






一、背景
Mongodb数据库,有个160w数据量规模的集合,字段多达几十个,随着需求的迭代,查询条件也是五花八门。
为了提高某个查询的效率,结果都以新增索引解决问题,最后多达16个索引。
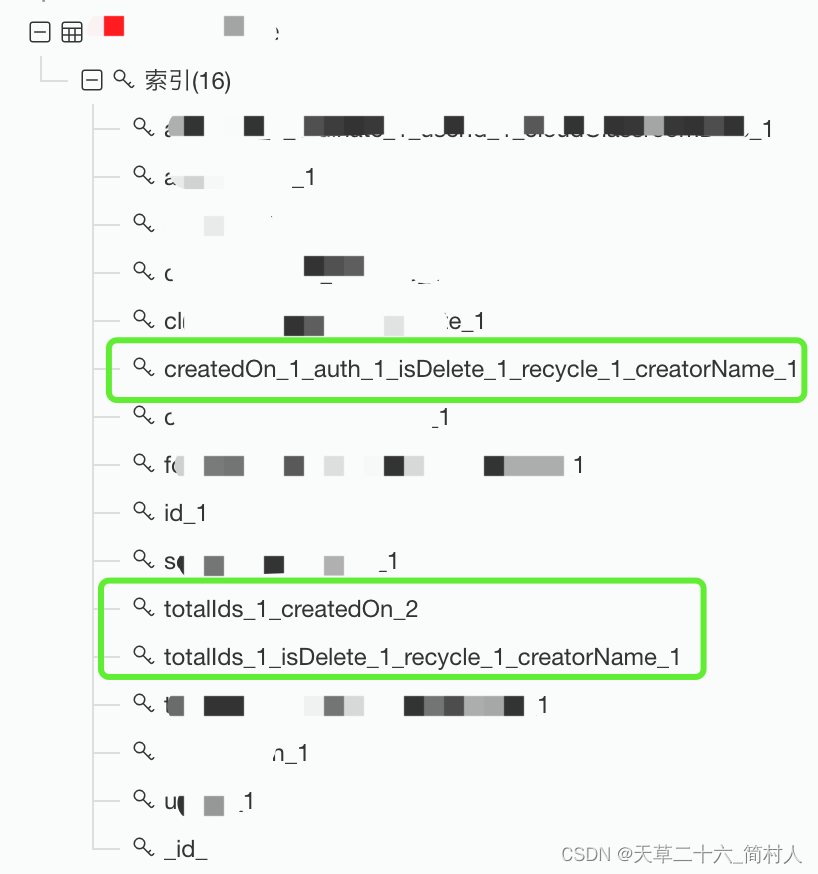
这里仅贴出本文会提及的索引,可以看到,都是组合索引。
且不说索引越多,更新记录的时候会越耗时,查询想要匹配索引的时候却找不到想要的索引。
主要的害处是,一个查询语句不知道将会匹配哪个索引,既有单个索引,又有许多类似的组合索引。
本文主要是由一个慢查询语句抛出问题,先分析执行计划,然后给出优化建议。
二、定义mongodb集合和索引
| 字段名 | 类型 | 描述 | 示例 |
|---|---|---|---|
| createdOn | Date | 创建时间 | ISODate(“2024-04-28T00:00:00.000Z”) |
| classroomName | String | 名称 | 英语期末考前复习课程 |
| creatorName | String | 创建者名称 | 张三 |
| totalIds | List | 人员集合 | [10001,10002,10003] |
| isDelete | Boolean | 是否逻辑删除 | true/false |
| recycle | int | 回收标记 | 0-未回收,1-已回收 |
| auth | int | 公开标记 | 0-否,1-是 |
前后定义了16个索引,这里列出本文会涉及到的三个索引。
- createdOn_1_auth_1_isDelete_1_recycle_1_creatorName_1
- totalIds_1_isDelete_1_recycle_1_creatorName_1
- totalIds_1_createdOn_2
三、慢查询分析
从阿里云Mongodb的慢日志,找到是哪个慢语句。
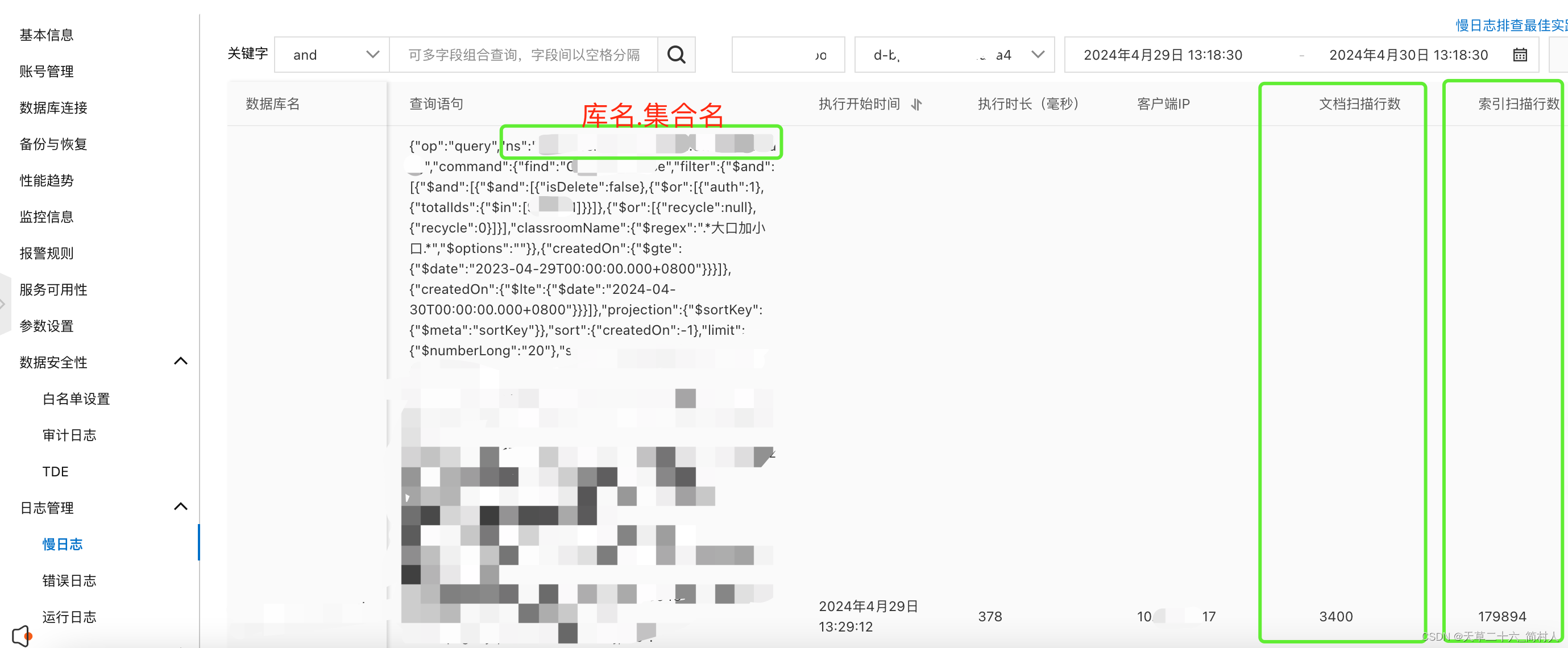
找到command命令,见下:
{"$and":[{"$and":[{"$and":[{"isDelete":false},
{"$or":[{"auth":1},{"totalIds":{"$in":[10001]}}]},
{"$or":[{"recycle":null},{"recycle":0}]}],
"classroomName":{"$regex":".*大口加小口.*","$options":""}},
{"createdOn":{"$gte":{"$date":"2023-04-29T00:00:00.000+0800"}}}]},
{"createdOn":{"$lte":{"$date":"2024-04-30T00:00:00.000+0800"}}}]},
"projection":{"$sortKey":{"$meta":"sortKey"}},
"sort":{"createdOn":-1},
"limit":{"$numberLong":"20"}
解析下这个查询语句的业务需求:
用户10001查询近一年的公开课或自己的课程,查询条件是课程名称正则匹配。(另外必须是未删除且未被放入回收站的课程)
1、真实的查询语句
db.{集合名}.find(
{
"$and": [
{
"$and": [
{ "isDelete": false },
{
"$or": [
{ "auth": 1 },
{ "totalIds": { "$in": [10001] } }
]
},
{
"$or": [
{ "recycle": null },
{ "recycle": 0 }
]
},
{
"classroomName": { "$regex": ".*大口加小口.*", "$options": "" }
},
{
"createdOn": {
"$gte": ISODate("2023-04-29T00:00:00.000Z")
}
}
]
},
{
"createdOn": {
"$lte": ISODate("2024-04-30T00:00:00.000Z")
}
}
]
},
{
"$sortKey": { "$meta": "sortKey" }
}
).sort({ "createdOn": -1 }).limit(20);
2、执行计划
db.{集合名}.explain().find{…} 得到上面语句的执行计划。
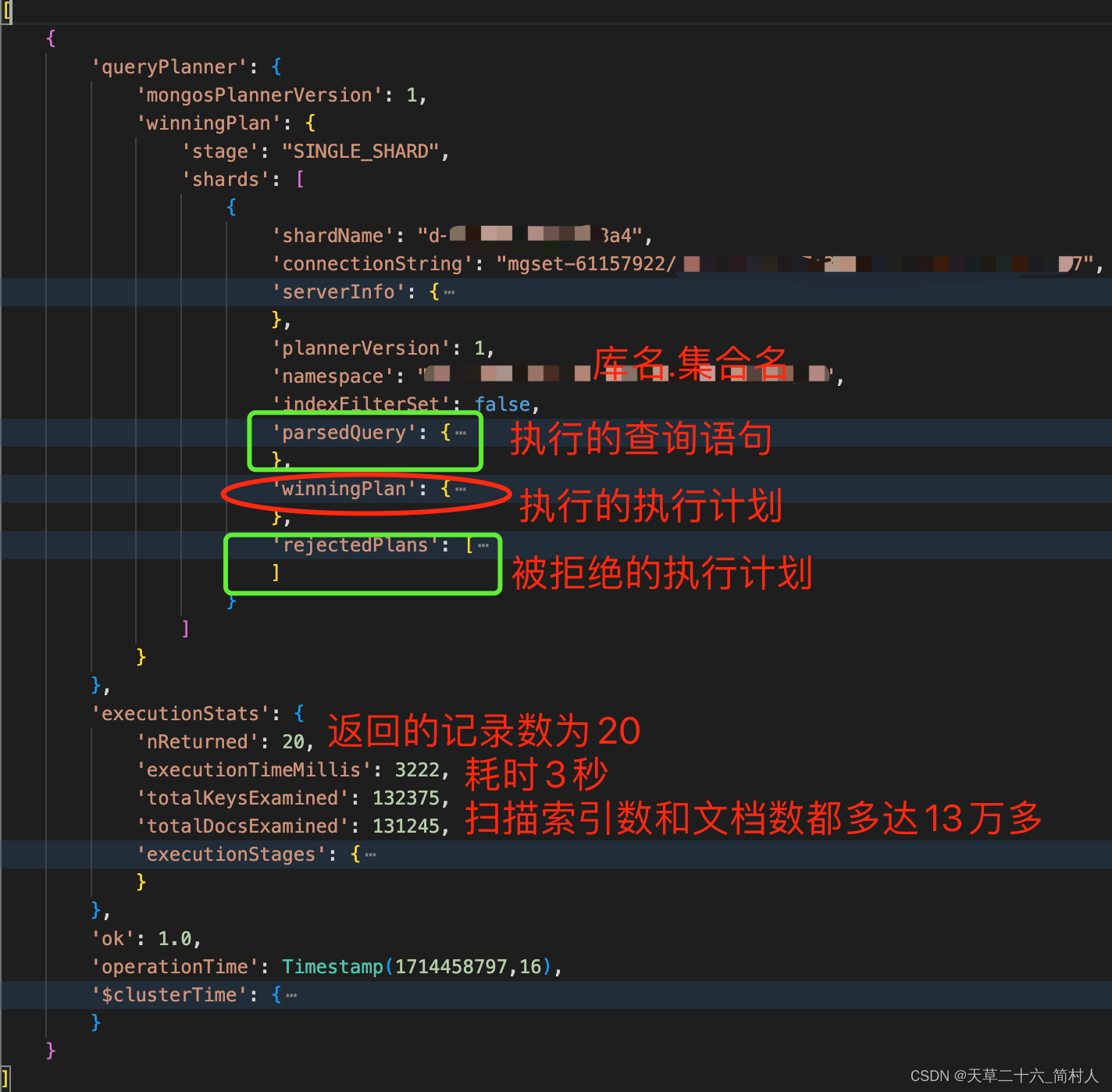 - parsedQuery :被解析的查询语句(不包括分页和排序)
- parsedQuery :被解析的查询语句(不包括分页和排序)
- winningPlan:选择的执行计划
- rejectedPlans:被拒的执行计划
- executionStats:执行分析(重点)
下面重点看executionStats部分:
由内到外的步骤分别是: IXSCAN -> FETCH -> SORT_KEY_GENERATOR -> PROJECTION -> LIMIT -> SINGLE_SHARD。
'executionStats': {
'nReturned': 20,
'executionTimeMillis': 3222,
'totalKeysExamined': 132375,
'totalDocsExamined': 131245,
'executionStages': {
'stage': "SINGLE_SHARD",
'nReturned': 20,
'executionTimeMillis': 3222,
'totalKeysExamined': 132375,
'totalDocsExamined': 131245,
'totalChildMillis': NumberLong("3219"),
'shards': [
{
'shardName': "d-bp1cef3c8241a8a4",
'executionSuccess': true,
'executionStages': {
'stage': "LIMIT",
'nReturned': 20,
'executionTimeMillisEstimate': 684,
'works': 132377,
'advanced': 20,
'needTime': 132356,
'needYield': 0,
'saveState': 6205,
'restoreState': 6205,
'isEOF': 1,
'invalidates': 0,
'limitAmount': 20,
'inputStage': {
'stage': "PROJECTION",
'nReturned': 20,
'executionTimeMillisEstimate': 678,
'works': 132376,
'advanced': 20,
'needTime': 132356,
'needYield': 0,
'saveState': 6205,
'restoreState': 6205,
'isEOF': 0,
'invalidates': 0,
'transformBy': {
'$sortKey': {
'$meta': "sortKey"
}
},
'inputStage': {
'stage': "SORT_KEY_GENERATOR",
'nReturned': 20,
'executionTimeMillisEstimate': 675,
// 略
'inputStage': {
'stage': "FETCH",
'filter': {
// 略
},
'nReturned': 20,
'executionTimeMillisEstimate': 672,
// 略
'inputStage': {
'stage': "IXSCAN",
'nReturned': 131245,
'executionTimeMillisEstimate': 89,
// 略
}
}
}
}
}
}
]
}
}
下面从内到外看其步骤:
- IXSCAN
IXSCAN/索引扫描,因为createdOn匹配到索引createdOn_1_auth_1_isDelete_1_recycle_1_creatorName_1,返回记录数为132375。同时,也可以看到它的耗时在几个阶段中,还算是比较快的–89毫秒。
'stage': "IXSCAN",
'nReturned': 131245,
'executionTimeMillisEstimate': 89,
'works': 132375,
'advanced': 131245,
'needTime': 1130,
'needYield': 0,
'saveState': 6205,
'restoreState': 6205,
'isEOF': 0,
'invalidates': 0,
'keyPattern': {
'createdOn': 1.0,
'auth': 1.0,
'isDelete': 1.0,
'recycle': 1.0,
'creatorName': 1.0
},
'indexName': "createdOn_1_auth_1_isDelete_1_recycle_1_creatorName_1",
'isMultiKey': false,
'multiKeyPaths': {
'createdOn': [
],
'auth': [
],
'isDelete': [
],
'recycle': [
],
'creatorName': [
]
},
'isUnique': false,
'isSparse': false,
'isPartial': false,
'indexVersion': 2,
'direction': "backward", // 倒序查询
'indexBounds': {
'createdOn': [
"[new Date(1714348800000), new Date(1682640000000)]"
],
'auth': [
"[MaxKey, MinKey]"
],
'isDelete': [
"[false, false]"
],
'recycle': [
"[MaxKey, MinKey]"
],
'creatorName': [
"[MaxKey, MinKey]"
]
},
'keysExamined': 132375,
'seeks': 1131,
'dupsTested': 0,
'dupsDropped': 0,
'seenInvalidated': 0
- FETCH
根据索引检索指定的文档,上一步是对查询条件createdOn、isDelete和recycle进行检索。FETCH则是基于索引数据进行再次检索,条件是两个or查询条件和classroomName模糊查找。
'stage': "FETCH",
'filter': {
'$and': [
{
'$or': [
{
'auth': {
'$eq': 1
}
},
{
'totalIds': {
'$eq': 10001
}
}
]
},
{
'$or': [
{
'recycle': {
'$eq': null
}
},
{
'recycle': {
'$eq': 0
}
}
]
},
{
'classroomName': {
'$regex': ".*大口加小口.*"
}
}
]
},
'nReturned': 20,
'executionTimeMillisEstimate': 672,
'works': 132375,
'advanced': 20,
'needTime': 132355,
'needYield': 0,
'saveState': 6205,
'restoreState': 6205,
'isEOF': 0,
'invalidates': 0,
'docsExamined': 131245,
'alreadyHasObj': 0,
'inputStage': {
'stage': "IXSCAN",
'nReturned': 131245,
'executionTimeMillisEstimate': 89,
// 略
}
- SORT_KEY_GENERATOR
返回20条数据,耗时675毫秒,所以说排序很耗时,从这里也可以看到了。它对13万多条数据进行排序,最后得到想要的20条记录,花费的时间堪比上一步FETCH了。
'stage': "SORT_KEY_GENERATOR",
'nReturned': 20,
'executionTimeMillisEstimate': 675,
'works': 132376,
'advanced': 20,
'needTime': 132356,
'needYield': 0,
'saveState': 6205,
'restoreState': 6205,
'isEOF': 0,
'invalidates': 0,
'inputStage': {
'stage': "FETCH",
'filter': {
// 略
},
'nReturned': 20,
'executionTimeMillisEstimate': 672,
// 略
'inputStage': {
'stage': "IXSCAN",
'nReturned': 131245,
'executionTimeMillisEstimate': 89,
// 略
}
}
}
其他stage就不继续往后展开了,这里总结一下,这个查询语句虽然匹配了索引,但是因为是近一年的时间区间,匹配到的索引,但数据量也很大,导致最后查询慢。
是什么原因导致没有匹配另外的索引 totalIds_1_isDelete_1_recycle_1_creatorName_1 呢?
我们后面专门为此建立的组合索引 totalIds_1_createdOn_2 也是没有被匹配上。
这主要是因为totalIds查询条件是在or里面,见下:

如果我们想要对totalIds使用上索引,这也提醒我们在平常编程的时候,不能放在or查询条件里。
下一篇文章,我们将对查询条件进行调整,试着匹配包含totalIds字段的组合索引。
四、总结
本文对线上出现的一个mongodb慢查询,分析了其执行计划,也让我们知道了,要提高查询效率,不仅要求匹配索引,还要考虑排序可能带来的性能消耗。
但是,按创建时间进行排序展示数据,作为普遍的一个业务需求,我们不能在jvm内存里排序,所以不仅要对创建时间建立组合索引,更要把它放在组合索引的末尾。
















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











