










论文学习1
题目中文翻译:基于用户特征LDA的微博文本特征扩展
作者:Wei Xia、Yanxiang He、Ye Tian、Qiang Chen、Lu Lin
时间:2011
关键词:TDT、LDA Model、user feature、short text
研究应用领域:话题检测与追踪(TDT)
下载地址:http://pan.baidu.com/share/link?shareid=1761754852&uk=3040079072
基于用户特征的LDA,简称ULDA
PS:写这篇文章的人就在我隔壁!
一看到LDA,头都大了,赶紧退避三舍,虽然在大师看来是最简单的机器学习模型,但是对我等小辈,简直犹如蜀道之难于上青天。首先关于LDA,我看过好几遍,但感觉还是没达到一定的火候。好吧,这里尽量不谈LDA细节上的问题。不过关于LDA,至少得有这样的认识:它是一个三层的概率模型——文档、主题、单词。这个模型有两个主要分布:文档~主题分布、主题~单词分布。如果需要生成一篇文档并规定了文档的词数,那么我们可以由这两个分布生成之。(也就是说,如果LDA足够得好,足够地高级,那么我们以后写文章就可以“不经过大脑思考”,直接由计算机生成,妈妈再也不用担心我的作文写不好了。)
关于LDA的介绍,相信给几篇学术论文的链接估计也没人去看,我这里也不多说,感觉自己缺乏一定的专业性,那么好,这里转2篇本博客论坛中文章:
http://blog.csdn.net/feixiangcq/article/details/5649135
http://blog.csdn.net/feixiangcq/article/details/5655086
再来一篇我学LDA时读过好几遍的写得比较的文章——LDA数学八卦(个人强烈推荐):
http://pan.baidu.com/share/link?shareid=3454655524&uk=3040079072
Introduction部分主要说明微博平台的话题检测与追踪技术正当时候,尤其是中文新浪微博。然后表明微博文本作为短文本具有的一系列特点给研究造成了困难。什么特点呢,就是关键词词频小,文本向量稀疏化严重等。(PS:这里还没提到描述不规范性。比如:“再见”说成“债见”,或者直接打拼音、错别字等等,当然啦,这篇文章主要讲怎么进行短文本特征扩展,所以也可忽略)。然后顺势引出基于ULDA的微博文本特征扩展。
Related Work部分主要介绍了微博文本研究中的一些现状。主要是以下几点:微博文本摘要、微博信息冗余处理、根据搜索引擎计算文本相似度、用户行为分析(这个举了一篇分析股票行为的文章)。
ULDA建模主要分以下三方面:
1. 纵向时间轴上获取每一个用户的所有微博的主题分布。然后将前一个时间段和后一个时间段的主题分布进行比较得出新主题。
2. 横向时间上(即同一个时间段内),分析所有发布的微博,跟之前的基准作比较,以便发现新的主题。
3. 对所有微博用户进行分类,将其分为不同的用户组,获得每一个用户组的主题分布。
好吧,接下来的过程就是略显复杂的公式化、参数估计过程。稍微看过一点LDA的同学应该至少对以下两组参数还记忆犹新吧,一对是α和β,一对是θ和φ。
α是文档~主题Dirichlet分布的参数,是一个列向量。
β是训练得到的参数,用在主题~单词分布中,是一个矩阵,矩阵的每一个元素表示某个主题下生成某个单词的概率。
θ代表文档~主题Dirichlet分布,θ本身是一个列向量,每一个元素的值代表文档中各个主题的分布概率(注意,这里是测试时候的概率,不是训练时候的概率)。
φ代表主题~单词的多项式分布,有的文献里用字母z表示,φ本身是一个矩阵,矩阵的每一个元素表示某个主题下生成某个单词的概率(注意,这里是测试时候的概率,不是训练时候的概率)。
有了以上这些参数外加一些处理,这样,每篇文档的似然值就可以算出来了。这里,我贴出了原文中的计算公式,贴公式的目的不是为了去细细解读它,因为我没有把公式里的参数都列举齐全,我只是为了突出α和β这两个参数在这个计算公式中的重要作用而已。
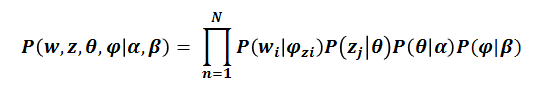
准备工作做完,接下来就是加入用户特征。
用户方面的特征主要由以下2方面组成:
1. 同一个用户所发的微博往往具有相同的语言风格,它们之间的文本相似度往往较高。
2. 用户的行为主要由评论和转发两方面组成。
加入用户特征的ULDA模型如下所示:
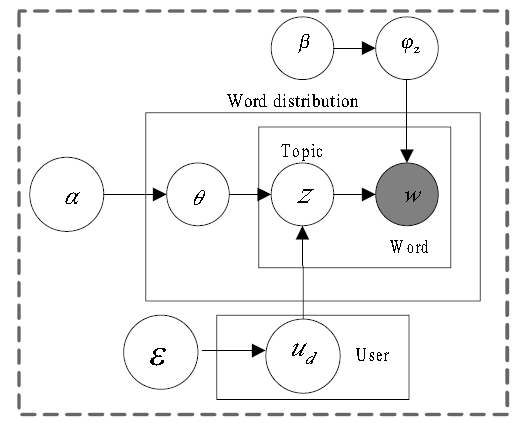
这个图的上半部分是我们很熟悉的LDA模型图,最下面加入了用户特征的影响,其分布的参数又多了一个ε。
而后是ULDA的参数估计,最重要的参数α、β和ε需要通过语料训练获得(好吧,这是一句很笼统的话)。那么具体来说的话,LDA参数训练的方法一般有变分推断(Varitional Inference)和Gibbs采样(Gibbs Sampling)两种,为了方便计算,一般采取Gibbs采样方法。关于Gibbs采样,它是一种基于马尔科夫链蒙卡罗特方法(MCMC)的采样算法。具体如何进行不展开,详见我刚刚上面写的推荐读物——LDA数学八卦。
关于α和β就不多说了,主要是关于这个用户特征的分布,要说一下。
我们将用户的活跃度(liveness)作为用户特征的总和(即我们以该特征表示用户所有特征的总和,这样可减小维度)。我们按如下步骤构建用户特征模型:
1. 构建用户关系图,用U1,U2两个矩阵分别表示微博转发与评论的关系矩阵。矩阵的元素为1表示有关系,为0表示没有这些关系。U1矩阵对角元素表示从某一个用户转发微博的总人数,U2矩阵表示在某个用户的微博上进行评论的用户的总人数。
2. 计算每一个用户的活跃度P。该活跃度由两部分组成,一部分是转发活跃度Ptr,还有一部分是评论活跃度Pev。所以总的活跃度计算公式如下(这个公式不难,我这里没给全所有变量的解释,相信大家也能看懂):
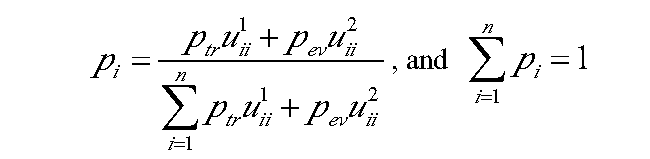
这个活跃度值的向量集合可作为模型中的参数ε。
至此,所有的参数都已计算完毕,ULDA模型大功告成。我们就可以按照ULDA的框架来处理微博文本,接下来主要步骤就是文档~主题、主题~单词这两个分布的运用。
那么说细一点,接下来应该是:
1. 在纵向时间轴上获得某个用户所有微博的主题分布和单词分布,这个持续的时间是T;而后,我们在接下来的ΔT时间内也如此做。如果在这个ΔT时间内出现了新的主题的关键字,我们就认为发现了新的(潜在)主题。
2. 横向上,分析某个时间段内的所有用户的所有微博,其他条件及判别方法与上一步相同。
3. 还对用户进行群组划分,由此可获得每个群组所感兴趣的话题。
用ULDA特征扩展总流程如下:
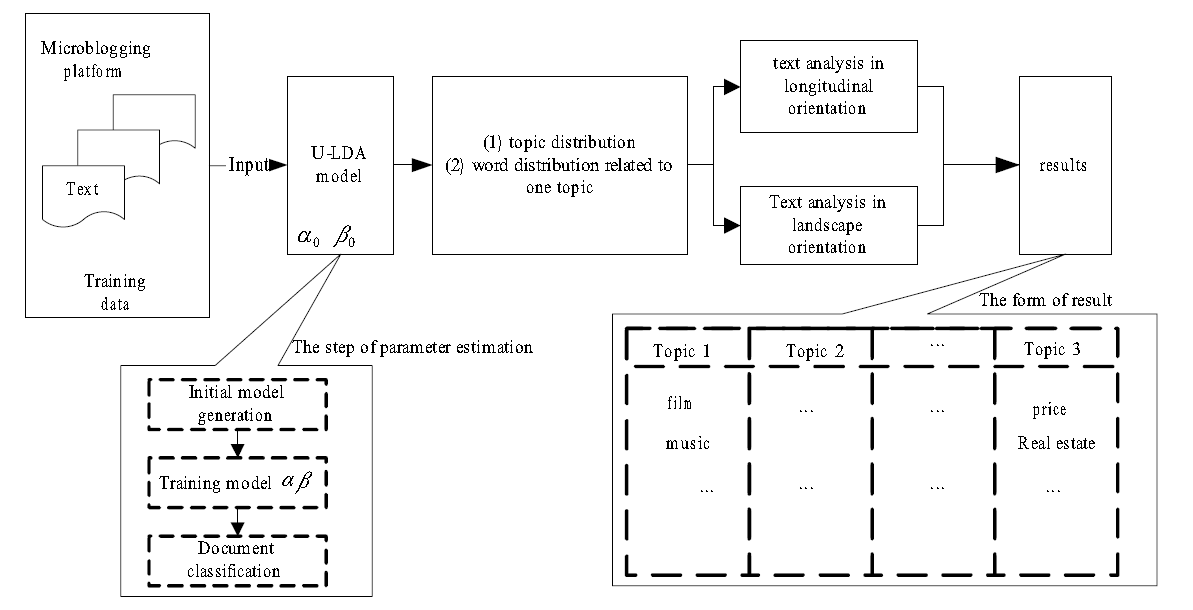
Experiment部分略,没什么可说的地方。
平时接触主题模型的论文也不多,在这方面感觉也不是很强,但看到写这篇文章的是我们隔壁的,所以也兴致勃勃。
这篇文章的缺点:
1. 用户特征的表示部分太少了,所选取的特征虽然是典型,但是仅考虑这2项太少了点,比如还可考虑下粉丝量(SNA中这个一般是很重要的)什么的。
2. 用户特征向量得到后感觉与LDA模型的结合差强人意,这样的结合破坏了LDA原有的公式之间的数学之美。(当然,这个仅是我个人的看法)。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









