







从今日起,本女子开始一步步学习Android. 愿自己持之以恒。阿门!
坑爹的,昨日搭建环境整到了凌晨,不是因为环境搭建困难,而是因为下载量过大。
所以在这里,温馨提示下:保持良好的网络环境,网速必须求给力!
Start :
一、环境搭建前的准备。
1. JDK。 【直接去官网下吧。1.6以上】(JDK安装配置教程)
2. eclipse。【3.6.2版本以上】下载地址
3. SDK。【本文档采用android-sdk_r18-windows,现已有更高版本可更新】下载地址
4. ADT。【本文档采用ADT-22.0.1.zip】下载地址
二、环境搭建
1.JDK安装与配置。双击点开下载好的应用程序,一直点下一步,直至完成。完成后,记得要配置环境变量。(JDK安装配置教程)
2.eclipse。直接解压下载完成后的eclipse压缩包即可获取eclipse.exe。
3.SDK。解压android-sdk_r18-windows.zip,如图:
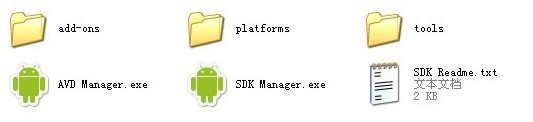
【其中platforms和add-ons文件夹是空的】
双击SDK Manager.exe 【下载你要的Android版本】
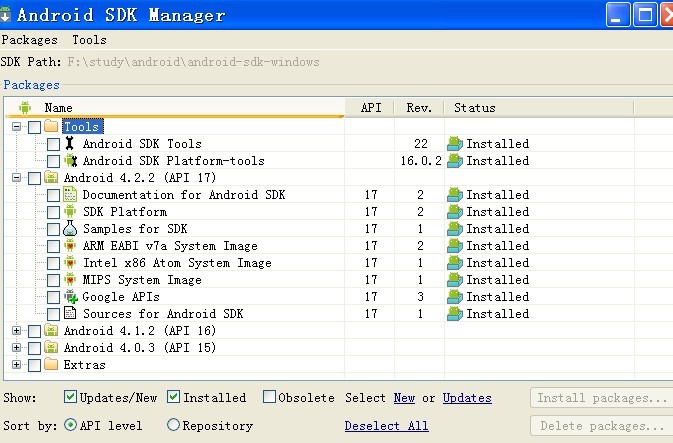
下载完成后,文件夹如图:
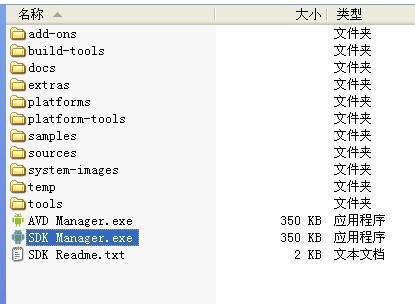
【platforms和add-ons文件夹是有相应的内容了】
好了,SDK告一段落。
4.安装ADT。ADT实为eclipse(即IDE)与Andorid SDK的中间件(即插件)。
打开eclipse,在eclipse中安装插件, 点击 help ,选择Install new Software 进入后,点击add,命名及点击Archive选择你下载的ADT压缩包,点击OK,
会解析出该插件的全部可用内容,全选(select all),点击下一步,安装时需要一定时间,在安装的过程中会出现一些提示,点击允许即可。
安装完成后,重启eclipse,即可看到左边菜单栏中有Android机器人了,插件安装成功!
【安装成功,如没显示图标,则Eclipse ->window->customize Perpective->Command Groups Availability 勾选andorid 选项就可以了】
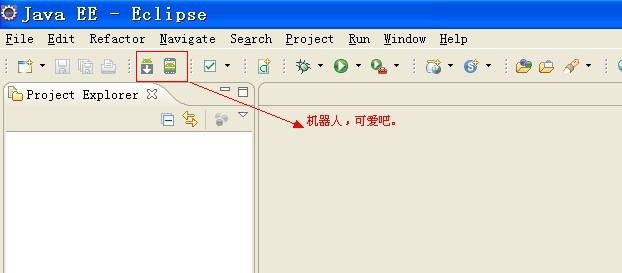
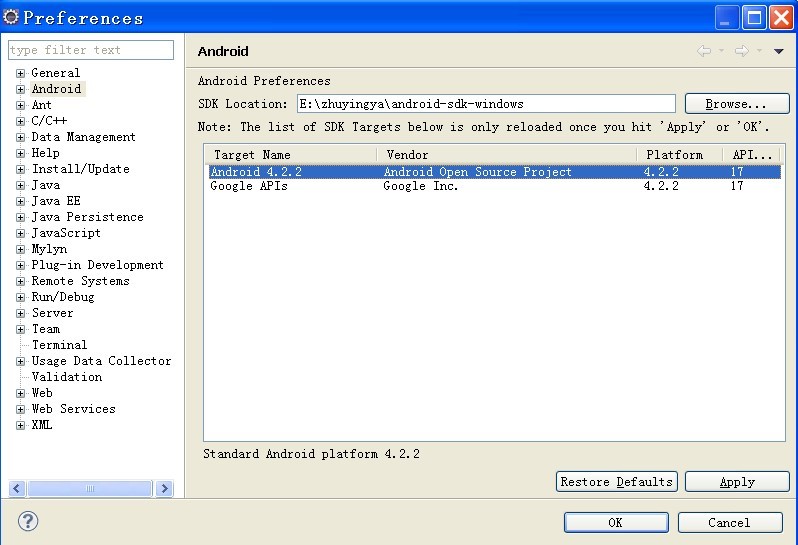
5.安装完ADT插件后,点击 window --> preference,点击android,添加SDK目标位置,将SDK通过ADT插件与IDE关联。如图:
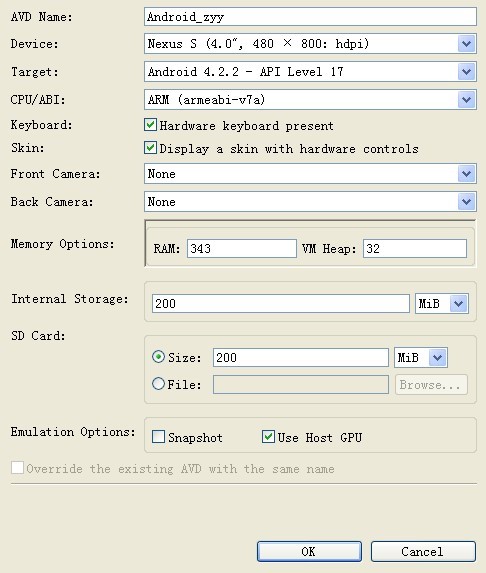
6.SDK关联后,开始创建AVD吧【AVD就是android模拟器】。
点击机器人旁边的手机,即Android Virtual Device Manager,在Android Virtual Device页签,点击New,填写相关内容信息(自定义),如图:
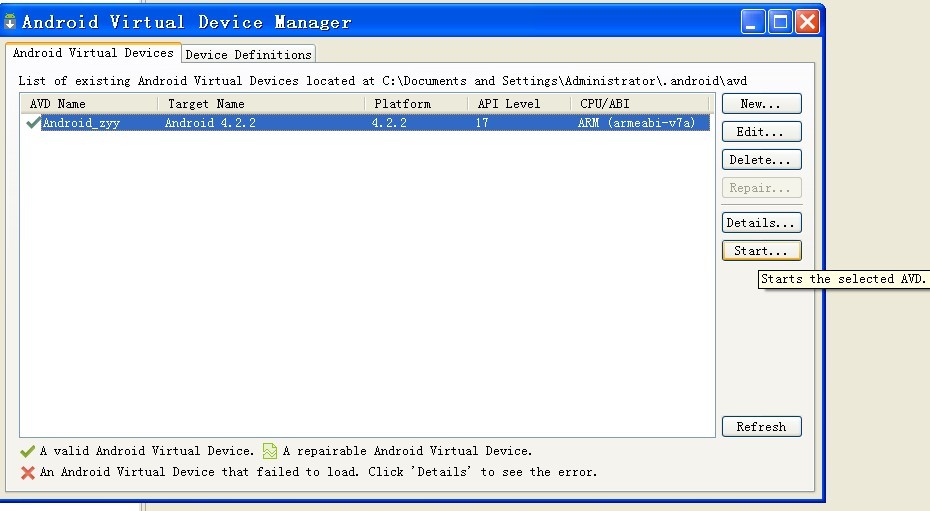
点击ok,选中当前AVD,点击start,如图:
跳转弹出框后,选择Launch,等待加载完成,模拟器运行完成进行系统后,如图:
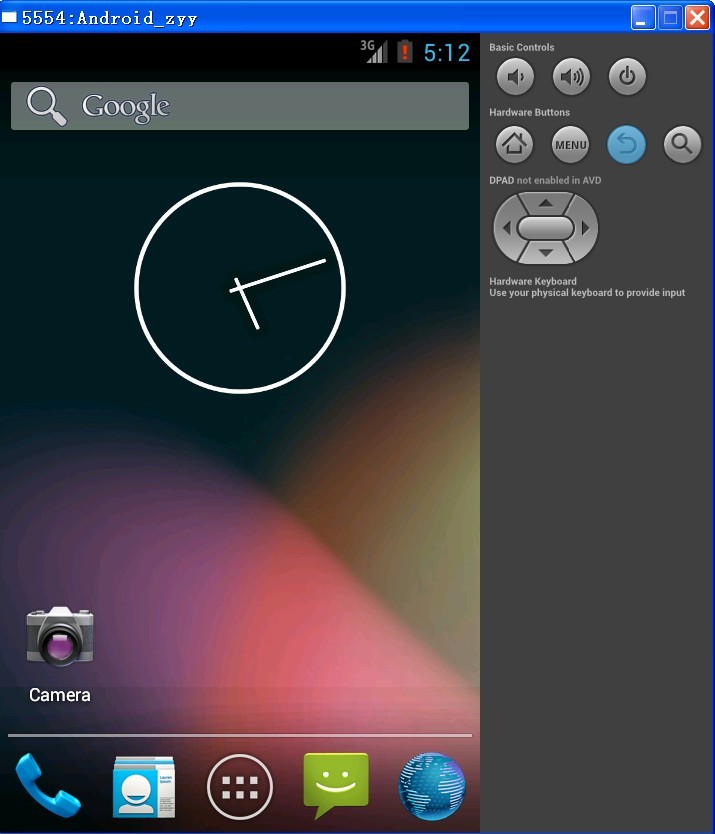
好了,环境搭建完毕,然后,你可以像玩手机一样,玩模拟器了。只是运行速度不及手机罢了。
收工啦。第一篇学习文章记录完毕。后续,我将继续学习API,学习各种控件,学习开发应用程序。















 3715
3715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









