







任何深度学习都是从数据开始的,这是关键点。没有数据,就无法训练模型,也无法评估模型质量,更无法做出预测,因此,数据源非常重要。在做研究、构建新的神经网络架构、以及做实验时,会习惯于使用最简单的本地数据源,通常是不同格式的文件,这种方法确实非常有效。但有时需要更加接近于生产环境,那么简化和加速生产数据的反馈,以及能够处理大数据就变得非常重要,这时就需要Apache Ignite大展身手了。
Apache Ignite是以内存为中心的分布式数据库、缓存,也是事务性、分析性和流式负载的处理平台,可以实现PB级的内存级速度。借助Ignite和TensorFlow之间的现有集成,可以将Ignite用作神经网络训练和推理的数据源,也可以将其用作分布式训练的检查点存储和集群管理器。
分布式内存数据源
作为以内存为中心的分布式数据库,Ignite可以提供快速数据访问,摆脱硬盘的限制,在分布式集群中存储和处理需要的所有数据,可以通过使用Ignite Dataset来利用Ignite的这些优势。
注意Ignite不只是数据库或数据仓库与TensorFlow之间ETL管道中的一个步骤,它还是一个HTAP(混合事务/分析处理)系统。通过选择Ignite和TensorFlow,可以获得一个能够处理事务和分析的单一系统,同时还可以获得将操作型和历史型数据用于神经网络训练和推理的能力。
下面的测试结果表明,Ignite非常适合用于单节点数据存储场景。如果存储和客户端位于同一节点,则通过使用Ignite,可以实现每秒超过850MB的吞吐量,如果存储位于与客户端相关的远程节点,则吞吐量约为每秒800MB。
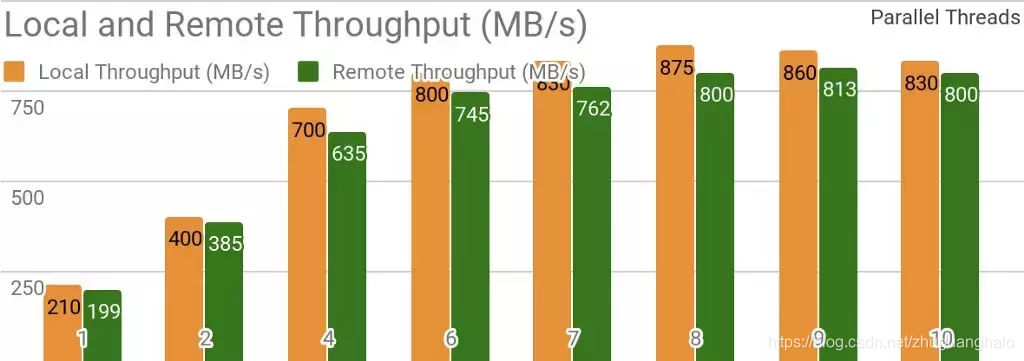
当存在一个本地Ignite节点时Ignite Dataset的吞吐量。执行该基准测试时使用的是2个Xeon E5–2609 v4 1.7GHz处理器,配备 16GB内存和每秒10Gb的网络(1MB的行和20MB 的页面大小)
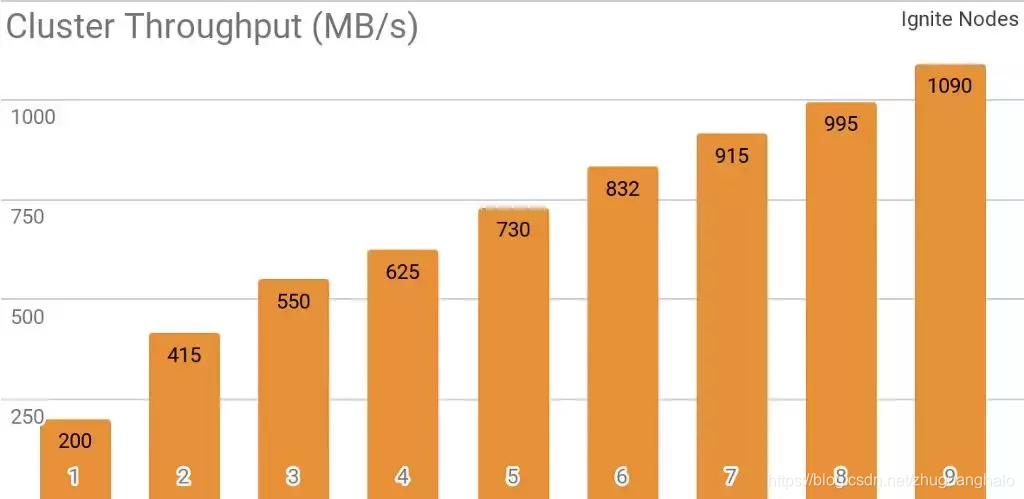
另一个测试显示Ignite Dataset如何与分布式Ignite集群协作。这是Ignite作为HTAP系统的默认用例,它能够在每秒10Gb的网络集群上为单个客户端实现每秒超过1GB的读取吞吐量。
分布式Ignite集群具备不同数量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









