







通过前面的分析我们知道,主线程通过KafkaProducer.send方法将消息放入RecordAccumulator中缓存,并没有实际的网络I/O操作。网络I/O操作是由Sender线程统一进行的。
我们先来了解一下Sender线程发送消息的整个流程:
首先,它根据RecordAccumulator的缓存情况,筛选出可以向哪些Node节点发送消息,即上一节介绍的RecordAccumulatorready方法;
然后,根据生产者与各个节点的连接情况由NetworkClient管理,过滤Node节点;
之后,生成相应的请求,这里要特别注意的是,每个Node节点只生成一个请求;
最后,调用NetWorkClient将请求发送出去。图展示了Sender依赖的三个比较关键的组件。
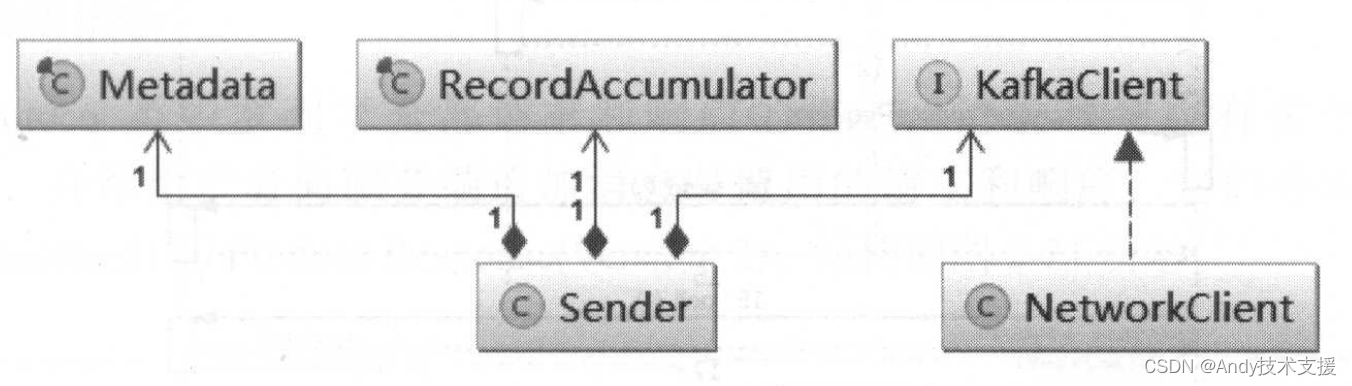
Sender实现了Runnable接口,并运行在单独的ioThread中。Sender的run方法调用了其重载run(long),这才是Sender线程的核心方法,也是发送消息的关键流程,其时序图如图所示。
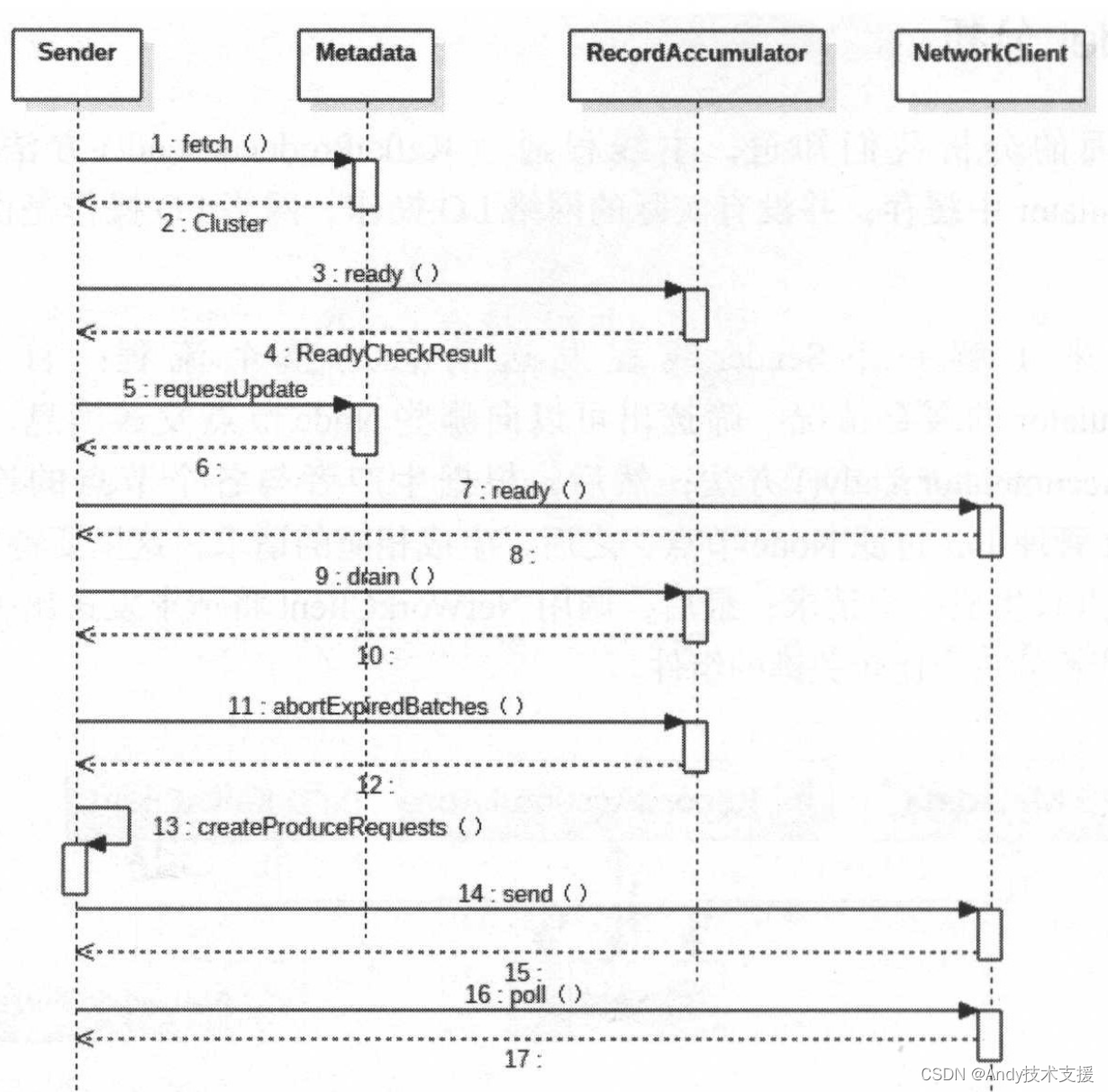
下面简述run(long)方法的流程:
- 从Metadata获取Kafka集群元数据。
- 调用RecordAccumulator.ready方法,根据RecordAccumulator的缓存情况,选出可以向哪些Node节点发送消息,返回ReadyCheckResult对象。
- 如果ReadyCheckResult中标识有unknownLeadersExist,则调用Metadata的requestUpdate方法,标记需要更新Kafka的集群信息。
- 针对ReadyCheckResult中readyNodes集合,循环调用NetworkClient.ready方法,目的是检查网络I/O方面是否符合发送消息的条件,不符合条件的Node将会从readyNodes集合中删除。
- 针对经过步骤4处理后的readyNodes集合,调用RecordAccumulator.drain方法,获取待发送的消息集合。
- 调用RecordAccumulator.abortExpiredBatches()方法处理RecordAccumulator中超时的消息。
其代码逻辑是,遍历RecordAccumulator中保存的全部RecordBatch,调用RecordBatch.maybeExpire()方法进行处理。
如果已超时,则调用RecordBatch.done()方法,其中会触发自定义Callback,并将RecordBatch从队列中移除,释放ByteBuffer空间。 - 调用Sender.createProduceRequests()方法将待发送的消息封装成ClientRequest。
- 调用NetWorkClient.send方法,将ClientRequest写入KafkaChannel的send字段。
- 调用NetWorkClient.poll方法,将KafkaChannel.send字段中保存的ClientRequest发送出去,同时,还会处理服务端发回的响应、处理超时的请求、调用用户自定义Callback等。
创建请求
在Protocol类中罗列了全部请求和响应的格式,请求和响应有多个不同的版本。
首先,介绍生产者向服务端追加消息时使用的请求和响应,它们分别是ProduceRequest(Version:2)和Produce Response(Version:2),结构如图所示。
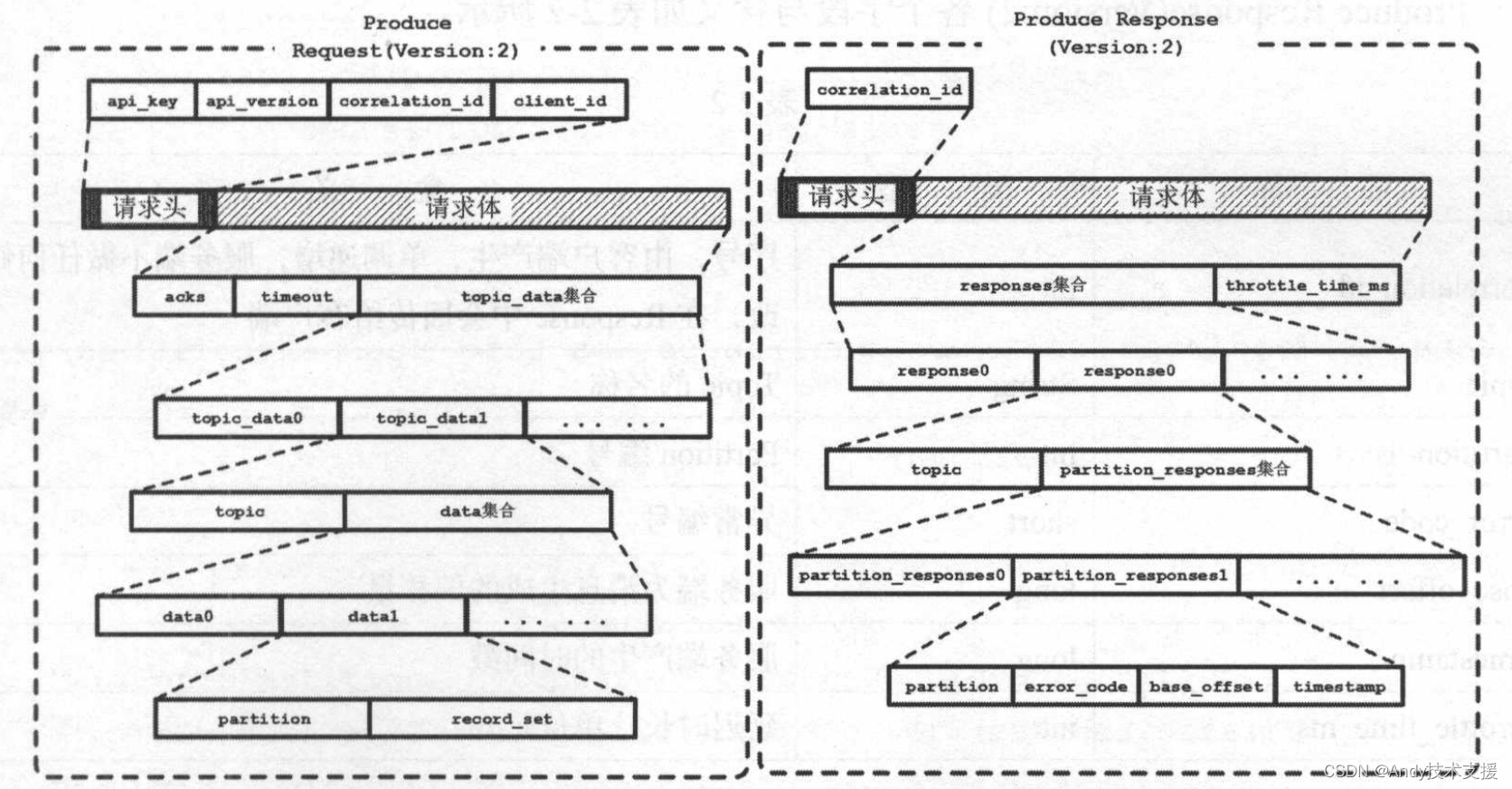
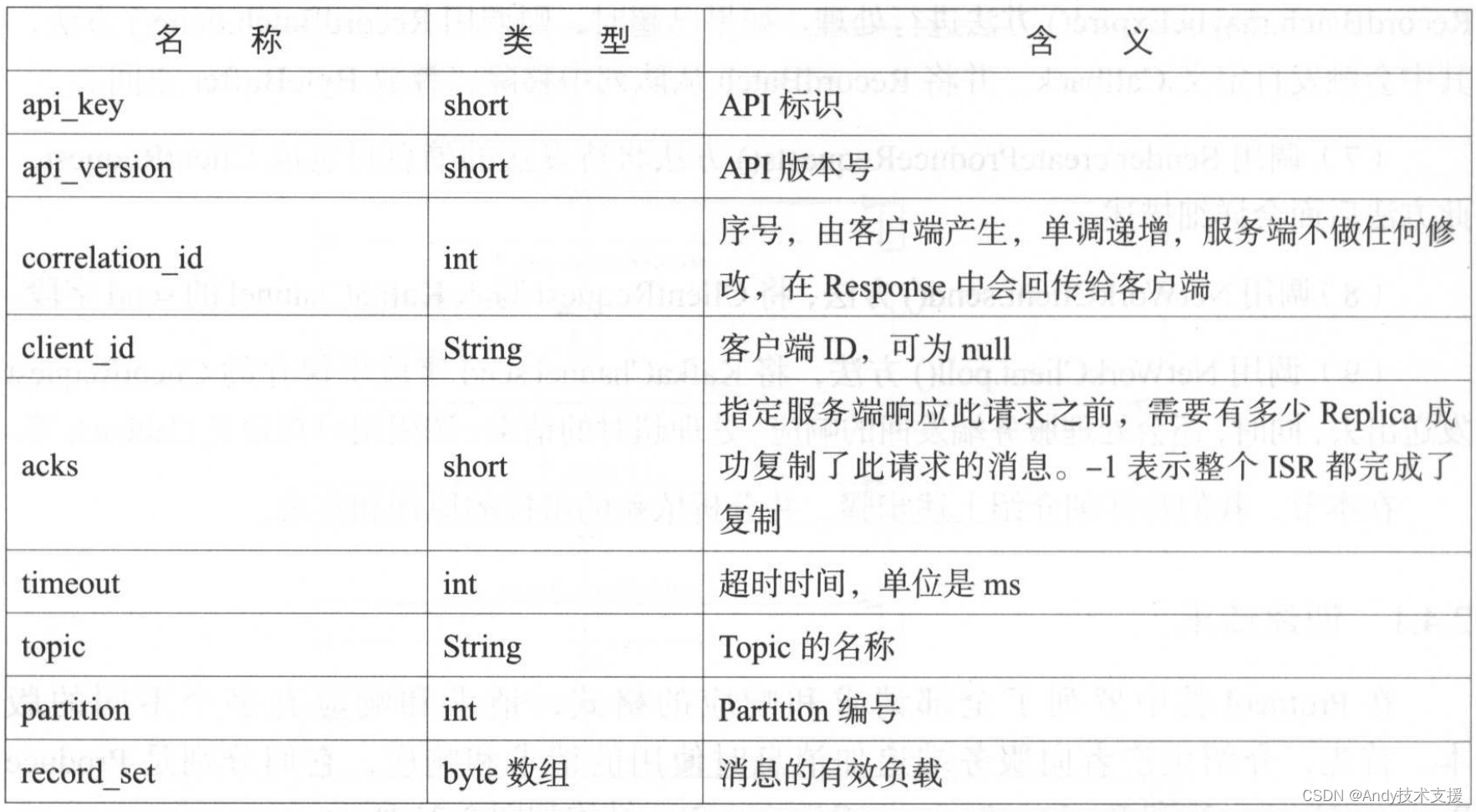
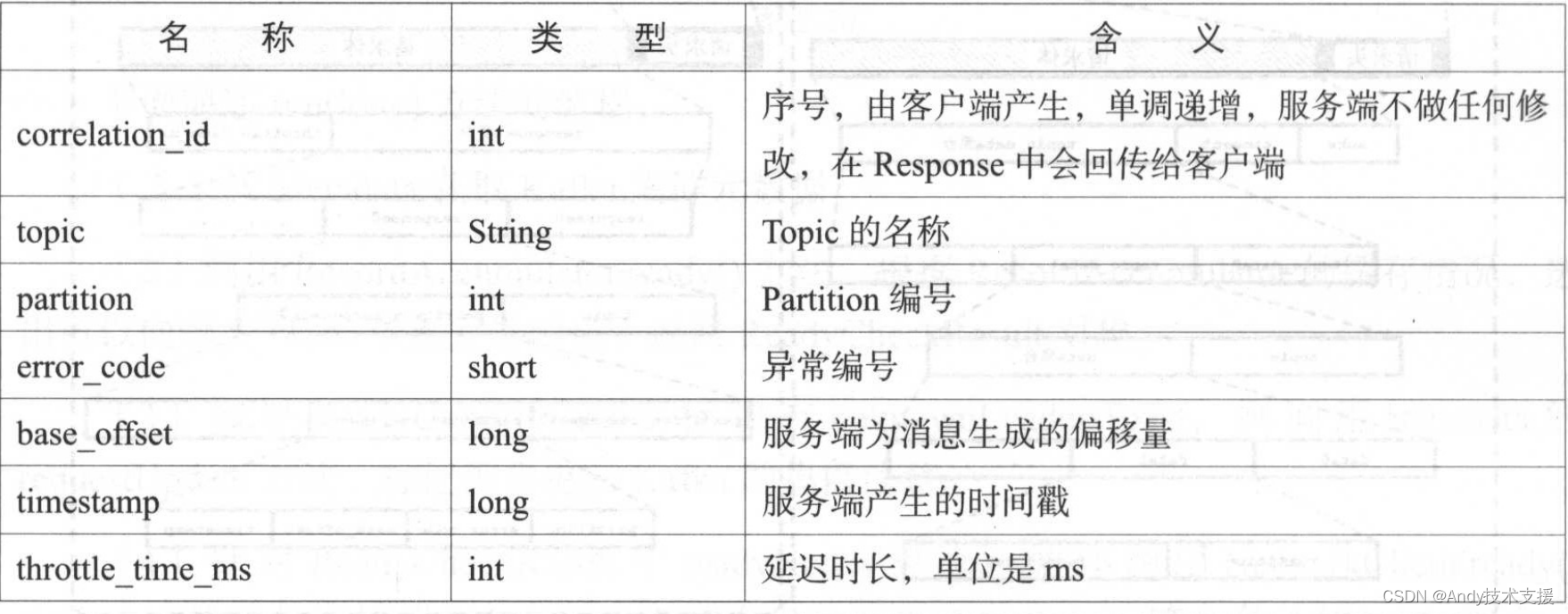
Produce Request(Version:2)的请求头和请求体各个字段的含义如表所示.
Produce Response(Version:2)各个字段与含义如表所示.
Sender.sendProduceRequests()方法的功能是将待发送的消息封装成ClientRequest。
不管一个Node对应有多少个RecordBatch,也不管这些RecordBatch是发给几个分区的,每个Node至多生成一个ClientRequest对象。创建ClientRequest的核心逻辑如下:
- 将一个Nodeld对应的RecordBatch集合,重新整理为produceRecordsByPartition(Map<TopicPartition,ByteBuffer>) 和recordsByPartition(Map<TopicPartition,RecordBatch>)两个集合。
- 创建RequestSend,RequestSend是真正通过网络I/O发送的对象,其格式符合上面描述的Produce Request(Version:2)协议,其中有效负载就是produceRecordsByPartition中的数据。
- 创建RequestCompletionHandler作为回调对象。
- 将RequestSend对象和RequestCompletionHandler对象封装进ClientRequest对象中,并将其返回。
下面来看Sender.sendProduceRequests()方法的具体实现:

KSelector
在介绍NetworkClient之前,我们先来了解NetworkClient的整个结构,以及其依赖的他组件,如图所示。

需要注意的是,图中的Selector的类型并不是java.nio.channels.Selector,而是
org.apache.kafka.common.network.Selector,为了方便区分和描述,将其简称为KSelect。
KSelector使用NIO异步非阻塞模式实现网络I/O操作,KSelector使用一个单独的线程可以管理多条网络连接上的连接、读、写等操作。
下面介绍KSelector的核心字段和方法,如图所示。

下面先介绍KSelector的字段。
- nioSelector:java.nio.channels.Selector类型,用来监听网络I/O事件。
- channels:HashMap<String,KafkaChannel>类型,维护了Nodeld与KafkaChannel之间的映射关系,表示生产者客户端与各个Node之间的网络连接。
KafkaChannel是在SocketChannel上的又一层封装,如图所示,其中Send和NetworkReceive分别表示读和写时用的缓存,底层通过ByteBuffer实现,TransportLayer封装SocketChannel及SelectionKey,TransportLayer根据网络协议的不同,提供不同的子类,而对KafkaChannel提供统一的接口,这是策略模式很好的应用.

- completedSends:记录已经完全发送出去的请求。
- completedReceives:记录已经完全接收到的请求。
- stagedReceives:暂存一次OP_READ事件处理过程中读取到的全部请求。当一次OP_READ事件处理完成之后,会将stagedReceives集合中的请求保存到completeReceives集合中。
- disconnected、connected:记录一次poll过程中发现的断开的连接和新建立的连接。
- failedSends:记录向哪些Node发送的请求失败了。
- channelBuilder:用于创建KafkaChannel的Builder。根据不同配置创建不同的TransportLayer的子类,然后创建KafkaChannel。其创建的KafkaChannel封装的是PlaintextTransportLayer。
- IruConnections:LinkedHashMap类型,用来记录各个连接的使用情况,并据此关闭空闲时间超connectionsMaxldleNanos的连接。
下面介绍KSelector的核心方法。KSelector.connect方法主要负责创建KafkaChannel,并添加到channels集合中保存。其代码如下:

KSelector.send方法是将之前创建的RequestSend对象缓存到KafkaChannel的send字段中,并开始关注此连接的OP_WRITE事件,并没有发生网络I/O。
在下次调用KSelector.poll时,才会将RequestSend对象发送出去。如果此KafkaChannel的send字段上还保存着一个未完全发送成功的RequestSend请求,为防止覆盖数据,则会抛出异常。也就是说,每个KafkaChannel一次poll过程中只能发送一个Send请求。
KSelectorpoll方法真正执行网络VO的地方,它会调用nioSelector.select方法等待VO事件发生。
当Channel可写时,发送KafkaChannel.send字段(切记,一次最多只发送一个RequestSend,有时候一个RequestSend也发送不完,需要多次poll才能发送完成);
Channel可读时,读取数据到KafkaChannel.receive,读取一个完整的NetworkReceive后,会将其缓存到stagedReceives中,当一次pollSelectionKeys完成后会将stagedReceives中的数据转移到completedReceives。
最后调用maybeCloseOldestConnection方法,根据IruConnections记录和connectionsMaxldleNanos最大空闲时间,关闭长期空闲的连接。
下面是KSelector.poll方法的代码:

KSelector.pollSelectionKeys()方法是处理I/O操作的核心方法,其中会分别处理OP_CONNECT、OP_READ、OP_WRITE事件,并且会检测连接状态。下面是其代码:

最终,读写操作还是交给了KafkaChannel,下面来分析其相关的方法:
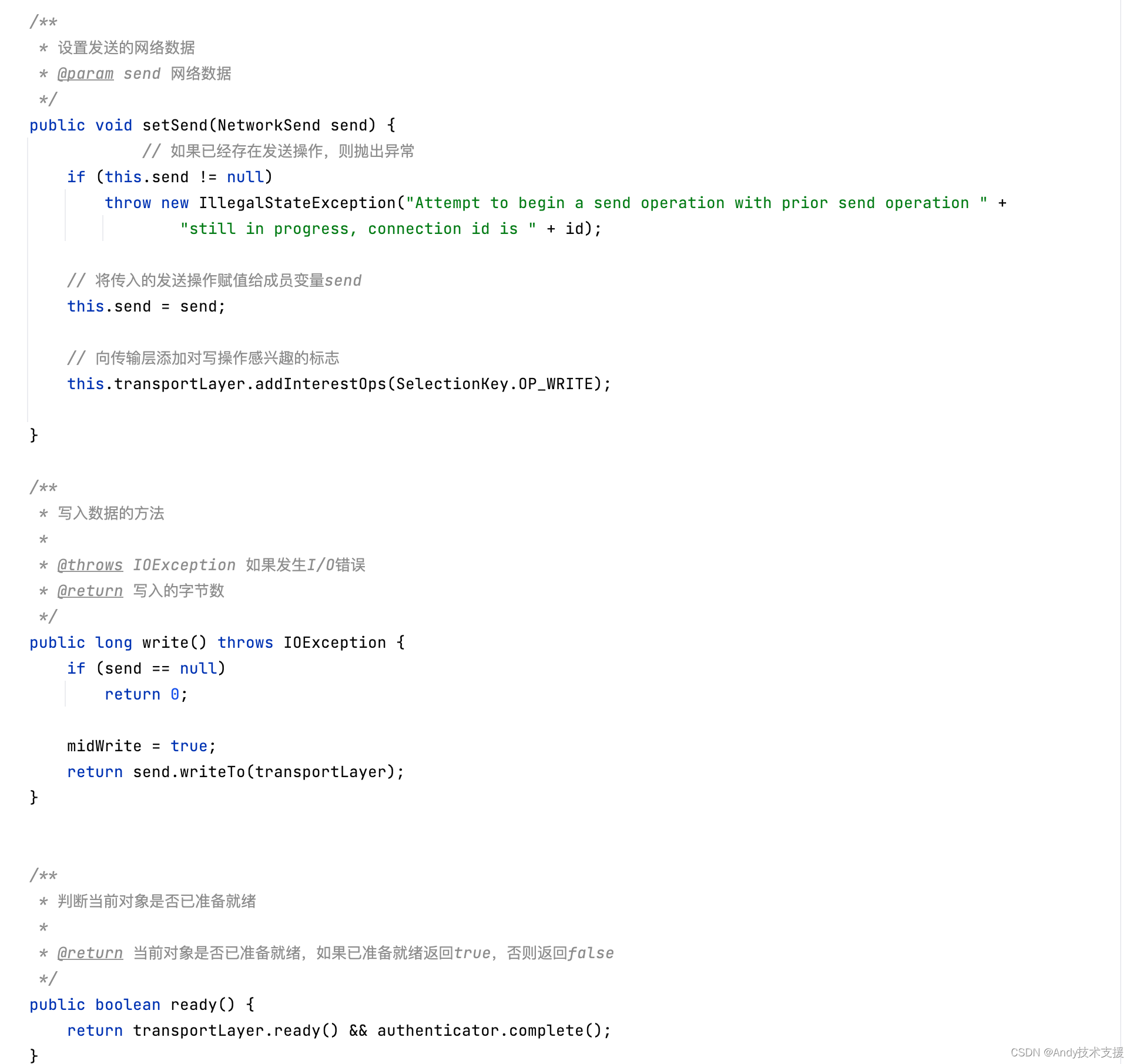
InFlightRequests
InFlightRequests队列的主要作用是缓存了已经发出去但没收到响应的ClientRequest.其底层是通过一个Map<String,Deque>对象实现的,key是Nodeld,value是发送到对应Node的ClientRequest对象集合。
InFlightRequests提供了很多管理这个缓存队列的方法,还通过配置参数,限制了每个连接最多缓存的ClientRequest个数。
InFlightRequests的结构如图所示。
InFlightRequests.canSendMore()方法比较重要,NetworkClient调用此方法是用于判断是否可以向指定Node发送请求的条件之一,其代码如下:

此外,队头的消息与对应KafkaChannel.send字段指向的是同一个消息,为了避免未发送的消息被覆盖,也不能让KafkaChannel.send字段指向新请求。最后queue.size<this.maxInFlightRequestsPerConnection)条件则是为了判断InFlightRequests队列中是否堆积过多请求。如果Node已经堆积了很多未响应的请求,说明这个节点负载可能较大或是网络连接有问题,继续向其发送请求,则可能导致请求超时。
MetadataUpdater
MetadataUpdater接口是一个辅助NetworkClient更新的Metadata的接口,它有两个实现类,如图所示。
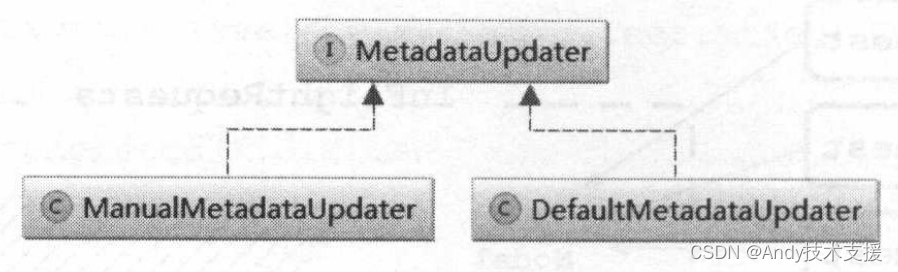
ManualMetadataUpdater是个空实现,DefaultMetadataUpdater是NetworkClient使用的默认实现,下面介绍其三个字段。
- metadata:指向记录了集群元数据的Metadata对象。
- metadataFetchlnProgress:用来标识是否已经发送了MetadataRequest请求更新Metadata,如果已经发送,则没必要重复发送。
- lastNoNodeAvailableMs:当检测到没有可用节点时,会用此字段记录时间戳。
maybeUpdate方法是DefaultMetadataUpdater的核心方法,用来判断当前的Metadata中保存的集群元数据是否需要更新。首先检测metadataFetchlnProgress字段,如果没发送,满足下面任一条件即可更新: - Metadata.needUpdate字段被设置为true,且退避时间已到。
- 长时间没更新,默认5分钟更新一次。
如果需要更新,则发送MetadataRequest请求,MetadataRequest请求的格式比较简单,其消息头部包含ApiKeys.METADATA标识,消息体中包含Topic集合表示需要获取元数据的Topic,如果Topic集合为null则表示请求全部Topic的元数据。MetadataResponse的格式略显复杂,如图所示。
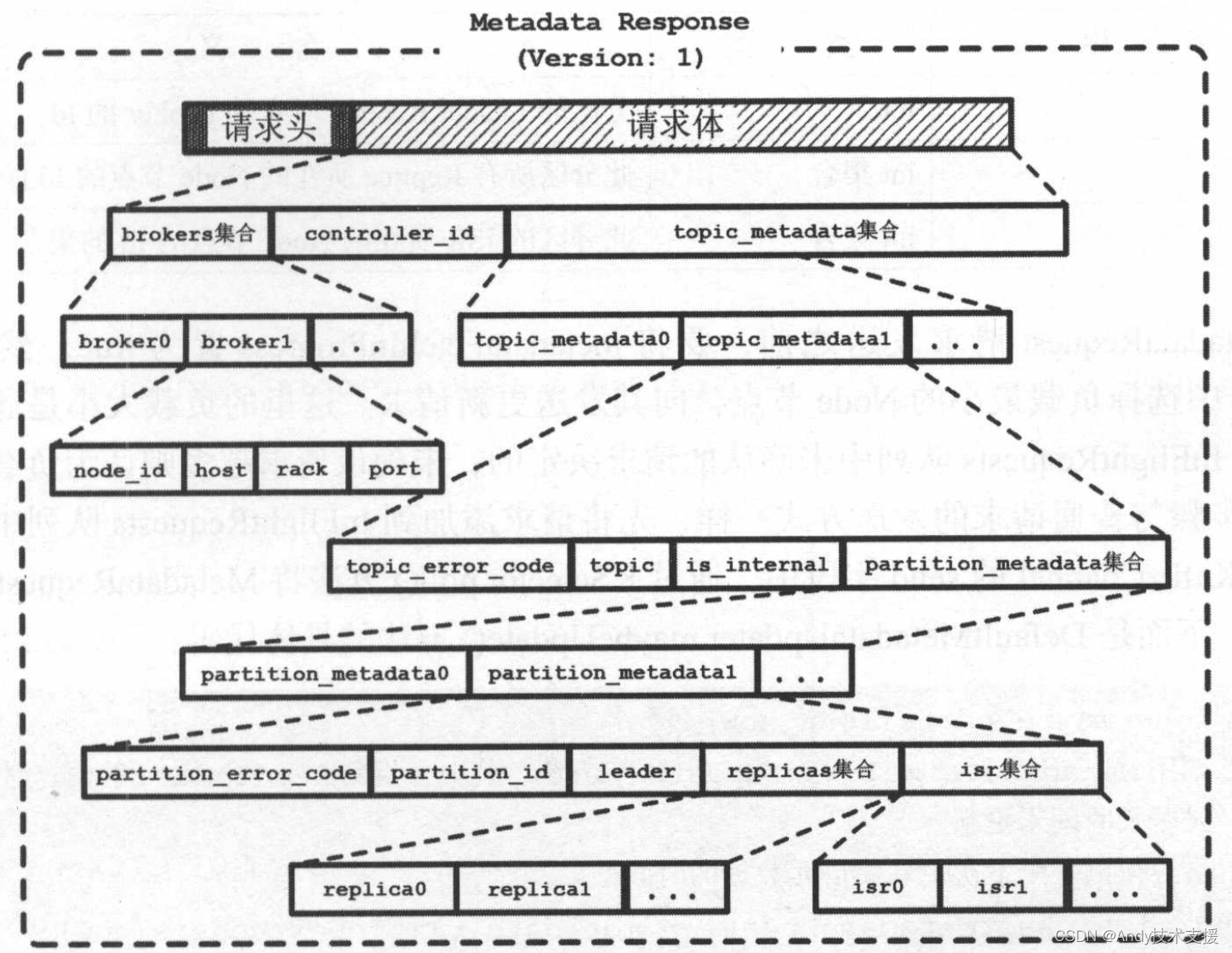
MetadataRequest请求发送之前,要将metadataFetchInProgress置为true,然后从所有Node中选择负载最小的Node节点,向其发送更新请求。
这里的负载大小是通过每个Node在InFlightRequests队列中未确认的请求决定的,未确认请求越多则认为负载越大。
剩余的步骤与普通请求的发送方式一样,先将请求添加到InFlightRequests队列中,然后设置到KafkaChannel的send字段中,通过KSelector.poll方法将MetadataRequest请求发送出去。下面是DefaultMetadataUpdater.maybeUpdate()方法的具体代码:


在收到MetadataResponse之后,会先调用MetaUpdater.handleSuccessfulResponse方法检测是否为MetadataResponse,如果是,则调用handleResponse()解析响应,并构造Cluster对象更新Metadata.cluster字段。
注意,Cluster是不可变对象,所以更新集群元数据的方式是:创建新的Cluster对象,并覆盖Metadata.cluster字段。具体代码如下:

NetworkClient
NetworkClient中所有连接的状态由ClusterConnectionStates管理,它底层使用Map<String,NodeConnectionState>实现,key是Nodeld,value是NodeConnectionState对象,其中使用ConnectionState枚举表示连接状态,还记录了最近一次尝试连接的时间戳。
前面已经介绍完了NetworkClient依赖的组件,下面来看一下NetworkClient的实现。NetworkClient是一个通用的网络客户端实现,不只用于生产者发送消息,也可以用于消费者消费消息以及服务端Broker之间的通信。
下面介绍NetworkClient的核心方法。NetworkClient.ready方法用来检查Node是否准备好接收数据。首先通过NetworkClientisReady方法检查是否可以向一个Node发送请求,需要符合以下三个条件,则表示Node已准备好:
- Metadata并未处于正在更新或需要更新的状态。
- 已经成功建立连接且连接正常connectionStates.isConnected(node)。
- InFlightRequests.canSendMore()返回true。
如果NetworkClient.isReady返回false,且满足下面两个条件,则会调用initiateConnect()方法发起连接。 - 连接不能是CONNECTING状态,必须是DISCONNECTED。
- 为了避免网络拥塞,重连不能太频繁,两次重试之间的时间差必须大于重试的退避时间,由reconnectBackoffMs字段指定。
NetworkClient.initiateConnect方法会修改在ClusterConnectionStates中的连接状态,并调用Selectorconnect()方法发起连接。
之后调用Selector.pollSelectionKeys()方法时,判断连接是否建立。如果建立成功,则会将ConnectionState设置为CONNECTED。
NetworkClient.send方法主要是将请求设置到KafkaChannel.send字段,同时将请求添加到InFlightRequests队列中等待响应。
NetworkClient.poll()方法调用KSelector.poll进行网络I/O(参考KSelector小节),并使用handle*()方法对KSelector.poll产生的各种数据和队列进行处理。
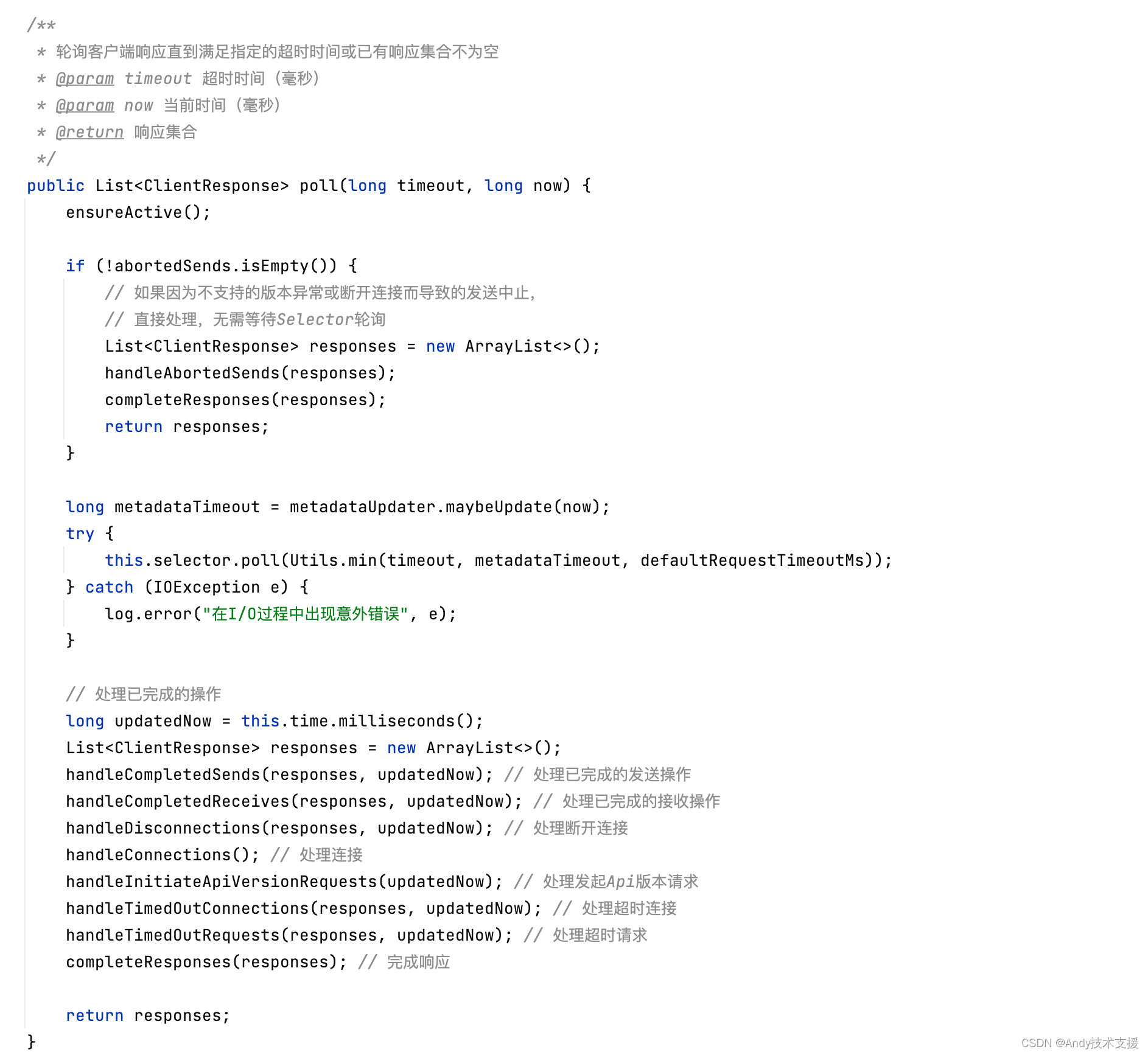
下面来看一下handle*()方法的处理逻辑:
- handleCompletedSends()方法:首先,InFlightRequests保存的是已发送但没收到响应的请求,completedSends保存的是最近一次poll方法中发送成功的请求,所以completedSends列表与InFlightRequests中对应队列的最后一个请求应该是一致的,如图所示。
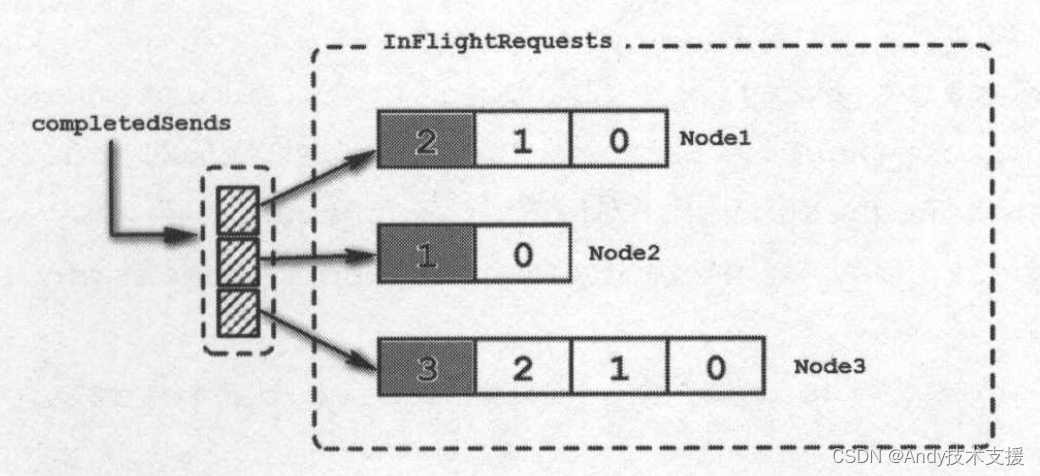
handleCompletedSends()方法会遍历completeSends,如果发现不需要响应的请求,则将其从InFlightRequests中删除,并向responses列表中添加对应的ClientResponse,在ClientResponse中包含一个指向ClientRequest的引用。handleCompletedSends()方法的代码如下:

- handleCompletedReceives()方法: 遍历completedReceives队列,并在InFlightRequests中删除对应的ClientRequest,并向responses列表中添加对应的ClientResponse。如果是Metadata更新请求的响应,则会调用MetadataUpdater中的handleSuccessfulResponse方法,更新Metadata中记录的集Kafka集群元数据。

- handleDisconnections方法:遍历disconnected列表,将InFlightRequests对应节点的ClientRequest清空,对每个请求都创建ClientResponse并添加到responses列表中。这里创建的ClientResponse会标识此响应并不是服务端返回的正常响应,而是因为连接断开产生的。如果是Metadata更新请求的响应,则会调用MetadataUpdater中的handleServerDisconnect方法处理。最后将Metadata.needUpdate设置为true,标识需要更新集群元数据。

- handleConnections方法:遍历connected列表,将ConnectionStates中记录的连接状态修改为CONNECTED。
- handleTimedOutRequests方法:遍历InFlightRequests集合,获取有超时请求的Node集合,之后的处理逻辑与handleDisconnections)方法一样。
经过一系列handle*()方法处理后,NetworkClient.poll()方法中产生的全部ClientResponse已经被收集到responses列表中。
之后,遍历responses调用每个ClientRequest中记录的回调,如果是异常响应则请求重发,如果是正常响应则调用每个消息的自定义Callback。
在前面的createProduceRequests方法中提到过,这里调用的Callback回调对象,也就是RequestCompletionHandler对象,其onComplete方法最终调用Sender.handleProduceResponse()方法,其逻辑如下:
- 如果因为断开连接或异常而产生的响应:
- 遍历ClientRequest中的RecordBatch,则尝试将RecordBatch重新加入RecordAccumulator,重新发送。
- 如果异常类型不允许重试或重试次数达到上限,则执行RecordBatch.done方法,此方法会循环调用RecordBatch中每个消息的Callback函数,并将RecordBatch的produceFuture设置为“异常完成”。最后,释放RecordBatch底层的ByteBuffer。
- 最后,根据异常类型,决定是否设置更新Metadata标志。
- 如果是服务端正常的响应或不需要响应的情况:
- 解析响应。
- 遍历对应ClientRequest中的RecordBatch,执行RecordBatch.done方法。
- 释放RecordBatch底层的ByteBuffer。
下面是Sender.handleProduceResponse()方法的具体代码:















 1838
1838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









