {
debugger;
}
return open.apply(this, arguments);
};
})();发现很轻松的断到来token生成的地方。
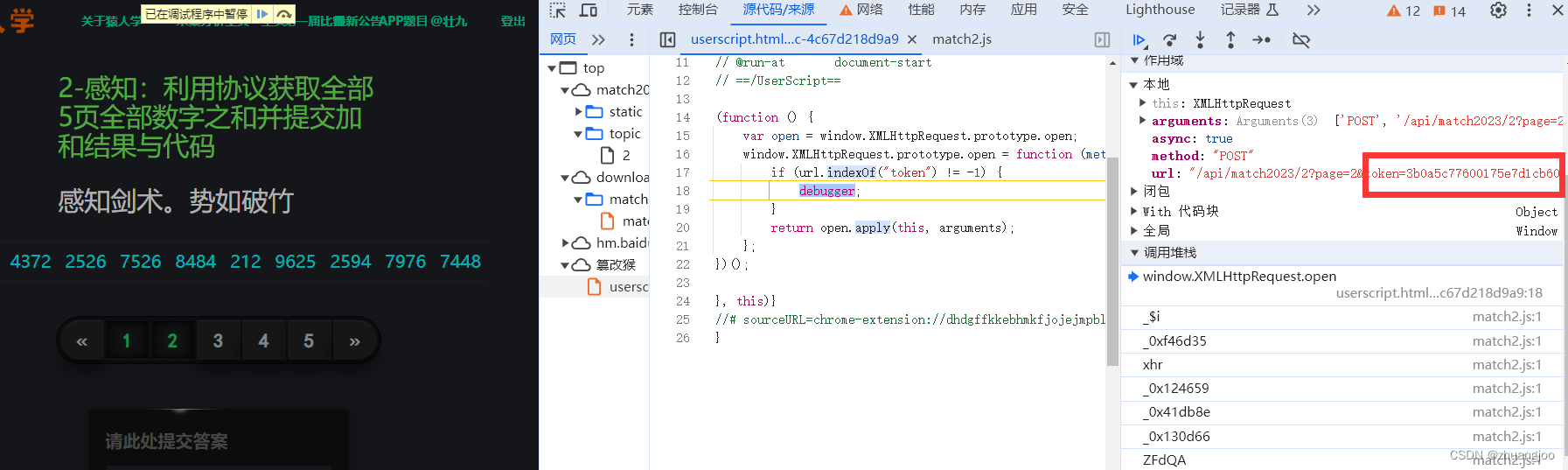 往上跟一步发现其传入的参数包含token,参数又是有argument来的,argument不好跟,但是我们可以发现右边的变量里有两个变量包含token和其值,另外一个只只有值
往上跟一步发现其传入的参数包含token,参数又是有argument来的,argument不好跟,但是我们可以发现右边的变量里有两个变量包含token和其值,另外一个只只有值

第一处是第二处拼接了个时间戳,时间戳好弄,要么是new Date生成的,要么是刚才那个图片包返回的,还有一处是第二处去掉来token=,所以我们直接跟这个变量,很容易就找到生成的地方。
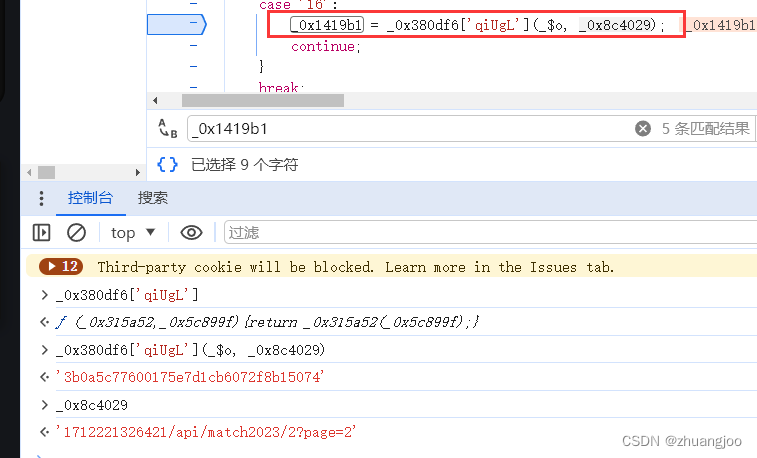 上图可以看出token就是等于_$o(_0x8c4029),参数_0x8c4029是时间戳加上url,我们先写死,把_$o抠出来,缺啥补啥。
上图可以看出token就是等于_$o(_0x8c4029),参数_0x8c4029是时间戳加上url,我们先写死,把_$o抠出来,缺啥补啥。
补到_0x4844()这个函数时,发现顶部有个自执行函数,而且把_0x4844作为参数传进去的。索性一起扣下来。
 来到了这个错误,
来到了这个错误,
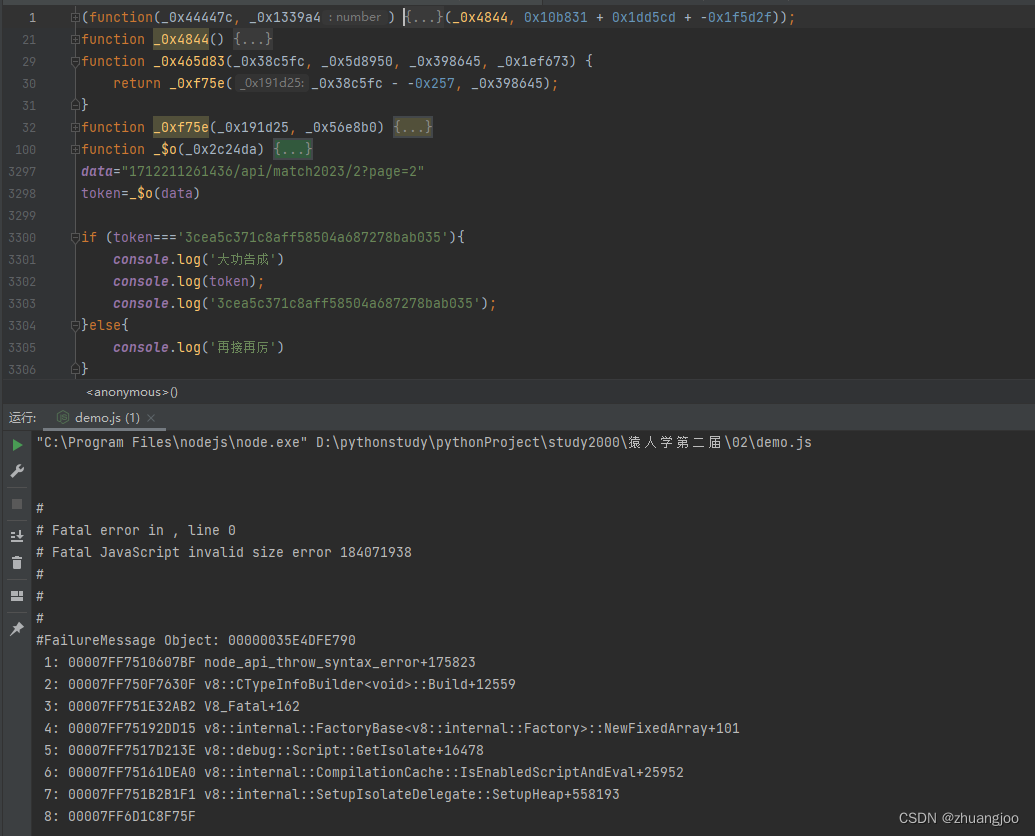
到这儿别慌,这是内存爆破引起的,碰到这样的问题,极大可能是格式监测引起的,我们可以借助压缩代码网站,把格式化后的代码还原回去。
js代码压缩网站JS 压缩/解压工具 | 菜鸟工具JS 压缩/解压工具可以实现 JS 代码在线压缩、解压,也可以格式化 JS 代码。..![]() https://www.jyshare.com/front-end/51/
https://www.jyshare.com/front-end/51/
测试来下是_0xf75e这个函数格式化引起的,压缩即可。
补完document后发现这个错误,
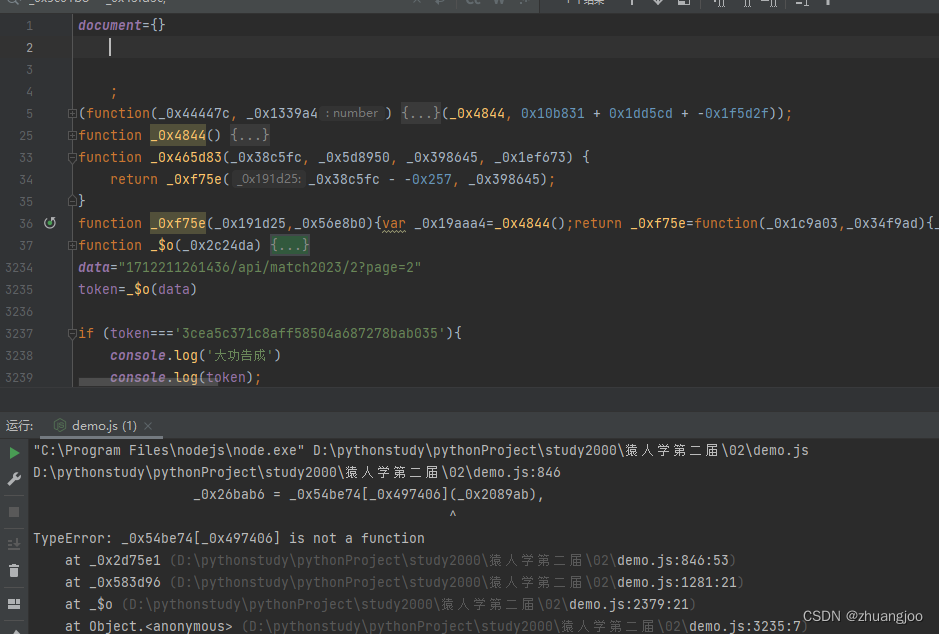 跟进去,是document里缺少"createElement"方法,补上。
跟进去,是document里缺少"createElement"方法,补上。
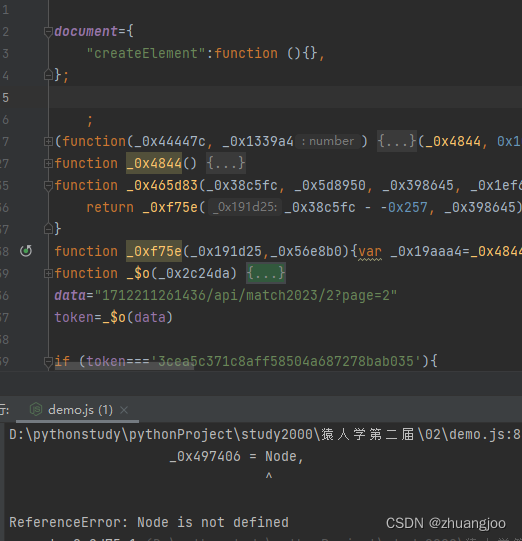
Node在浏览器跟一下,是一个方法,补上。
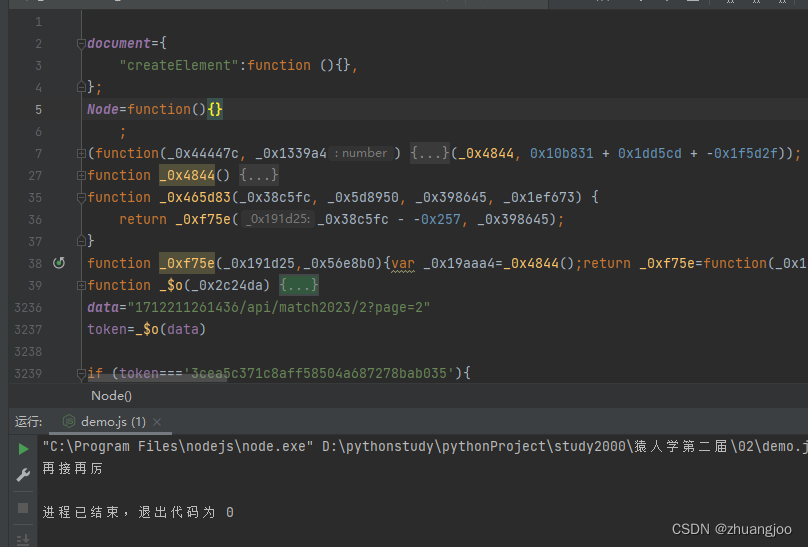 至此代码跑通了,但拿到的数据不对,放到当前网站的控制台里运行拿到的token是正确的。那就极大可能是缺少环境。
至此代码跑通了,但拿到的数据不对,放到当前网站的控制台里运行拿到的token是正确的。那就极大可能是缺少环境。
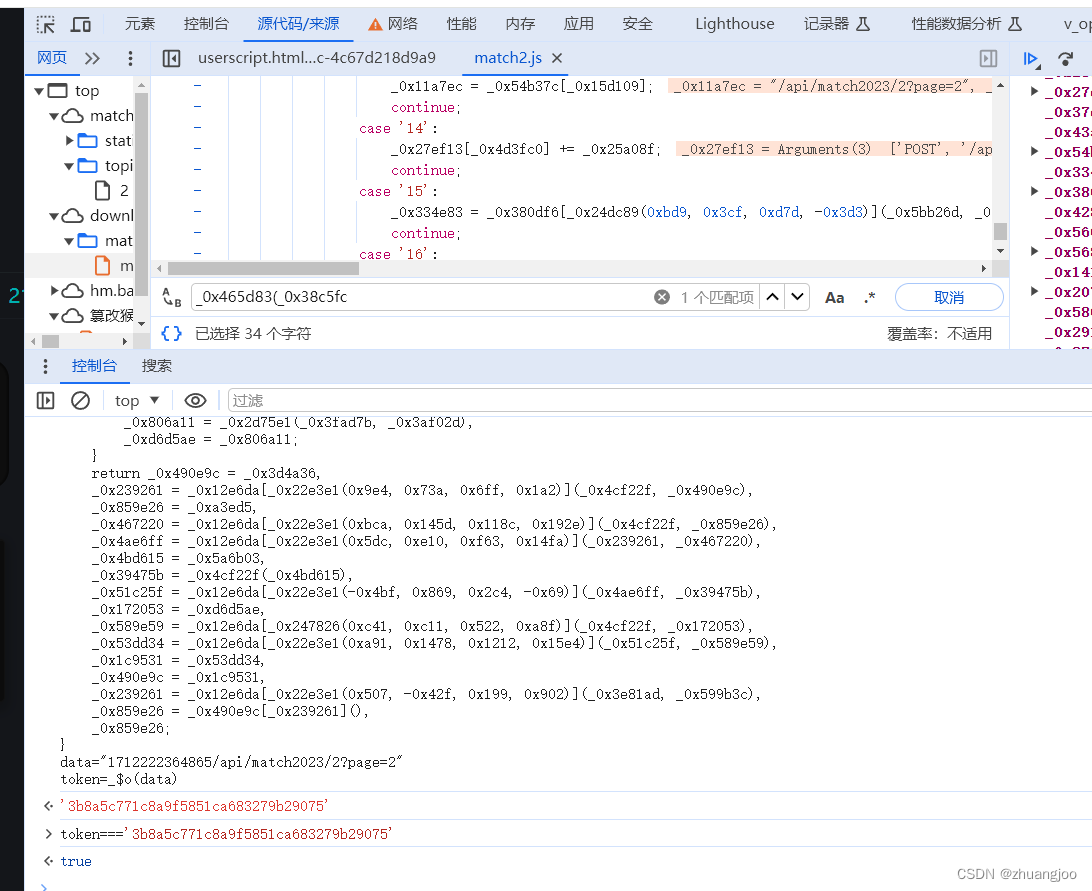 搜一下常用的,发现缺少window,Window,Document,全部补上。还有个login,在浏览器是true,在node里却是未定义,所以把login=true补上;
搜一下常用的,发现缺少window,Window,Document,全部补上。还有个login,在浏览器是true,在node里却是未定义,所以把login=true补上;
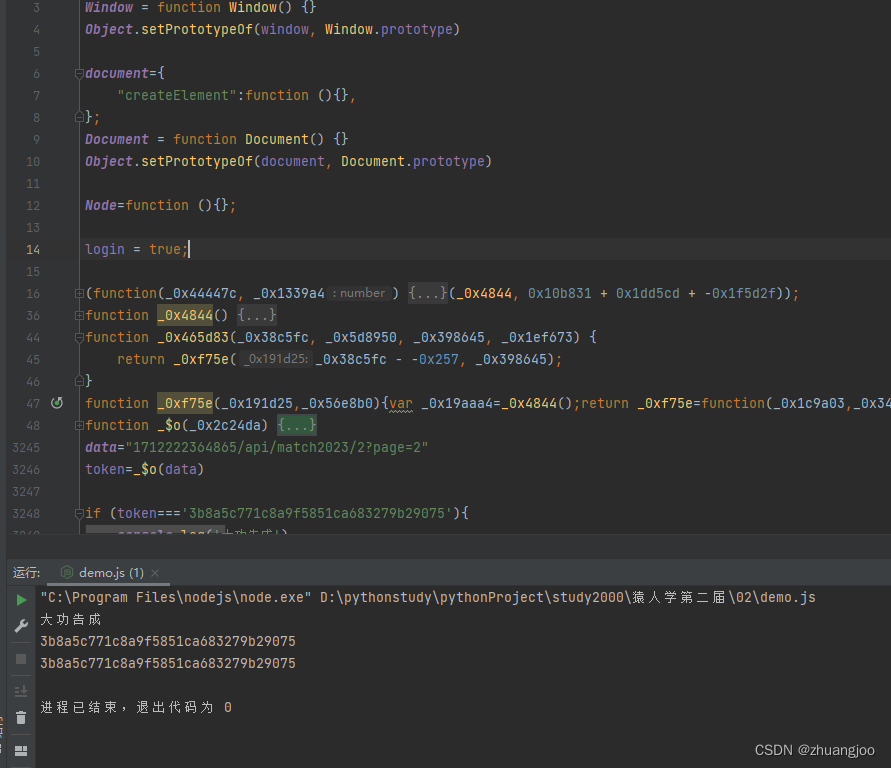
剩下的就是python编写代码了。测试发现,两处用的时间戳都是请求那个图片包返回的时间戳!python代码这里就不编写了。















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









