







斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1) = 1
F(n) = F(n - 1) + F(n - 2),其中 n > 1
给定 n ,请计算 F(n) 。
示例 1:
输入:n = 2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1
示例 2:
输入:n = 3
输出:2
解释:F(3) = F(2) + F(1) = 1 + 1 = 2
示例 3:
输入:n = 4
输出:3
解释:F(4) = F(3) + F(2) = 2 + 1 = 3
提示:
0 <= n <= 30
思路一:暴力递归,存在⼤量重复计算,效率低。
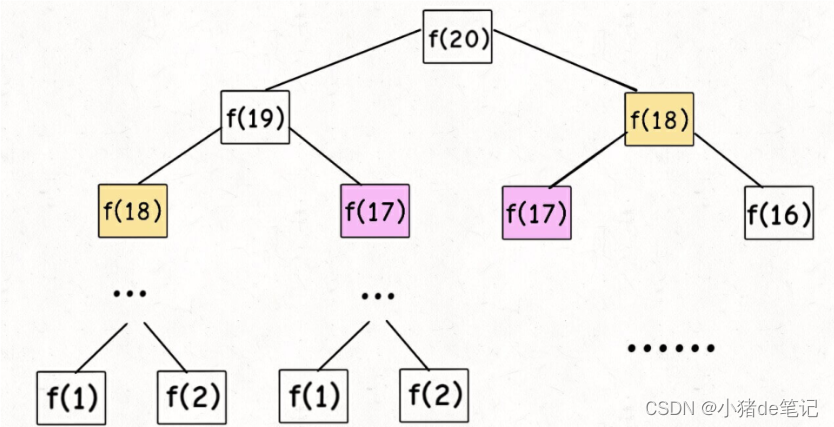
递归算法的时间复杂度:用子问题个数乘以解决一个子问题需要的时间
⼦问题个数,即递归树中节点的总数。显然⼆叉树节点总数为指数级别,所以⼦问题个数为 O(2^n)
没有循环,只有 f(n - 1) + f(n - 2) ⼀个加法操作,时间为 O(1)。所以,这个算法的时间复杂度为 O(2^n),指数级别,爆炸了。

思路二:带备忘录的递归解法 (使用memo数组或者哈希表充当备忘录),自定向下
⼦问题个数,即图中节点的总数,由于本算法不存在冗余计算,⼦问题就是f(1),f(2),f(3)…f(20),数量和输⼊规模n=20成正⽐,所以⼦问题个数为O(n)。
解决⼀个⼦问题的时间,同上,没有什么循环,时间为O(1)。所以,本算法的时间复杂度是O(n)。⽐起暴⼒算法,是降维打击
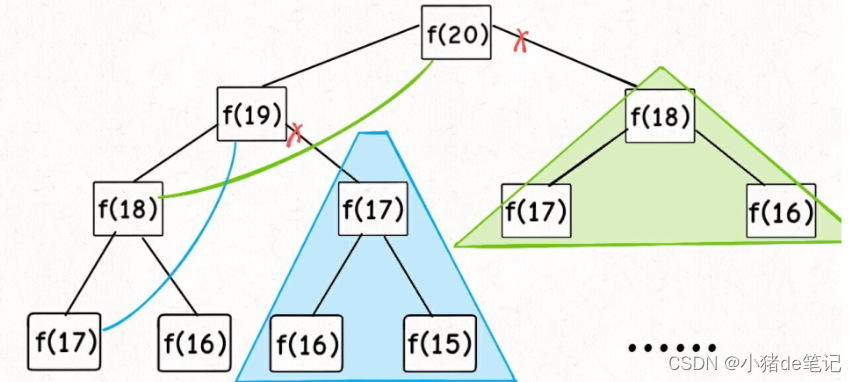
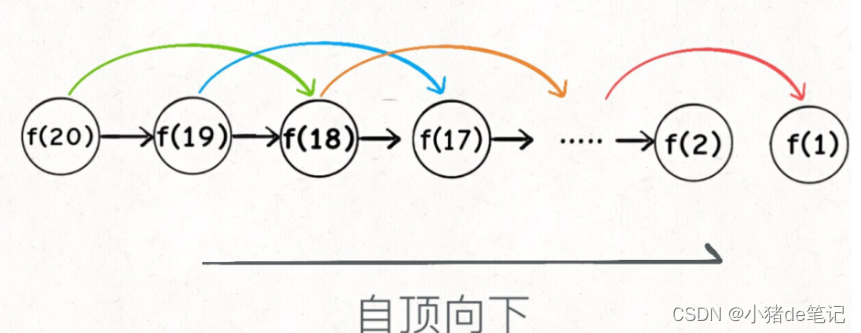


⾄此,带备忘录的递归解法的效率已经和迭代的动态规划解法⼀样了。实际上,这种解法和迭代的动态规划已经差不多了,只不过这种⽅法叫做「⾃顶向下」,动态规划叫做「⾃底向上」。
啥叫「⾃顶向下」?注意我们刚才画的递归树(或者说图),是从上向下延伸,都是从⼀个规模较⼤的原问题⽐如说f(20),向下逐渐分解规模,直到f(1)和f(2)触底,然后逐层返回答案,这就叫「⾃顶向下」。
啥叫「⾃底向上」?反过来,我们直接从最底下,最简单,问题规模最⼩的f(1)和f(2)开始往上推,直到推到我们想要的答案f(20),这就是动态规划的思路,这也是为什么动态规划⼀般都脱离了递归,⽽是由循环迭代完成计算
思路三:动态规划,自底向上,DP table
三板斧:初始值、终止条件、状态转移方程,即找到“状态”、“选择”和状态转移方程。找到“状态”和“选择”->明确dp数组/函数的定义->寻找状态之间的关系。时间复杂度也是O(n).
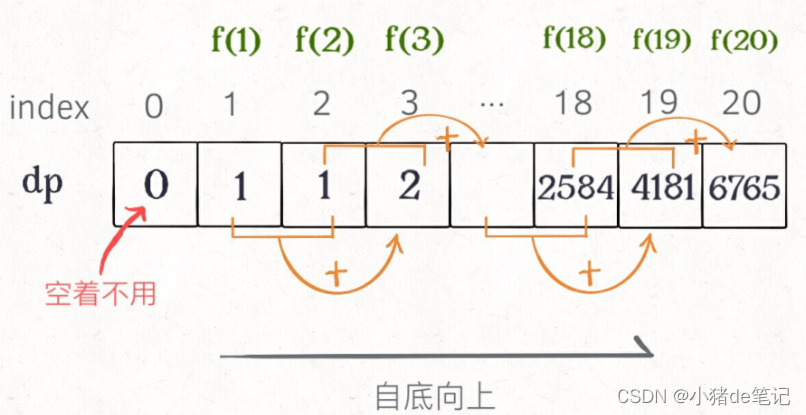
画个图就很好理解了,⽽且你发现这个DPtable特别像之前那个「剪枝」后的结果,只是反过来算⽽已。实际上,带备忘录的递归解法中的「备忘录」,最终完成后就是这个DPtable,所以说这两种解法其实是差不多的,⼤部分情况下,效率也基本相同。
这⾥,引出「状态转移⽅程」这个名词,实际上就是描述问题结构的数学形式:
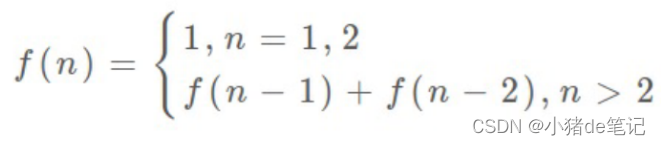
为啥叫「状态转移⽅程」?为了听起来⾼端。你把f(n)想做⼀个状态n,这个状态n是由状态n-1和状态n-2相加转移⽽来,这就叫状态转移,仅此⽽已。

你会发现,上⾯的⼏种解法中的所有操作,例如returnf(n-1)+f(n-2),dp[i]=dp[i-1]+dp[i-2],以及对备忘录或DPtable的初始化操作,都是围绕这个⽅程式的不同表现形式。可⻅列出「状态转移⽅程」的重要性,它是解决问题的核⼼。很容易发现,其实状态转移⽅程直接代表着暴⼒解法。
千万不要看不起暴⼒解,动态规划问题最困难的就是写出状态转移⽅程,即这个暴⼒解。优化⽅法⽆⾮是⽤备忘录或者 DP table,再⽆奥妙可⾔!
思路四:dp数组的迭代解法+状态压缩
这个例⼦的最后,讲⼀个细节优化。细⼼的读者会发现,根据斐波那契数列的状态转移⽅程,当前状态只和之前的两个状态有关,其实并不需要那么⻓的⼀个DPtable来存储所有的状态,只要想办法存储之前的两个状态就⾏了。所以,可以进⼀步优化,把空间复杂度降为O(1):
当然越高级越抽象,当然也越难理解。















 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









