







博文是基于前两篇关于R-CNN和PSP-Net文章来写的,不了解的可以回过去看看再来看这篇。总的来说Fast-RCNN相比前边目标检测的有几个亮点,这里也只说说这几个亮点。
参考博文:http://blog.csdn.net/WoPawn/article/details/52463853?locationNum=5
http://shartoo.github.io/RCNN-series/
Fast-RCNN流程:
1、输入测试图像
2、利用selective search 算法在图像中从上到下提取2000个左右的建议窗口(Region Proposal)
3、将整张图片输入CNN,进行特征提取
4、把建议窗口映射到CNN的最后一层卷积feature map上
5、通过RoI pooling层使每个建议窗口生成固定尺寸的feature map
6、利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练。
图中省略了通过Selective Search获得proposal的过程,第一张图中红框里的内容即为通过Selective Search提取到proposal,中间的一块是经过深度卷积之后得到的conv feature map,图中灰色的部分就是我们红框中的proposal对应于conv feature map中的位置,之后对这个特征经过ROI pooling layer处理,之后进行全连接。在这里得到的ROI feature vector最终被分享,一个进行全连接之后用来做softmax回归,用来进行分类,另一个经过全连接之后用来做bbox回归。
注意: 对中间的Conv feature map进行特征提取。每一个区域经过RoI pooling layer和FC layers得到一个 固定长度 的feature vector(这里需要注意的是,输入到后面RoI pooling layer的feature map是在Conv feature map上提取的,故整个特征提取过程,只计算了一次卷积。虽然在最开始也提取出了大量的RoI,但他们还是作为整体输入进卷积网络的,最开始提取出的RoI区域只是为了最后的Bounding box 回归时使用,用来输出原图中的位置)。
那么重点来了,比较前面的R-CNN和SPP-Net亮点就可以看出来了。
亮点一:
规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取;
亮点二:(作者也是受到何凯明大神的启发得来)
Fast-RCNN提出了一个可以看做单层SPP-Net的网络层(SPP-Net可以回过头看前面留的笔记:http://blog.csdn.net/zhuzemin45/article/details/79589289),叫做ROI Pooling,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量,而我们知道,conv、pooling、relu等操作都不需要固定size的输入,因此,在原始图片上执行这些操作后,虽然输入图片size不同导致得到的feature map尺寸也不同,不能直接接到一个全连接层进行分类,但是可以加入这个神奇的ROI Pooling层,对每个region都提取一个固定维度的特征表示,再通过正常的softmax进行类型识别。
亮点三:
第二点RCNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression,而在Fast-RCNN中,作者巧妙的把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征,并相互促进。Fast-RCNN很重要的一个贡献是成功的让人们看到了Region Proposal+CNN这一框架实时检测的希望,原来多类检测真的可以在保证准确率的同时提升处理速度,也为后来的Faster-RCNN做下了铺垫。
ROI Pooling:
Multi-task loss:
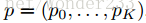
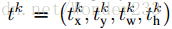
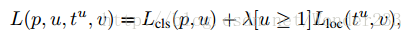
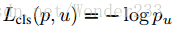
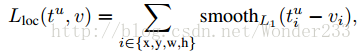
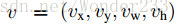 是真实平移缩放参数
是真实平移缩放参数
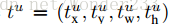
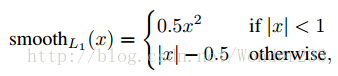
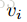 进行归一化使其具有零均值及单位权方差(zero mean and unit variance)。所有的函数都设置超参数 λ = 1。
进行归一化使其具有零均值及单位权方差(zero mean and unit variance)。所有的函数都设置超参数 λ = 1。















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









