







// CUDA驱动头文件cuda.h
#include <cuda.h>
#include <stdio.h>
#include <string.h>
int main(){ /*
cuInit(int flags), 这里的flags目前必须给0;
对于cuda的所有函数,必须先调用cuInit,否则其他API都会返回CUDA_ERROR_NOT_INITIALIZED
https://docs.nvidia.com/cuda/archive/11.2.0/cuda-driver-api/group__CUDA__INITIALIZE.html
*/
CUresult code=cuInit(0); //CUresult 类型:用于接收一些可能的错误代码
if(code != CUresult::CUDA_SUCCESS){
const char* err_message = nullptr;
cuGetErrorString(code, &err_message); // 获取错误代码的字符串描述
// cuGetErrorName (code, &err_message); // 也可以直接获取错误代码的字符串
printf("Initialize failed. code = %d, message = %s\n", code, err_message);
return -1;
}
/*
测试获取当前cuda驱动的版本
显卡、CUDA、CUDA Toolkit
1. 显卡驱动版本,比如:Driver Version: 460.84
2. CUDA驱动版本:比如:CUDA Version: 11.2
3. CUDA Toolkit版本:比如自行下载时选择的10.2、11.2等;这与前两个不是一回事, CUDA Toolkit的每个版本都需要最低版本的CUDA驱动程序
三者版本之间有依赖关系, 可参照https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
nvidia-smi显示的是显卡驱动版本和此驱动最高支持的CUDA驱动版本
*/
int driver_version = 0;
code = cuDriverGetVersion(&driver_version); // 获取驱动版本
printf("CUDA Driver version is %d\n", driver_version); // 若driver_version为11020指的是11.2
// 测试获取当前设备信息
char device_name[100]; // char 数组
CUdevice device = 0;
code = cuDeviceGetName(device_name, sizeof(device_name), device); // 获取设备名称、型号如:Tesla V100-SXM2-32GB // 数组名device_name当作指针
printf("Device %d name is %s\n", device, device_name);
return 0;
}cuInit是一个 driver api 用来返回的是调用成功或者失败
curesult 是一个接受类型。
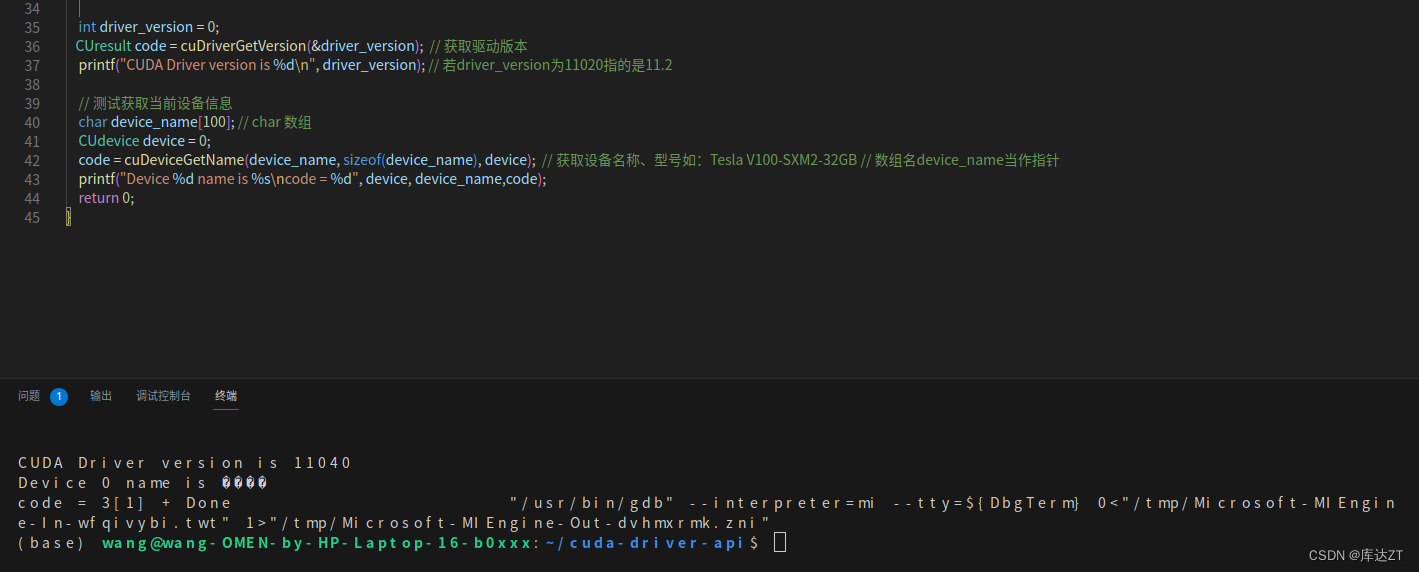
可以看到如果没有经历cuInit那么返回的类型会是3,这个cunit枚举类型中的3对应着的是没有初始化。

作为保险,可以自定义cudacheck
// 使用有参宏定义检查cuda driver是否被正常初始化, 并定位程序出错的文件名、行数和错误信息
// 宏定义中带do...while循环可保证程序的正确性
#define checkDriver(op) \
do{ \
auto code = (op); \
if(code != CUresult::CUDA_SUCCESS){ \
const char* err_name = nullptr; \
const char* err_message = nullptr; \
cuGetErrorName(code, &err_name); \
cuGetErrorString(code, &err_message); \
printf("%s:%d %s failed. \n code = %s, message = %s\n", __FILE__, __LINE__, #op, err_name, err_message); \
return -1; \
} \
}while(0)
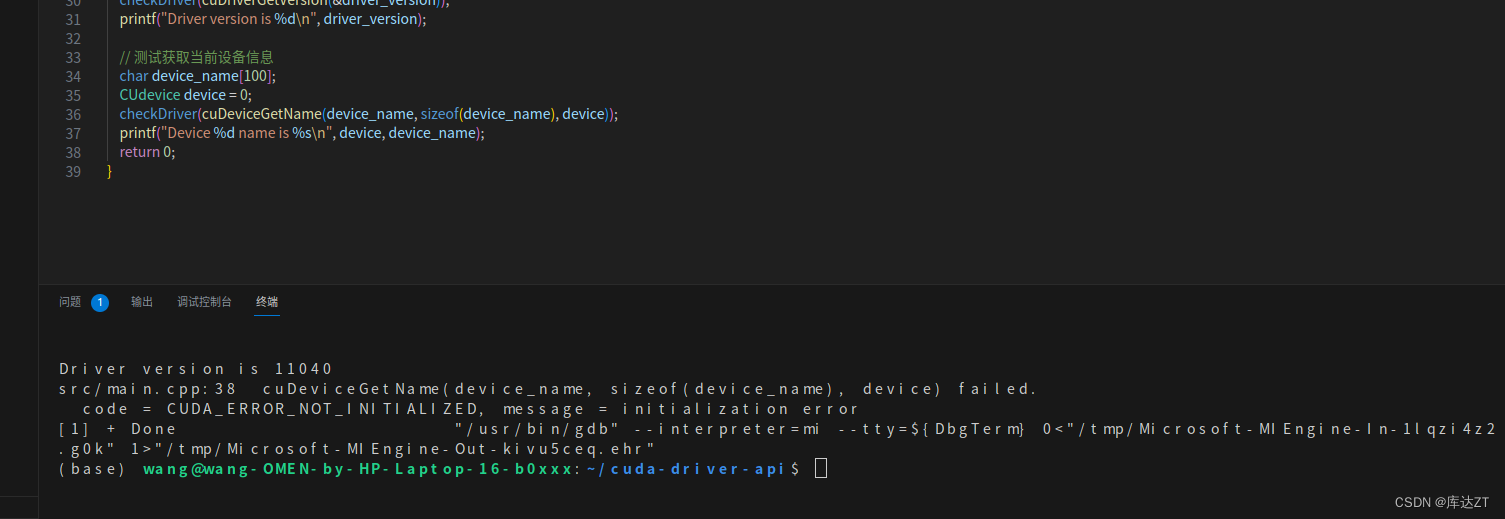
通过这种check就可以快速告诉我需要查找什么问题。但是这样的check对于一些返回不是整数的效果就不是很好了(因为return-1)。
所以需要进一步完善check这个功能:
#define checkDriver(op) __check_cuda_driver((op), #op, __FILE__, __LINE__)
bool __check_cuda_driver(CUresult code, const char* op, const char* file, int line){
if(code != CUresult::CUDA_SUCCESS){
const char* err_name = nullptr;
const char* err_message = nullptr;
cuGetErrorName(code, &err_name);
cuGetErrorString(code, &err_message);
printf("%s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}这里返回的是一个bool类型的值。很明显,这种结构的返回之更加的友好。
在runtime中也可以用这种,与上面的没什么大的区别。
#define CHECK(call)\
{\
const cudaError_t error=call;\
if(error!=cudaSuccess)\
{\
printf("ERROR: %s:%d,",__FILE__,__LINE__);\
printf("code:%d,reason:%s\n",error,cudaGetErrorString(error));\
exit(1);\
}\
}CUDA 的运行时函数和驱动程序函数在执行后会返回一个 cudaError_t 类型的值,用于指示函数执行的结果。这个返回值可以是 cudaSuccess(函数执行成功)或者其他不同的错误代码,表示函数执行时发生了错误。
CUDA 运行时函数包括对设备内存的分配、数据传输、核函数的调用等操作,而驱动程序函数涉及到 CUDA 驱动程序的管理和配置。无论是运行时函数还是驱动程序函数,它们都会在执行后返回一个 cudaError_t 类型的值。
CUcontext:
context是一种上下文,关联对GPU的所有操作。
/*
CUcontext实际上是一个指向CUDA上下文对象的指针。通过使用该指针,可以对CUDA上下文进行创建、配置、销毁和管理等操作。
例如,在先前的代码示例中,我们声明了一个名为context的指针变量,并使用cuCtxCreate函数将创建的上下文对象的地址赋值给该指针:
CUcontext context;
cuCtxCreate(&context, CU_CTX_SCHED_AUTO, 0);
然后,我们可以通过该指针进行进一步的操作,如释放上下文资源:
cuCtxDestroy(context);
*/
每个线程都有一个栈结构来存储context ,栈顶是当前使用的context,对应有push、pop等操作。所有的api都以当前的context为操作目标。
没有context:
cuMalloc(device , &ptr , 100);
cuFree(device ,ptr);
cuMemcpy(device , dst ,src,100);
有context:
ceCreateContext(device , &context);
cuPushCurent(context);
cuMalloc(&ptr , 100);
cuFree(ptr);
cuMemcpy(dst , src ,100);
cuPopCurrent(context);可以看到加入了context之后系统更加简洁,并且对于整体的封装性也更好。
而由于高频的操作,所以对于设备而言,基本是一个线程固定访问一个显卡的,就是只是用一个context,很少会用到多个context。在这种情况下再一个个push、pop就很麻烦,所以推出了cuDevicePrimaryCtxRetain(),他是一个给他设备id,自动配置context,就是一个显卡对应一个primary context.不同的线程,只要设备id一样,那就是一样的primary context。
而且context线程安全。
用context:
ceCreateContext(device , &context);
cuPushCurent(context);
cuMalloc(&ptr , 100);
cuFree(ptr);
cuMemcpy(dst , src ,100);
cuPopCurrent(context);
用primaryctxretain:
cuDevicePrimaryCttxRetain(device &context)
cuMalloc(&ptr , 100);
cuFree(ptr);
cuMemcpy(dst , src ,100);而且所有的runtime api都是基于cuDevicePrimaryCtxRetain的。
int main(){
// 检查cuda driver的初始化
checkDriver(cuInit(0));
// 为设备创建上下文
CUcontext ctxA = nullptr; // CUcontext 其实是 struct CUctx_st*(是一个指向结构体CUctx_st的指针)
CUcontext ctxB = nullptr;
CUdevice device = 0;
checkDriver(cuCtxCreate(&ctxA, CU_CTX_SCHED_AUTO, device)); // 这一步相当于告知要某一块设备上的某块地方创建 ctxA 管理数据。输入参数 参考 https://www.cs.cmu.edu/afs/cs/academic/class/15668-s11/www/cuda-doc/html/group__CUDA__CTX_g65dc0012348bc84810e2103a40d8e2cf.html
checkDriver(cuCtxCreate(&ctxB, CU_CTX_SCHED_AUTO, device)); // 参考 1.ctx-stack.jpg
printf("ctxA = %p\n", ctxA);
printf("ctxB = %p\n", ctxB);
/*
contexts 栈:
ctxB -- top <--- current_context
ctxA
...
*/
// 获取当前上下文信息
CUcontext current_context = nullptr;
checkDriver(cuCtxGetCurrent(¤t_context)); // 这个时候current_context 就是上面创建的context
printf("current_context = %p\n", current_context);
// 可以使用上下文堆栈对设备管理多个上下文
// 压入当前context
checkDriver(cuCtxPushCurrent(ctxA)); // 将这个 ctxA 压入CPU调用的thread上。专门用一个thread以栈的方式来管理多个contexts的切换
checkDriver(cuCtxGetCurrent(¤t_context)); // 获取current_context (即栈顶的context)
printf("after pushing, current_context = %p\n", current_context);
/*
contexts 栈:
ctxA -- top <--- current_context
ctxB
...
*/
// 弹出当前context
CUcontext popped_ctx = nullptr;
checkDriver(cuCtxPopCurrent(&popped_ctx)); // 将当前的context pop掉,并用popped_ctx承接它pop出来的context
checkDriver(cuCtxGetCurrent(¤t_context)); // 获取current_context(栈顶的)
printf("after poping, popped_ctx = %p\n", popped_ctx); // 弹出的是ctxA
printf("after poping, current_context = %p\n", current_context); // current_context是ctxB
checkDriver(cuCtxDestroy(ctxA));
checkDriver(cuCtxDestroy(ctxB));
//更推荐使用cuDevicePrimaryCtxRetain获取与设备关联的context
//注意这个重点,以后的runtime也是基于此, 自动为设备只关联一个context
checkDriver(cuDevicePrimaryCtxRetain(&ctxA, device)); // 在 device 上指定一个新地址对ctxA进行管理
printf("ctxA = %p\n", ctxA);
checkDriver(cuDevicePrimaryCtxRelease(device));
return 0;
}
首先是先拿到了ctxA和ctxB的地址。然后由于cuCtxCreate会自动做一个push,所以闲谈出来的是b的地址,然后重新pushctxA进去,拿到ctxA的地址。
然后最重要的就是这个
checkDriver(cuDevicePrimaryCtxRetain(&ctxA, device)); // 在 device 上指定一个新地址对ctxA进行管理
printf("ctxA = %p\n", ctxA);
checkDriver(cuDevicePrimaryCtxRelease(device));
return 0;cuDevicePrimaryCtxRetain 函数用于增加设备的主上下文的引用计数,以便继续使用已经创建的上下文。而 cuDevicePrimaryCtxRelease 函数用于减少设备的主上下文的引用计数。
在代码中,通过 cuDevicePrimaryCtxRetain 获取设备关联的主上下文,并将其地址赋给 ctxA 变量。接着打印了 ctxA 的地址,和预期结果相符。
最后,通过 cuDevicePrimaryCtxRelease 减少设备的主上下文的引用计数,来释放这个上下文。
destroy只是干掉了context的create部分,不是真的干掉了ctxA。
Memory
int main(){
// 检查cuda driver的初始化
checkDriver(cuInit(0));
// 创建上下文
CUcontext context = nullptr;
CUdevice device = 0;
checkDriver(cuCtxCreate(&context, CU_CTX_SCHED_AUTO, device));
printf("context = %p\n", context);
// 输入device prt向设备要一个100 byte的线性内存,并返回地址
CUdeviceptr device_memory_pointer = 0;
checkDriver(cuMemAlloc(&device_memory_pointer, 100)); // 注意这是指向device的pointer,
printf("device_memory_pointer = %p\n", device_memory_pointer);
// 输入二级指针向host要一个100 byte的锁页内存,专供设备访问。参考 2.cuMemAllocHost.jpg 讲解视频:https://v.douyin.com/NrYL5KB/
float* host_page_locked_memory = nullptr;
checkDriver(cuMemAllocHost((void**)&host_page_locked_memory, 100));
printf("host_page_locked_memory = %p\n", host_page_locked_memory);
// 向page-locked memory 里放数据(仍在CPU上),可以让GPU可快速读取
host_page_locked_memory[0] = 123;
printf("host_page_locked_memory[0] = %f\n", host_page_locked_memory[0]);
/*
记住这一点
host page locked memory 声明的时候为float*型,可以直接转换为device ptr,这才可以送给cuda核函数(利用DMA(Direct Memory Access)技术)
初始化内存的值: cuMemsetD32 ( CUdeviceptr dstDevice, unsigned int ui, size_t N )
初始化值必须是无符号整型,因此需要将new_value进行数据转换:
但不能直接写为:(int)value,必须写为*(int*)&new_value, 我们来分解一下这条语句的作用:
1. &new_value获取float new_value的地址
(int*)将地址从float * 转换为int*以避免64位架构上的精度损失
*(int*)取消引用地址,最后获取引用的int值
*/
float new_value = 555;
checkDriver(cuMemsetD32((CUdeviceptr)host_page_locked_memory, *(int*)&new_value, 1)); //??? cuMemset用来干嘛?
printf("host_page_locked_memory[0] = %f\n", host_page_locked_memory[0]);
/*
CUresult CUDAAPI cuMemsetD32(CUdeviceptr dstDevice, unsigned int ui, size_t N);
N 是 number of element
*/
// 释放内存
checkDriver(cuMemFreeHost(host_page_locked_memory));
return 0;
}cuMemAllocHost: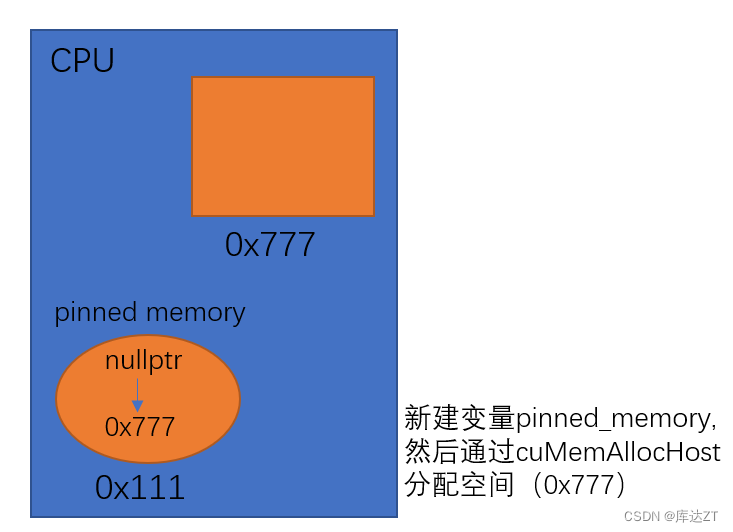
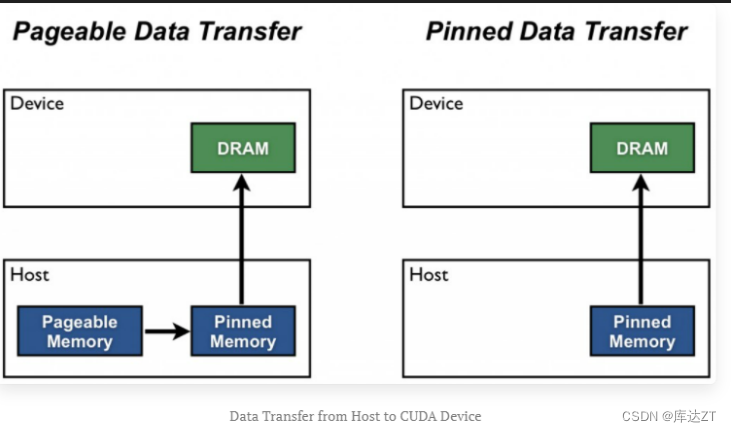
锁页内存则是一种特定于内存管理的机制,用于提高数据在内存和设备之间的传输性能。它涉及将内存页面锁定在物理内存中,以阻止操作系统进行页面交换和调度,从而减少数据传输的延迟和性能损失。锁页内存通常在涉及GPU加速计算、高性能网络传输等场景下使用,旨在优化数据访问和传输的性能。















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









