






这是一篇关于OpenAI的强化学习课程(RL)的翻译和笔记 个人学习使用。
原文链接Part 2: Kinds of RL Algorithms — Spinning Up documentation
简单记录一些笔记 并且用斜体字补充了来自chatgpt的注解(正确性注意甄别)
Table of Contents
Now that we’ve gone through the basics of RL terminology and notation, we can cover a little bit of the richer material: the landscape of algorithms in modern RL, and a description of the kinds of trade-offs that go into algorithm design.
目录
第二部分:RL算法的种类
RL算法的一个分类
链接到分类中的算法
现在我们已经学习了RL术语和符号的基本知识,我们可以涵盖一些更丰富的材料:现代RL中算法的前景,以及算法设计中各种权衡的描述。
A Taxonomy of RL Algorithms
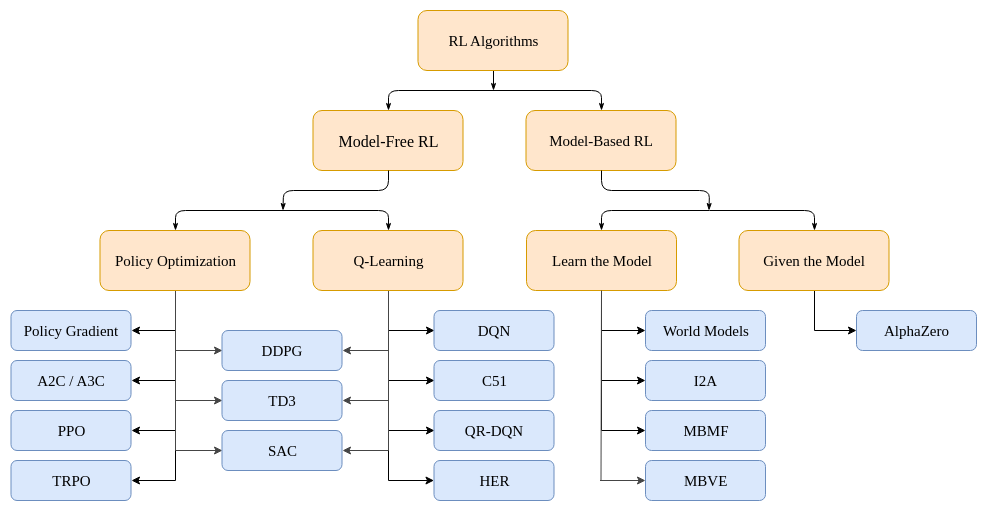
We’ll start this section with a disclaimer: it’s really quite hard to draw an accurate, all-encompassing taxonomy of algorithms in the modern RL space, because the modularity of algorithms is not well-represented by a tree structure. Also, to make something that fits on a page and is reasonably digestible in an introduction essay, we have to omit quite a bit of more advanced material (exploration, transfer learning, meta learning, etc). That said, our goals here are
我们将在本节开始时免责声明:在现代RL空间中,很难绘制出准确、包罗万象的算法分类法,因为算法的模块性并不能很好地用树结构来表示。此外,为了制作出适合页面并在引言文章中合理理解的内容,我们必须省略相当多的高级材料(探索、迁移学习、元学习等)。也就是说,我们的目标是
- to highlight the most foundational design choices in deep RL algorithms about what to learn and how to learn it,
- to expose the trade-offs in those choices,
- and to place a few prominent modern algorithms into context with respect to those choices.
为了强调深度RL算法中关于学习内容和如何学习的最基本的设计选择,
为了揭示这些选择中的权衡,
并将一些突出的现代算法放在关于这些选择的上下文中。
Model-Free vs Model-Based RL
One of the most important branching points in an RL algorithm is the question of whether the agent has access to (or learns) a model of the environment. By a model of the environment, we mean a function which predicts state transitions and rewards.
RL算法中最重要的分支点之一是代理是否可以访问(或学习)环境模型的问题。所谓环境模型,我们指的是预测状态转换和奖励的函数。
The main upside to having a model is that it allows the agent to plan by thinking ahead, seeing what would happen for a range of possible choices, and explicitly deciding between its options. Agents can then distill the results from planning ahead into a learned policy. A particularly famous example of this approach is AlphaZero. When this works, it can result in a substantial improvement in sample efficiency over methods that don’t have a model.
拥有一个模型的主要好处是,它允许代理人提前思考,看看一系列可能的选择会发生什么,并明确决定其选择。然后,代理可以将提前规划的结果提炼为习得的策略。这种方法的一个特别著名的例子是AlphaZero。当这起作用时,与没有模型的方法相比,它可以显著提高样本效率。
The main downside is that a ground-truth model of the environment is usually not available to the agent. If an agent wants to use a model in this case, it has to learn the model purely from experience, which creates several challenges. The biggest challenge is that bias in the model can be exploited by the agent, resulting in an agent which performs well with respect to the learned model, but behaves sub-optimally (or super terribly) in the real environment. Model-learning is fundamentally hard, so even intense effort—being willing to throw lots of time and compute at it—can fail to pay off.
主要的缺点是代理通常无法获得环境的基本事实模型。如果代理想在这种情况下使用模型,它必须完全从经验中学习模型,这会带来一些挑战。最大的挑战是,代理可以利用模型中的偏差,导致代理相对于学习的模型表现良好,但在真实环境中表现次优(或极其糟糕)。模型学习从根本上来说是困难的,所以即使付出巨大的努力——愿意投入大量的时间和计算——也可能得不到回报。
Algorithms which use a model are called model-based methods, and those that don’t are called model-free. While model-free methods forego the potential gains in sample efficiency from using a model, they tend to be easier to implement and tune. As of the time of writing this introduction (September 2018), model-free methods are more popular and have been more extensively developed and tested than model-based methods.
使用模型的算法称为基于模型的方法,不使用模型的称为无模型方法。虽然无模型方法放弃了使用模型在样本效率方面的潜在收益,但它们往往更容易实现和调整。截至撰写本简介之时(2018年9月),无模型方法比基于模型的方法更受欢迎,并且得到了更广泛的开发和测试。
What to Learn
Another critical branching point in an RL algorithm is the question of what to learn. The list of usual suspects includes
- policies, either stochastic or deterministic,
- action-value functions (Q-functions),
- value functions,
- and/or environment models.
What to Learn in Model-Free RL
There are two main approaches to representing and training agents with model-free RL:
Policy Optimization.
Methods in this family represent a policy explicitly as ![]() . They optimize the parameters
. They optimize the parameters ![]() either directly by gradient ascent on the performance objective
either directly by gradient ascent on the performance objective ![]() , or indirectly, by maximizing local approximations of
, or indirectly, by maximizing local approximations of ![]() . This optimization is almost always performed on-policy, which means that each update only uses data collected while acting according to the most recent version of the policy. Policy optimization also usually involves learning an approximator
. This optimization is almost always performed on-policy, which means that each update only uses data collected while acting according to the most recent version of the policy. Policy optimization also usually involves learning an approximator ![]() for the on-policy value function
for the on-policy value function ![]() , which gets used in figuring out how to update the policy.
, which gets used in figuring out how to update the policy.
策略优化是一类强化学习方法,其中的方法将策略显式地表示为 πθ(a∣s),其中 θ 是策略参数。这些方法通过梯度上升(gradient ascent)直接优化性能目标 J(πθ) 的参数 θ,或者通过最大化 J(πθ) 的局部近似间接优化这些参数。这种优化几乎总是在策略的当前版本下进行的,即每次更新只使用按照最新版本策略收集的数据。策略优化通常还涉及学习一个逼近器 Vϕ(s) 用于近似策略的状态价值函数 Vπ(s),这在确定如何更新策略时会被使用。
J(πθ) 表示给定策略参数 θ 下的性能目标,通常被定义为期望回报。换句话说,它表示在按照策略 πθ 行动时所获得的期望回报。因此,J(πθ) 可以用数学期望的形式表示,表示为:
J(πθ)=Eτ∼πθ[R(τ)]
其中,τ 是一个轨迹,表示智能体从开始到结束的状态-动作序列,R(τ) 是轨迹 τ 的总回报。这个期望是对所有可能的轨迹 τ 求取的,根据策略 πθ 和环境的动态转移来计算每个轨迹的概率。
A couple of examples of policy optimization methods are:
- A2C / A3C, which performs gradient ascent to directly maximize performance,
- and PPO, whose updates indirectly maximize performance, by instead maximizing a surrogate objective function which gives a conservative estimate for how much
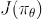 will change as a result of the update.
will change as a result of the update.
-
A2C / A3C:这些方法执行梯度上升,直接最大化性能目标 J(πθ)。A2C (Advantage Actor-Critic) 和 A3C (Asynchronous Advantage Actor-Critic) 是一类基于演员-评论家(Actor-Critic)架构的策略优化方法。演员负责学习策略,评论家负责评估策略的性能并提供反馈信号。通过梯度上升,这些方法直接优化策略的参数,以最大化期望回报。
-
PPO:PPO (Proximal Policy Optimization) 使用间接方式最大化性能,通过最大化一个替代目标函数来实现。这个目标函数提供了关于更新后 J(πθ) 可能改变的保守估计。PPO方法通过执行梯度上升来间接优化策略参数,以使这个替代目标函数最大化,从而提高性能。
Q-Learning.
Methods in this family learn an approximator ![]() for the optimal action-value function,
for the optimal action-value function, ![]() . Typically they use an objective function based on the Bellman equation. This optimization is almost always performed off-policy, which means that each update can use data collected at any point during training, regardless of how the agent was choosing to explore the environment when the data was obtained. The corresponding policy is obtained via the connection between
. Typically they use an objective function based on the Bellman equation. This optimization is almost always performed off-policy, which means that each update can use data collected at any point during training, regardless of how the agent was choosing to explore the environment when the data was obtained. The corresponding policy is obtained via the connection between ![]() and
and ![]() : the actions taken by the Q-learning agent are given by
: the actions taken by the Q-learning agent are given by
![]()
Q-learning 是强化学习中的一类方法,它们学习一个逼近器 Qθ(s,a) 用于最优动作价值函数 Q∗(s,a)。通常,它们使用基于贝尔曼方程的目标函数。这种优化几乎总是以离线策略进行,这意味着每次更新可以使用在训练过程中任意时点收集的数据,而不考虑智能体在收集数据时如何选择探索环境。通过Q^*和\pi^*之间关系获得相应的策略:Q学习代理所采取的行动由下式给出
![]()
这个方程表示在给定状态 s 下,智能体选择的动作 a 是使得动作价值函数 Qθ(s,a) 达到最大值的动作 a。换句话说,智能体会在当前状态下选择能够最大化动作价值函数值的动作。
Examples of Q-learning methods include
- DQN, a classic which substantially launched the field of deep RL,
- and C51, a variant that learns a distribution over return whose expectation is
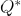 .
.
Q-learning 方法的例子包括:
-
DQN(Deep Q-Network):这是一种经典的 Q-learning 方法,它显著推动了深度强化学习领域的发展。DQN 使用深度神经网络来逼近动作价值函数 Q(s,a),并且通过最大化动作价值函数来更新网络参数。
-
C51:这是 Q-learning 方法的一种变体,它学习一个关于回报的分布,其期望值为 Q∗(s,a)。与传统的 Q-learning 方法不同,C51 通过学习一个离散的概率分布来表示动作价值函数,从而更加灵活地处理不确定性。C51 使用分布近似来代替传统的确定性动作价值函数逼近。
Trade-offs Between Policy Optimization and Q-Learning.
The primary strength of policy optimization methods is that they are principled, in the sense that you directly optimize for the thing you want. This tends to make them stable and reliable. By contrast, Q-learning methods only indirectly optimize for agent performance, by training ![]() to satisfy a self-consistency equation. There are many failure modes for this kind of learning, so it tends to be less stable. [1] But, Q-learning methods gain the advantage of being substantially more sample efficient when they do work, because they can reuse data more effectively than policy optimization techniques.
to satisfy a self-consistency equation. There are many failure modes for this kind of learning, so it tends to be less stable. [1] But, Q-learning methods gain the advantage of being substantially more sample efficient when they do work, because they can reuse data more effectively than policy optimization techniques.
策略优化(Policy Optimization)和Q-learning是两种不同的强化学习方法,它们在解决问题时有一些本质的区别:
-
目标函数的优化方式:
- 在策略优化中,目标是直接优化策略函数πθ(a∣s),以最大化期望回报 J(πθ)。策略优化方法通过梯度上升或其他优化技术来调整策略参数,使得智能体的表现得到改善。
- 而在Q-learning中,目标是间接地学习动作价值函数 Q(s,a),以最大化每个状态-动作对的期望回报。Q-learning方法通常通过递归地满足贝尔曼方程来更新动作价值函数,而不直接优化策略函数。
-
数据采样的方式:
- 策略优化方法通常是在策略的采样路径上执行梯度更新,因此是基于策略的(on-policy),这意味着每次更新只使用按照当前策略收集的数据。
- Q-learning方法通常是在离线数据上执行更新,因此是基于经验回放的(off-policy),这意味着可以重复使用先前收集的数据来进行更新,而不受当前策略的限制。
-
稳定性和收敛性:
- 策略优化方法通常更稳定,因为它们直接优化了目标,而且通常可以更容易地收敛到局部最优解。
- Q-learning方法有时候可能会出现不稳定性,尤其是在高维和复杂的环境中,可能需要额外的技巧和调整才能保持稳定性。
总的来说,策略优化和Q-learning在目标函数的优化方式、数据采样的方式以及稳定性和收敛性上有一些本质的区别,因此适用于不同类型的问题和环境。
Interpolating Between Policy Optimization and Q-Learning.
Serendipitously, policy optimization and Q-learning are not incompatible (and under some circumstances, it turns out, equivalent), and there exist a range of algorithms that live in between the two extremes. Algorithms that live on this spectrum are able to carefully trade-off between the strengths and weaknesses of either side. Examples include
- DDPG, an algorithm which concurrently learns a deterministic policy and a Q-function by using each to improve the other,
- and SAC, a variant which uses stochastic policies, entropy regularization, and a few other tricks to stabilize learning and score higher than DDPG on standard benchmarks.
这些算法位于策略优化和Q-learning之间的光谱上,能够仔细权衡两者的优势和劣势。一些例子包括:
-
DDPG(Deep Deterministic Policy Gradient):这是一种同时学习确定性策略和Q函数的算法。DDPG使用Q函数来指导策略更新,而使用策略来生成经验数据来更新Q函数。通过相互协作,DDPG能够在连续动作空间中学习高性能的策略。
-
SAC(Soft Actor-Critic):这是一种变体算法,使用了随机策略、熵正则化和其他一些技巧来稳定学习,并在标准基准测试中获得比DDPG更高的得分。SAC通过在目标函数中引入熵正则化来平衡探索和利用,从而改善了性能和稳定性。
What to Learn in Model-Based RL
Unlike model-free RL, there aren’t a small number of easy-to-define clusters of methods for model-based RL: there are many orthogonal ways of using models. We’ll give a few examples, but the list is far from exhaustive. In each case, the model may either be given or learned.
与无模型RL不同,基于模型的RL有许多易于定义的方法集群:有许多正交的使用模型的方法。我们将举几个例子,但列表远不是详尽无遗的。在每种情况下,都可以给出或学习模型。
Background: Pure Planning.
The most basic approach never explicitly represents the policy, and instead, uses pure planning techniques like model-predictive control (MPC) to select actions. In MPC, each time the agent observes the environment, it computes a plan which is optimal with respect to the model, where the plan describes all actions to take over some fixed window of time after the present. (Future rewards beyond the horizon may be considered by the planning algorithm through the use of a learned value function.) The agent then executes the first action of the plan, and immediately discards the rest of it. It computes a new plan each time it prepares to interact with the environment, to avoid using an action from a plan with a shorter-than-desired planning horizon.
最基本的方法从来没有明确地表示政策,而是使用纯粹的规划技术,如模型预测控制(MPC)来选择行动。在MPC中,每次代理观察环境时,它都会计算一个相对于模型最优的计划,其中该计划描述了在当前之后的某个固定时间窗口内采取的所有行动。(规划算法可以通过使用学习值函数来考虑超出范围的未来奖励。)然后,代理执行计划的第一个动作,并立即丢弃其余动作。每次准备与环境互动时,它都会计算一个新的计划,以避免使用规划范围短于预期的计划中的动作。
- The MBMF work explores MPC with learned environment models on some standard benchmark tasks for deep RL.
MBMF工作探索了在一些深度强化学习的标准基准任务上,使用学习的环境模型进行模型预测控制(MPC)。在这项工作中,MBMF代表了Model-Based Meta-Learning for Model Predictive Control的缩写,它的目标是通过学习环境模型来提高模型预测控制的性能。
在模型预测控制(MPC)中,智能体使用学习的环境模型来模拟未来状态的演变,并基于这些预测来制定动作策略。MBMF工作通过在标准深度强化学习基准任务上使用MPC方法,探索了使用学习环境模型的优势和挑战。这种方法旨在通过结合模型学习和控制策略优化来提高强化学习的性能和样本效率。
Expert Iteration.
A straightforward follow-on to pure planning involves using and learning an explicit representation of the policy, ![]() . The agent uses a planning algorithm (like Monte Carlo Tree Search) in the model, generating candidate actions for the plan by sampling from its current policy. The planning algorithm produces an action which is better than what the policy alone would have produced, hence it is an “expert” relative to the policy. The policy is afterwards updated to produce an action more like the planning algorithm’s output.
. The agent uses a planning algorithm (like Monte Carlo Tree Search) in the model, generating candidate actions for the plan by sampling from its current policy. The planning algorithm produces an action which is better than what the policy alone would have produced, hence it is an “expert” relative to the policy. The policy is afterwards updated to produce an action more like the planning algorithm’s output.
- The ExIt algorithm uses this approach to train deep neural networks to play Hex.
- AlphaZero is another example of this approach.
纯规划的直接后续包括使用和学习策略的显式表示,![]() 。代理在模型中使用规划算法(如蒙特卡罗树搜索),通过从计划的当前策略中采样来生成计划的候选操作。规划算法产生的行动比单独的政策产生的行动要好,因此它是相对于政策的“专家”。策略随后被更新以产生更像规划算法的输出的动作。
。代理在模型中使用规划算法(如蒙特卡罗树搜索),通过从计划的当前策略中采样来生成计划的候选操作。规划算法产生的行动比单独的政策产生的行动要好,因此它是相对于政策的“专家”。策略随后被更新以产生更像规划算法的输出的动作。
这段文字描述了一种直接建模和学习策略 πθ(a∣s) 的方法,这是纯规划(pure planning)的直接延伸。在这种方法中,智能体使用一个规划算法(如蒙特卡罗树搜索)在模型中进行规划,通过从当前策略中采样来生成计划的候选动作。规划算法生成的动作比仅使用策略本身生成的动作更好,因此相对于策略来说它是一种“专家”。随后,智能体的策略被更新,以产生更像规划算法输出的动作。
规划算法生成的动作相对于策略本身生成的动作更好的原因可以归结为以下几点:
-
长期考虑:规划算法通常会考虑更长期的奖励,而不仅仅是针对当前状态的局部最优解。它们可以通过模拟未来可能的状态和动作来预测长期回报,并相应地选择动作。
-
探索能力:规划算法可能会更好地探索环境中的未知部分,因为它们不受策略本身的限制。它们可以利用模型来尝试各种动作,并发现策略可能会忽略的潜在高回报动作。
-
信息利用:规划算法可以利用模型提供的额外信息,例如状态转移概率和奖励函数。这些信息可以帮助规划算法更准确地预测未来的奖励,并选择相应的动作。
因此,规划算法生成的动作往往比仅使用策略本身生成的动作更好,因为它们能够更全面地考虑环境和长期奖励,并利用模型提供的额外信息来做出更优的决策。
- The ExIt algorithm uses this approach to train deep neural networks to play Hex.
- AlphaZero is another example of this approach.
ExIt算法和AlphaZero都采用了这种基于规划算法的方法来训练深度神经网络玩Hex游戏。
ExIt(Expert Iteration)算法是一种增强学习算法,它结合了深度神经网络和蒙特卡罗树搜索(MCTS)。在ExIt中,深度神经网络充当策略函数,负责生成动作概率分布,而MCTS用于规划,负责在搜索树上进行长期规划和探索。通过交替地使用神经网络和MCTS来改进策略,ExIt能够在Hex等复杂游戏中取得优异的性能。
AlphaZero是DeepMind提出的一种通用的强化学习框架,它结合了深度强化学习和蒙特卡罗树搜索。AlphaZero使用单一的深度神经网络来充当策略网络和价值网络,用于生成动作概率分布和评估状态价值。同时,AlphaZero还使用MCTS来进行规划和探索,以进一步改进策略。AlphaZero在围棋、国际象棋和将棋等游戏中取得了惊人的成绩,展示了这种基于规划算法的方法在训练深度神经网络玩复杂游戏中的有效性。
Data Augmentation for Model-Free Methods.
Use a model-free RL algorithm to train a policy or Q-function, but either 1) augment real experiences with fictitious ones in updating the agent, or 2) use only fictitous experience for updating the agent.
无模型方法的数据扩充。使用无模型RL算法来训练策略或Q函数,但可以是1)在更新代理时用虚构的经验来增加真实经验,或者2)仅使用虚构的经验更新代理。
- See MBVE for an example of augmenting real experiences with fictitious ones.
- See World Models for an example of using purely fictitious experience to train the agent, which they call “training in the dream.”
-
MBVE(Model-Based Value Expansion):MBVE是一种方法,将真实经验与虚构经验相结合,以增强智能体的训练数据。它利用了模型学习的思想,通过模拟生成虚拟的经验数据,然后将这些虚拟数据与真实经验数据结合起来,用于训练智能体。这种方法可以帮助智能体更好地探索状态空间,并且在训练数据不足时提供额外的样本。
-
World Models:World Models是一种方法,它使用纯粹虚构的经验来训练智能体。这种方法被称为“在梦中训练”,因为智能体是在模拟环境中接收到的虚构体验中进行训练的。在World Models中,智能体的训练不依赖于真实的环境交互数据,而是完全依赖于通过模拟生成的虚构数据。这种方法的优点是可以快速生成大量的训练数据,并且可以在离线环境中进行训练,而不受实际环境的限制。
Embedding Planning Loops into Policies.
Another approach embeds the planning procedure directly into a policy as a subroutine—so that complete plans become side information for the policy—while training the output of the policy with any standard model-free algorithm. The key concept is that in this framework, the policy can learn to choose how and when to use the plans. This makes model bias less of a problem, because if the model is bad for planning in some states, the policy can simply learn to ignore it.
另一种方法将规划过程作为子程序直接嵌入到策略中,从而使完整的计划成为策略的辅助信息,同时使用任何标准的无模型算法训练策略的输出。关键概念是,在这个框架中,政策可以学会选择如何以及何时使用这些计划。这就减少了模型偏差的问题,因为如果模型在某些状态不适合规划,政策可以简单地学会忽略它。
- See I2A for an example of agents being endowed with this style of imagination.
I2A(Imagination-Augmented Agents)是一种方法,它赋予智能体想象力的能力。在I2A中,智能体不仅仅是基于当前环境的观察和经验做出决策,还可以利用自己内部的模型进行想象和规划。这种内部模型可以用来模拟可能的未来状态和动作序列,从而帮助智能体更好地预测环境的发展和做出更优的决策。
通过赋予智能体想象力,I2A能够使智能体更加灵活和智能。它可以帮助智能体在不确定的环境中做出更好的决策,提高智能体的性能和适应性。I2A方法的核心思想是利用想象力来拓展智能体的认知能力,使其能够更好地理解环境、预测未来和规划行动。
总结回顾:
什么是模型? 指的是环境的模型,是一个可以预测出状态转换的情况和奖励的函数。
有了模型 优势是可以让智能体通过提前思考未来的计划,看到可能选择的可能结果
缺点是通常没有很真实的模型,模型和现实之间的误差可能会让智能体的表现下降。
不用模型的一个优点是易于部署和易于训练
能不能用ADRC的理想化模型和干扰补偿的方法?
Model-free RL 的主要两个 一个是Policy Optimazation 一个是Q-Learning
其中Policy Optimazation是on policy的 通过直接的梯度上升或者间接的最大化局部估计,来优化性能指标J(pi_theta)。
主要包括的方法有A2C/A3C和PPO
其中A2C和A3C是通过梯度上升直接最大化性能
PPO是 通过最大化一个替代目标函数 间接的最大化性能 这个目标函数给出了更新对性能指标的影响的保守估计
Q-Learning 的方法是学习一个最优动作价值函数Q*的估计器Qtheta
通常是off-policy的 所以不管智能体选择如何探索环境 其数据都可以用来更新
使用Q-Learning的方法包括:
DQN 使用深度神经网络来逼近动作价值函数 Q(s,a),并且通过最大化动作价值函数来更新网络参数。
DQN(Deep Q-Network)是一种经典的深度强化学习算法,由DeepMind提出。它结合了深度神经网络和Q-learning方法,用于解决离散动作空间的马尔可夫决策过程(MDP)问题。
DQN的核心思想是使用深度神经网络来近似和学习动作值函数 Q(s,a)。这个动作值函数用于评估在给定状态下采取某个动作的预期回报。DQN的神经网络接受状态作为输入,并输出每个动作的预期回报。智能体根据这些预期回报来选择动作,并通过与环境的交互来不断更新神经网络的参数,以使预期回报尽可能地接近实际回报。
DQN的训练过程通常使用经验回放(Experience Replay)和固定Q目标(Fixed Q-Targets)来提高稳定性和收敛性。经验回放通过存储智能体与环境交互的经验数据,并随机抽样用于训练,以打破样本之间的相关性。固定Q目标则使用两个独立的神经网络来评估目标Q值和当前Q值,其中一个网络的参数是固定不变的,而另一个网络的参数在训练过程中不断更新,这样可以减少目标值的波动性,提高训练的稳定性。
DQN已经在多个领域取得了成功,特别是在解决各种Atari游戏任务中表现出色。它的简单性和高效性使得DQN成为了深度强化学习领域的重要里程碑,对后续算法的发展产生了深远影响。
C51通过学习一个离散的概率分布来表示动作价值函数,从而更加灵活地处理不确定性。C51 使用分布近似来代替传统的确定性动作价值函数逼近。
对比 Policy Optimization 是有原则的 你直接优化你想要的东西 使得他们稳定可靠
但是 Q-Learning通过训练一个Qtheta间接的优化智能体的表现 没那么稳定 但是优点再有采样效率高 因为可以重复使用数据
以上 是model free 的算法,Model-Based RL算法 是结合模型进行预测
首先基于模型的纯规划的例子就是MPC,在每个状态下基于模型计算出最好的动作,然后在下个状态再基于模型做新的计算。MBMF方法通过学习环境模型来提升RL的性能。
Model-Based的算法的一种 是专家迭代Expert Iteration,
Expert Iteration(ExIt)是一种增强学习算法,结合了模型学习和策略优化的思想。在Expert Iteration中,智能体的训练过程涉及两个主要阶段:专家阶段(Expert Phase)和学习阶段(Learning Phase)。
-
专家阶段(Expert Phase):在这个阶段,智能体利用一个预先设计好的专家策略来与环境进行交互,并收集经验数据。这个专家策略可以是一个由人类专家设计的策略,也可以是来自其他强化学习算法的策略。专家阶段的目的是收集高质量的经验数据,用于训练智能体的模型和策略。
-
学习阶段(Learning Phase):在这个阶段,智能体利用收集到的经验数据来训练模型和策略。具体来说,智能体使用模型学习技术来学习环境的动态模型,例如状态转移函数和奖励函数。然后,智能体利用学到的模型来生成虚拟的经验数据,并使用这些数据来优化策略。优化策略的过程可以使用任何适合的策略优化算法,例如策略梯度方法或值迭代方法。
通过交替地进行专家阶段和学习阶段,Expert Iteration能够不断地提高智能体的性能。专家阶段提供了高质量的经验数据,而学习阶段利用这些数据来不断优化智能体的模型和策略。这种交替的训练过程能够帮助智能体快速地学习到环境的动态特性和优秀的策略,从而取得更好的性能。
专家迭代的算法有Exlt算法和AlphaZero
首先,提到的ExIt算法利用Expert Iteration(ExIt)的方法来训练深度神经网络玩Hex。在ExIt算法中,首先通过专家策略或其他强化学习方法训练一个强大的专家策略,然后利用这个专家策略生成高质量的专家演示数据,最后使用这些演示数据来训练深度神经网络。通过交替进行专家阶段和学习阶段,ExIt算法能够不断提高神经网络的性能,使其能够在Hex游戏中表现出色。
其次,提到的AlphaZero也采用了类似的方法来训练深度神经网络玩Hex等游戏。AlphaZero使用自我对弈和强化学习方法来训练一个强大的专家策略,然后利用这个专家策略生成高质量的专家演示数据,最后使用这些演示数据来训练深度神经网络。通过不断改进神经网络和策略,AlphaZero能够实现在Hex等游戏中超越人类水平的表现。
model-Based 的算法 还有一种思路就是 无模型方法的数据扩充Data Augmentation for Model-Free Methods.。使用无模型RL算法来训练策略或Q函数,但可以是1)在更新代理时用虚构的经验来增加真实经验,或者2)仅使用虚构的经验更新代理。
-
MBVE(Model-Based Value Expansion):MBVE是一种方法,将真实经验与虚构经验相结合,以增强智能体的训练数据。它利用环境模型生成虚拟的经验数据,并将这些虚拟数据与真实经验数据结合起来,用于训练智能体。MBVE的核心思想是利用虚构经验来扩展智能体的训练数据集,从而提高训练效率和性能。
-
World Models:World Models是一种方法,它使用纯粹虚构的经验来训练智能体。这种方法被称为“在梦中训练”,因为智能体是在模拟环境中接收到的虚构体验中进行训练的。在World Models中,智能体的训练不依赖于真实的环境交互数据,而是完全依赖于通过模拟生成的虚构数据。通过利用虚构经验来训练智能体,World Models能够在离线环境中进行高效的训练,并且不受真实环境限制的影响。
model-Based 的算法 还有一种思路就是 Embedding Planning Loops into Policies.
把规划嵌入到策略里
将过程直接嵌入到策略中作为一个子程序,使得完整的规划成为策略的附带信息,同时使用任何标准的无模型算法来训练策略的输出。关键概念是,在这个框架中,策略可以学会选择如何和何时使用规划结果。这使得模型偏差不再是一个问题,因为如果模型在某些状态下用于规划是表现不佳,策略可以简单地学会忽略它。
比如 I2A(Imagination-Augmented Agents)是一种代理机制,采用了上述提到的带有想象力的方法。
在I2A中,代理被赋予了一种想象力,即可以生成可能的未来状态和奖励的能力。这种想象力是通过将一个内部模型嵌入到代理中来实现的,该模型能够预测在当前状态下采取不同动作后可能出现的未来状态和奖励。代理使用这个内部模型来生成多个可能的未来状态和奖励,然后利用这些想象的信息来指导其决策和学习过程。
通过将想象力嵌入到代理中,I2A代理能够更好地理解环境,并更有效地规划和执行行动。这种方法使代理不仅仅依赖于当前环境的观测和反馈,还可以通过想象未来的情景来辅助决策,从而提高了其灵活性和性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









