







今天我们就来讨论一下LeNet的模型建立及实现。
先来看一下LeNet的结构图。由图中可得到其结构分别为输入层、s1、c1、s2、c2和输出层。
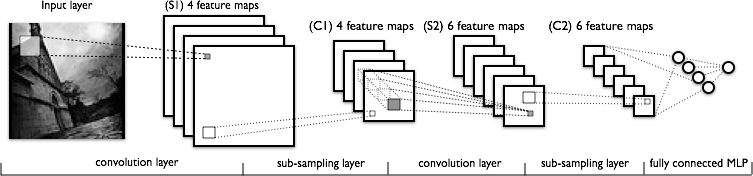
其中,输入层到s1是卷积运算;输入层输入数据batch_size个样本,每个样本是一个
28∗28
的图片,s1层滤波器大小为
5∗5
,滤波器为20个。
经过卷积运算,s1的特征图数目为20个,每个特征图的大小为
(28−5+1)∗(28−5+1)=24∗24
。为什么会是这个样子呢?这就涉及到卷积运算是怎么回事了。卷积运算一个最重要的特点就是可以使原信号特征增强,并且能降低噪音。具体运算过程,请移步这里。
当计算完第一组
5∗5
区域后(比如计算的是原数据第一行下标0-4,第一列0-4构成的方阵),
5∗5
的滤波器整体向右移动步长=1,那么下一次就是计算原数据第一行下标1-5,第一列0-4的方阵。以此类推,原数据第一行28个数据,那么就会向右移动
(28−5+1)
次。因此,最终的结果图大小就是
(28−5+1)∗(28−5+1)
。如何还不太清楚,可以自己手动画一下,画一个4*4的原数据,
2∗2
的滤波器,最终生成的图像大小为
(4−2+1)∗(4−2+1)
。
下面我们计算一下s1层需要训练的参数个数:s1生成有20个特征图,每个特征图的滤波器不同,同一个特征图的滤波器相同(这不废话吗)每个特征图含
24∗24
个元素,每个元素的生成是由本图的滤波器与原图像卷积计算得出。本图的滤波器含有
5∗5
个W元素+1个b元素(共
5∗5+1=26
个参数)。那么总的计算就是:共有
20∗(5∗5+1)=520
个参数;
20∗(24∗24)∗(5∗5+1)=299520
个连接。
s1层到c1层是下采样层。计算过程就是将s1的输出数据作为c1的输入数据。因此,输入数据为20个
24∗24
的特征图。经过采样大小为
2∗2
感受野的计算后,结果仍然是20个特征图,每个特征图变为了
12∗12
。
滤波器的移动是有重叠的。而下采样是无重叠的。采样计算过程如下:结果特征图中的每一个元素对应输入特征图中的
2∗2
元素,将
2∗2
区域元素累加,然后乘以一个可训练参数,再加上一个偏置值,最后通过sigmoid函数计算得到一个数值。然后结果图的下一个元素就是输入图中下一个
2∗2
区域,以此类推。最终原图是
24∗24
的,经过下采样之后,就变成
12∗12
了(就是行和列分别是原来的一半。因此整体就是原来的1/4)。
总体就是在特征图数目不变的前提下,将每个特征图进行了类似压缩的操作,这样元素个数大大降低,这就是所谓的下采样。同样我们计算一下c1层需要训练的参数个数:c1仍然生成20个特征图,每个特征图含
12∗12
个元素,每个元素的生成是由原图的
2∗2
区域元素累加,然后乘以1个可训练参数+1个偏置b参数。相当于本图的滤波器含有
1∗1
个W元素+1个b元素(共
1∗1+1=2
个参数)。那么总的计算就是:共有
20∗(1∗1+1)=40
个参数;
20∗(12∗12)∗(2∗2+1)=14400
个连接。。
c1到s2是卷积运算;输入是batch_size个样本,每个样本是20个 12∗12 的特征图,s2层是50个滤波器,每个滤波器 5∗5 大小。然后经过卷积运算,生成50个 8∗8 的特征图。【c1与s2的全连接,但尚不清楚是如何计算的,因此未能算出其参数和连接。从其他资料经验看,应该有 20∗50∗(5∗5+1)=26000 个参数; 20∗50∗(8∗8)∗(5∗5+1)=1664000 个连接。】
s2层到c3层是下采样层,输入是50个 8∗8 特征图,采用 2∗2 感受野,结果是50个 4∗4 特征图。
c3层到输出层经过一个MLP层。输入数据是将c3的4维输出转换为2维矩阵,即把后三维 50∗4∗4 转换为行数据,送入MLP的隐层,激活函数是tanh,输出是batch_size;然后再把结果送入MLP的LR层,经过softmax函数,将结果分为10类。
至此,整个模型介绍完毕。经过注释后的代码GitHub下载 CSDN免费下载,包含2个文件:mlp.py和LeNetConvPoolLayer.py。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









