






template <int N>
void show_times(std::string msg) {
for (int i = 0; i < N; i++) {
std::cout << msg << std::endl;
}
}
int main() {
show_times<1>("one");
show_times<3>("three");
show_times<4>("four");
}这样做相比于void func(N) 的好处是,如果作为模板N传入传输的话,N是一个编译期常量,对于不同的N,编译器都会针对其优化并生成单独的一份代码,从而可以做单独的优化。
比如N=0 那么程序就不执行for语句,如果N=1,那么程序就只执行cout语句,而不执行for,如果N=3 那么可能自动unroll,如果N= 10/100/1000,那么程序可能会按照原来的for执行。
而 func(N) 则是运行期的常量,编译器则无法自动优化。
但是模板元也有坏处,就是每编译一次都会出现一个新的函数,所以编译时间会变慢。
而且如果msg是一个自定义的变量,那么可能一个cout<<msg就会有无数个for,所以模板的内部实现必须都暴露出来,除非用一些特别的手段,否则定义和实现都要包含在头文件中.
for (int i = 0; i < N; i++) {
if constexpr (i%2){
std::cout<<res<<endl;
}
}上面这个例子就是不对的,因为i是在循环中的变量,不是一个常量,所以不要可以用constexpr。
并且除了if constexpr 的表达式不可以用于运行时的变量,模板的尖括号里也不可以。
int main() {
bool debug = true;
std::cout << sumto<debug>(4) << std::endl;
return 0;
}
//但是可以通过在bool前面加入constexpr来解决
int main() {
constexpr bool debug = true;
std::cout << sumto<debug>(4) << std::endl;
return 0;
}
//但是debug = 右边的值也必须是编译期常量,不可以是别的值
int main() {
constexpr bool debug = time(NULL);//会报错
std::cout << sumto<debug>(4) << std::endl;
return 0;
}同理
bool isnegative(int n) {
return n < 0;
}//这样也是不对的,要将isnegative的返回值也是constexpr才行。
int main() {
constexpr bool debug = isnegative(-2014);
std::cout << sumto<debug>(4) << std::endl;
return 0;
}
//就比如这样
constexpr bool isnegative(int n) {
return n < 0;
}
int main() {
constexpr bool debug = isnegative(-2014);
std::cout << sumto<debug>(4) << std::endl;
return 0;
}而且min/max这些都是constexpr函数,也是可以在模板尖括号中使用的。
模板函数具有惰性
#include <iostream>
template <class T = void>
void func_that_never_pass_compile() {
"字符串" = 2333;
}
int main() {
return 0;
}因为上面的主程序main中没有调用func_that_never_pass_compile函数,所以编译器都不会看这个函数一眼,所以上面明显错误得到情况下,还是可以编译成功。
但是现在用inline内联作用已经不大了,因为现在都是编译器自己决定要不要内联,所以如果用inline的话更像是给编译器一个建议。
auto关键字:
auto &product_table() {
static std::map<std::string, int> instance;
return instance;
}
int main() {
product_table().emplace("佩奇", 80);
product_table().emplace("妈妈", 100);
}auto关键字也可以作为返回类型,对于这个程序而言就是一个懒汉单例模式,只有在声明的时候才会创建。
右值
#include <cstdio>
void test(int &) {
printf("int &\n");
}
void test(int const &) {
printf("int const &\n");
}
void test(int &&) {
printf("int &&\n");
}
int main() {
int a = 0;
int *p = &a;
test(a); // int &
test(*p); // int &
test(p[a]); // int &
test(1); // int &&
test(a + 1); // int &&
test(*p + 1); // int &&
const int b = 3;
test(b); // int const &
test(b + 1); // int &&
}右值引用(R-value reference)是 C++11 提出的一种新的引用类型,使用 && 符号来表示。与左值引用 lvalue reference 不同,右值引用主要用于移动语义和完美转发。
右值引用最常见的用途是实现移动构造函数和移动赋值运算符。当类中存在动态分配的资源时,使用移动语义可以省去不必要的复制操作,提高程序效率。在 STL 中也广泛使用了右值引用和移动语义,例如 std::vector 和 std::string 类就实现了移动构造函数和移动赋值运算符,可以提供更高效的操作。
除此之外,右值引用还可以用于实现完美转发(perfect forwarding),即将一个参数以相同的方式传递给另一个函数,同时避免参数类型的信息丢失和多余的复制。
对于这部分,可以用c++中自带的delctype()解决:
int main(){
int a = 1;
int &b = a;
int const &c = a;
decltype(a);
decltype(b);
decltype(c);
}还有一个比较重要的事情
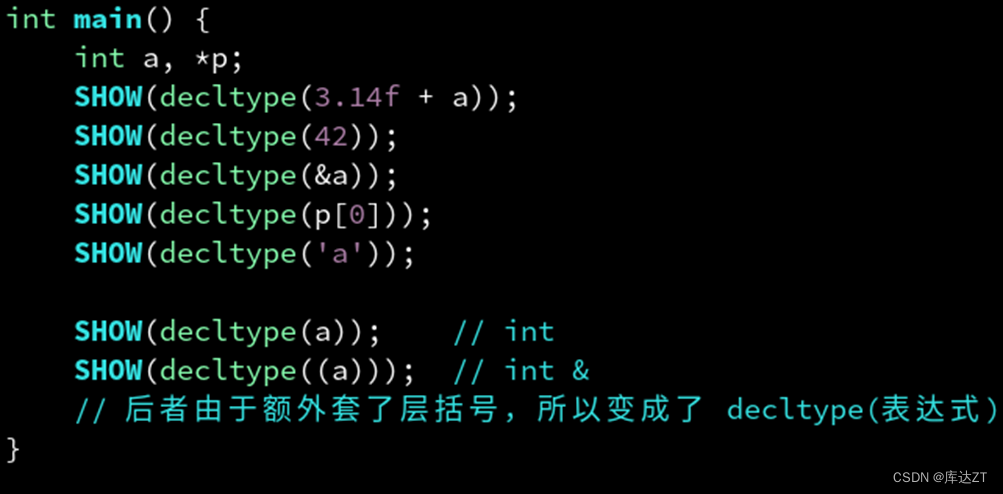
在这个里第一个是float,第二个是int,第三个是int *,第四个是int &,第五个是char
但是第六个和第七个有一些不同,是因为第六个是一个int的变量,但是第七个添加了一个括号,代表左值引用,所以是int &类型。
可以用type_traits中的 is_same_v(int const,const int)来比对两个变量名是否一样。
如果一个表达式,我不知道他是个可变引用(int &),常引用(int const &),右值引用(int &&),还是一个普通的值(int)。
但我就是想要定义一个和表达式返回类型一样的变量,这时候可以用:
decltype(auto) p = func();
会自动推导为 func() 的返回类型。
和下面这种方式等价:
decltype(func()) p = func();
那他和auto的区别在于,auto会自动decay,也就是说如果返回的是一个int &引用类型的值,那么auto会自动变成int。
//对于auto &
int &func(){}
auto &p = func() //必须func返回一个引用才不出错
int func(){}
auto &p = func() //否则这种就会出错
那么decltype(auto)就不会出现这种问题这里有一个小例子
#include <iostream>
#include <vector>
template <class T1, class T2>
auto add(std::vector<T1> const &a, std::vector<T2> const &b) {
using T0 = decltype(T1{} + T2{});
std::vector<T0> ret;
for (size_t i = 0; i < std::min(a.size(), b.size()); i++) {
ret.push_back(a[i] + b[i]);
}
return ret;
}
int main() {
std::vector<int> a = {2, 3, 4};
std::vector<float> b = {0.5f, 1.0f, 2.0f};
auto c = add(a, b);
for (size_t i = 0; i < c.size(); i++) {
std::cout << c[i] << std::endl;
}
return 0;
}函数式编程
#include <iostream>
#include <sstream>
#include <string>
using namespace std;
void print_number(int n){
cout<<"number is "<< n << endl;
}
void call_twice(void func(int)){
func(0);
func(1);
}
int main(){
call_twice(print_number);
return 0;
}也可以将模板函数带进去
#include <cstdio>
void print_float(float n) {
printf("Float %f\n", n);
}
void print_int(int n) {
printf("Int %d\n", n);
}
template<class Func>
void call_twice(Func func){
func(0);
func(1);
}
int main(){
call_twice(print_float);
call_twice(print_int);
return 0;
}但是这样很不方便,所以可以将上述写到函数里(lambda表达式)
#include <cstdio>
template <class Func>
void call_twice(Func func) {
func(0);
func(1);
}
int main(){
auto my_func = [](int n){printf("number is %d",n);};
//可以指定返回形式 比如[](int n) -> int{return n*2;};
call_twice(my_func);
return 0;
}
lambda也可以作为返回值
#include <iostream>
template <class Func>
void call_twice(Func const &func) {
std::cout << func(0) << std::endl;
std::cout << func(1) << std::endl;
std::cout << "Func 大小: " << sizeof(Func) << std::endl;
}
auto make_twice() {
return [] (int n) {
return n * 2;
};
}
int main() {
auto twice = make_twice();
call_twice(twice);
return 0;
}/*
const &(常量引用的目的)
避免不必要的复制:如果func是一个大型对象或数据结构,通过使用常量引用,可以避免将整个对象复制到函数中,而是直接传递对原始对象的引用。这样可以提高性能和避免不必要的内存开销。
保证函数内部不会修改func:由于func是常量引用,函数内部无法修改它。这可以提供一种额外的安全保证,确保func的状态在函数执行期间不会被改变。
如果你使用值传递(即不使用常量引用),也可以得到相同的结果。然而,这将导致将整个func对象进行复制,可能会产生额外的开销,尤其是对于大型对象或数据结构来说。
总结起来,使用常量引用是为了提高性能并提供额外的安全性保证,但如果你对性能没有太大要求或者Func对象是小型的,也可以使用值传递。
*/
但是要注意的是,如果作为返回值返回的话,就要避免闭包的情况
#include <iostream>
template <class Func>
void call_twice(Func const &func) {
std::cout << func(0) << std::endl;
std::cout << func(1) << std::endl;
std::cout << "Func 大小: " << sizeof(Func) << std::endl;
//这样func的大小就是8,因为指针大小就是8
}
auto make_twice(int fac) {
return [&] (int n) {
return n * fac;
};
}
int main() {
auto twice = make_twice(2);
call_twice(twice);
return 0;
}就比如这种情况,这是因为在调用完make_twice后,fac就释放了,那么&抓的是fac的地址,所以在make_twice返回后fac的引用就变成了内存中一块失效了的地址.
那么可以用“=”来捕捉,这样就是捕捉值而不是捕捉地址。
#include <iostream>
template <class Func>
void call_twice(Func const &func) {
std::cout << func(0) << std::endl;
std::cout << func(1) << std::endl;
std::cout << "Func 大小: " << sizeof(Func) << std::endl;
//这样func的大小就是4,因为int大小就是4
}
auto make_twice(int fac) {
return [=] (int n) {
return n * fac;
};
}
int main() {
auto twice = make_twice(2);
call_twice(twice);
return 0;
}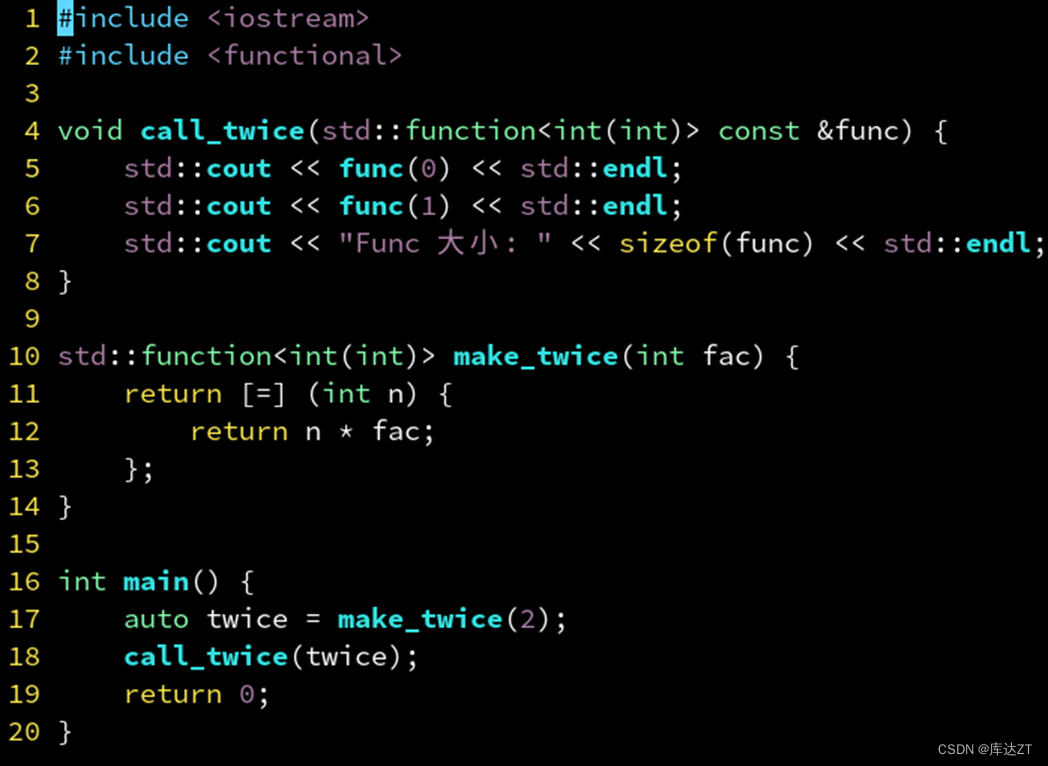
但这会牺牲一定的性能,但是存储方便。
接下来我们看一个lambda 用途举例:yield模式
这个就是将i和i+0.5分别回调32次,然后因为传入的是auto const&,所以在回调回接受的时候需要将const&这部分去除掉,之后用is_same_v判断属于什么类型,之后分别加入到不同的容器里。因为这个is_same_v , decay_t传入的都是编译期常量。所以可以在前面加入constexpr。从而在编译器角度优化。
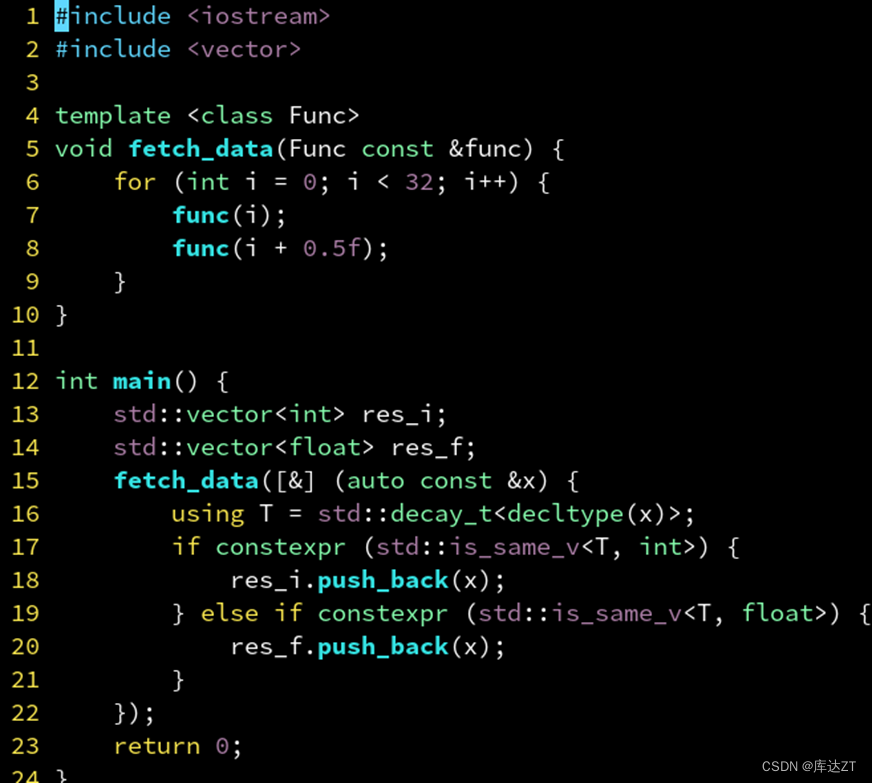
Tuple:
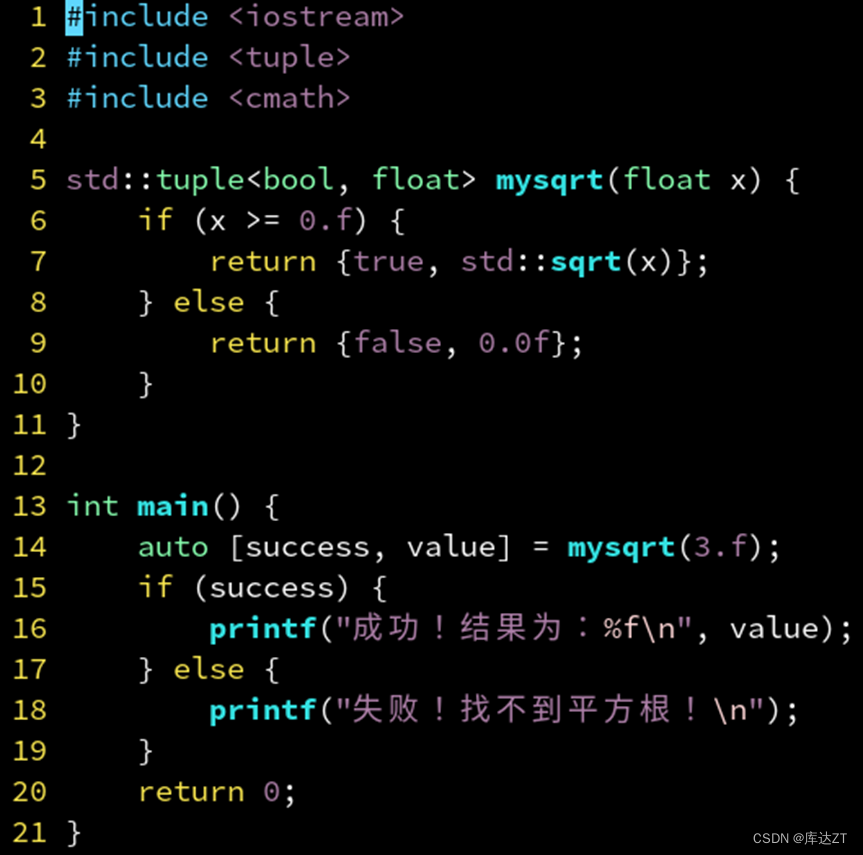
Optional
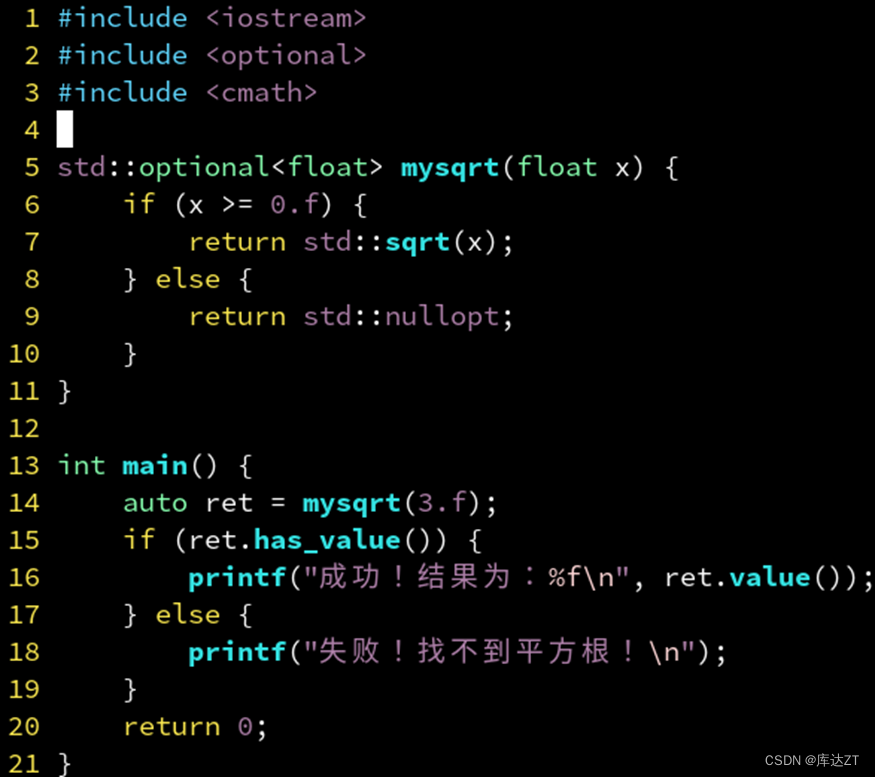
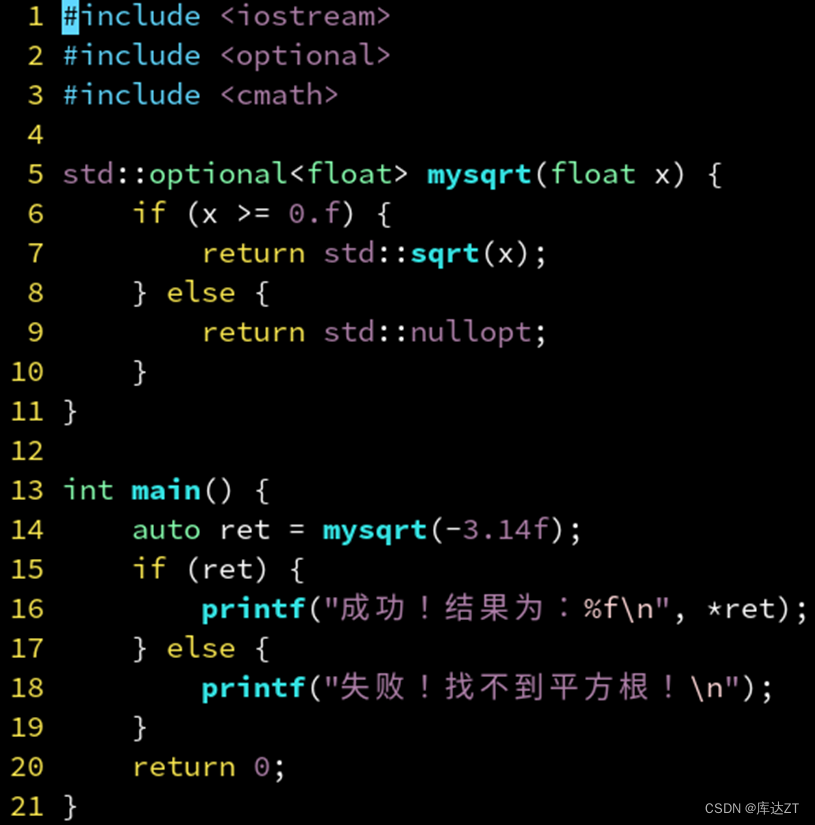
•在 if 的条件表达式中,其实可以直接写 if (ret),他和 if (ret.has_value()) 等价。
没错,这样看来 optional 是在模仿指针,nullopt 则模仿 nullptr。但是他更安全,且符合 RAII 思想,当设为 nullopt 时会自动释放内部的对象。
利用这一点可以实现 RAII 容器的提前释放。和 unique_ptr 的区别在于他的对象存储在栈上,效率更高。
终于写完了,断断续续写了将近一下午加一晚上,这一节东西确实太多了,得好好消化消化















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









