









前言
爬虫作为一中数据搜集获取手段,在大数据的背景下,更加得到应用。我在这里只是记录学习的简单的例子。大牛可以直接使用python的url2模块直接抓下来页面,然后自己使用正则来处理,我这个技术屌丝只能依赖于框架,在这里我使用的是Scrapy。
install
首先是python的安装和pip的安装。
sudo apt-get install python python-pip python-dev
然后安装Scrapy
sudo pip install Scrapy
在安装Scrapy的过程中,其依赖于cryptography,在自动安装cryptography编译的过程中,其缺少了libffi库,导致Scrapy安装失败。在安装过程中,库缺少是主要的问题,只要根据安装失败的提示,安装缺少的库就ok了。
sudo apt-get install libffi-dev
我们使用mongodb来保存我们爬取的数据。
sudo apt-get install mongodb
使用pymongo2.7.2
sudo pip install pymongo==2.7.2
过程
创建项目
使用下面的命令来创建一个项目
scrapy startproject csdn
csdn为项目名,其会产生如下结构的目录csdn
.
├── csdn
│ ├── init.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── init.py
└── scrapy.cfg
2 directories, 6 files
我们接着在csdn目录下使用crawl模板来创建一个名为csdn_crawler的爬虫。
scrapy genspider csdn_crawler blod.csdn.net -t crawl
编写爬虫程序
在Scrapy中使用Item来保存一个爬取的项。我们的Item为CsdnItem,其包含两个域(Field),一个为title,另一个为url。
from scrapy.item import Item, Field
class CsdnItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = Field()
url = Field()
pass我们的爬虫
import scrapy
from scrapy.contrib.linkextractors import LinkExtractor
from scrapy.contrib.spiders import CrawlSpider, Rule
from csdn.items import CsdnItem
class CsdnCrawlerSpider(CrawlSpider):
name = 'csdn_crawler'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/zhx6044']
rules = (
Rule(LinkExtractor(allow=r'article/list/[0-9]{1,20}'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = CsdnItem()
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
i['title'] = response.xpath('//*[@id="article_list"]/div[@class="list_item article_item"]/div[@class="article_title"]/h1/span/a/text()').extract()
i['url'] = response.xpath('//*[@id="article_list"]/div[@class="list_item article_item"]/div[@class="article_title"]/h1/span/a/@href').extract()
return iname为这个爬虫的名字,在开始运行爬虫的时候开始运行。
allowed_domains为爬虫针对的域名。
start_urls为爬虫开始的URL,后续的URL从这里开始。
rules为继续爬取的规则。这里的规则来之
下一页的链接为:article/list/xxxxxx为第几页。callback为有符合规则的链接时该调用的方法。
parse_item是爬虫默认处理页面内容的方法,只需重写即可。
下面最大的问题,就是怎么提取到文章的Title和URL。这里我们使用了Xpath,简单的来说这就通过规则匹配来提取到我们想要的内容。
下面,我们就要分析页面。
首先通过chromium的开发者工具找到我们需要的部分。
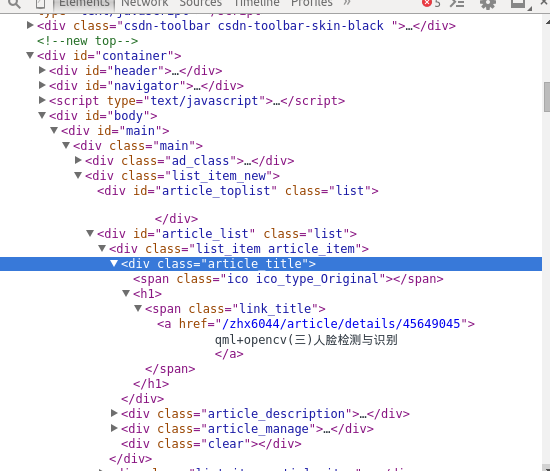
然后在
<a href="/zhx6044/article/details/45649045">
qml+opencv(三)人脸检测与识别
</a>上右键选择Copy XPath,得到的是//*[@id=”article_list”]/div[1]/div[1]/h1/span/a,这个是第一条文章记录,第二条就是//*[@id=”article_list”]/div[2]/div[1]/h1/span/a,显然这个是不行的,我们不能改div[x]中的数值来索引条目,那么我们可以使用其class名来,它们都是一样的,所以就有了
i['title'] = response.xpath('//*[@id="article_list"]/div[@class="list_item article_item"]/div[@class="article_title"]/h1/span/a/text()').extract()
i['url'] = response.xpath('//*[@id="article_list"]/div[@class="list_item article_item"]/div[@class="article_title"]/h1/span/a/@href').extract()text()得出的文本就是标题,@herf得到的就是链接,extract以unicode编码返回。
现在的到了CsdnItem,我们需要将他们保存起来,那么就需要用到PiepLine
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class CsdnPipeline(object):
def __init__(self):
connection = pymongo.Connection(settings['MONGODB_SERVER'], settings['MONGODB_PORT'])
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing data!")
if valid:
#self.collection.update({'url':item['url']}, dict(item), upsert = True)
self.collection.insert(dict(item))
log.msg("Article add to mongodb database!",level = log.DEBUG, spider = spider)
return item
其process_item方法处理的Item就是csdn_crawler中得到的。
还有一个settings.py,我们在系统保存参数
BOT_NAME = 'csdn'
DOWNLOAD_DELAY = 5
SPIDER_MODULES = ['csdn.spiders']
NEWSPIDER_MODULE = 'csdn.spiders'
ITEM_PIPELINES = {'csdn.pipelines.CsdnPipeline':1000,}
MONGODB_SERVER="localhost"
MONGODB_PORT=27017
MONGODB_DB="csdn"
MONGODB_COLLECTION="article"DOWNLOAD_DELAY避免一直爬去这个域名,导致其负载较大,但是对我们这样小规模的爬去,没什么作用。
运行
使用scrapy crawl csdn_crawler运行爬虫。
这是我们其中的一些输出
2015-05-13 21:05:01+0800 [scrapy] INFO: Enabled extensions: LogStats, TelnetConsole, CloseSpider, WebService, CoreStats, SpiderState
2015-05-13 21:05:02+0800 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-05-13 21:05:02+0800 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-05-13 21:05:02+0800 [scrapy] INFO: Enabled item pipelines: CsdnPipeline
2015-05-13 21:05:02+0800 [csdn_crawler] INFO: Spider opened
2015-05-13 21:05:02+0800 [csdn_crawler] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-05-13 21:05:02+0800 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2015-05-13 21:05:02+0800 [scrapy] DEBUG: Web service listening on 127.0.0.1:6080
2015-05-13 21:05:04+0800 [csdn_crawler] DEBUG: Crawled (200) <GET http://blog.csdn.net/zhx6044> (referer: None)
2015-05-13 21:05:09+0800 [csdn_crawler] DEBUG: Crawled (200) <GET http://blog.csdn.net/zhx6044/article/list/2> (referer: http://blog.csdn.net/zhx6044)
2015-05-13 21:05:09+0800 [csdn_crawler] DEBUG: Article add to mongodb database!
2015-05-13 21:05:09+0800 [csdn_crawler] DEBUG: Scraped from <200 http://blog.csdn.net/zhx6044/article/list/2>
{'title': [u'\r\n PHP\u4f7f\u7528CURL\u8fdb\u884cPOST\u64cd\u4f5c\u65f6\r\n ',
u'\r\n \u4ecestoryboard\u52a0\u8f7d\u89c6\u56fe\u63a7\u5236\u5668\r\n ',
u'\r\n PHP\u5f97\u5230POST\u4e0a\u6765\u7684JSON\u6570\u636e\r\n ',
u'\r\n Docker\r\n ',
u'\r\n Haproxy+nginx+php\r\n ',
u'\r\n php curl\r\n ',
u'\r\n \u5de5\u4f5c\u534a\u5e74\r\n ',
u'\r\n \u57fa\u4e8enginx_http_push_module\u6a21\u5757\u8ba9nginx\u53d8\u6210Comet Server\r\n ',
u'\r\n \u5728\u5185\u7f51\u67b6\u8bbe\u4e00\u4e2a\u53ef\u4f9b\u5916\u7f51\u767b\u5f55\u7684ftp\u670d\u52a1\u5668\r\n ',
u'\r\n REST,http,\u670d\u52a1\u5668\u5f00\u53d1\r\n ',
u'\r\n \u9634\u5dee\u9633\u9519\u53c8\u505a\u8d77linux\u6765\r\n ',
u'\r\n \u57fa\u4e8eTCP\u534f\u8bae\u7684\u89c6\u9891\u4f20\u8f93\r\n ',
u'\r\n \u5bb6\u4eba\u91cd\u75c5\u4ec0\u4e48\u5fc3\u60c5\u90fd\u6ca1\u4e86\r\n ',
u'\r\n opencv\u5b9e\u73b0\u8fb9\u7f18\u68c0\u6d4b\r\n ',
u'\r\n opencv\u5b9e\u73b0\u591a\u8def\u64ad\u653e\r\n '],
'url': [u'/zhx6044/article/details/43418115',
u'/zhx6044/article/details/43418011',
u'/zhx6044/article/details/43417923',
u'/zhx6044/article/details/43417701',
u'/zhx6044/article/details/43240585',
u'/zhx6044/article/details/42804333',
u'/zhx6044/article/details/42646439',
u'/zhx6044/article/details/42040943',
u'/zhx6044/article/details/41051061',
u'/zhx6044/article/details/40789909',
u'/zhx6044/article/details/40592187',
u'/zhx6044/article/details/40016929',
u'/zhx6044/article/details/39970089',
u'/zhx6044/article/details/39256473',
u'/zhx6044/article/details/39033141']}
2015-05-13 21:05:09+0800 [csdn_crawler] DEBUG: Filtered duplicate request: <GET http://blog.csdn.net/zhx6044/article/list/3> - no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates)
2015-05-13 21:05:15+0800 [csdn_crawler] DEBUG: Crawled (200) <GET http://blog.csdn.net/zhx6044/article/list/14> (referer: http://blog.csdn.net/zhx6044)
2015-05-13 21:05:15+0800 [csdn_crawler] DEBUG: Article add to mongodb database!
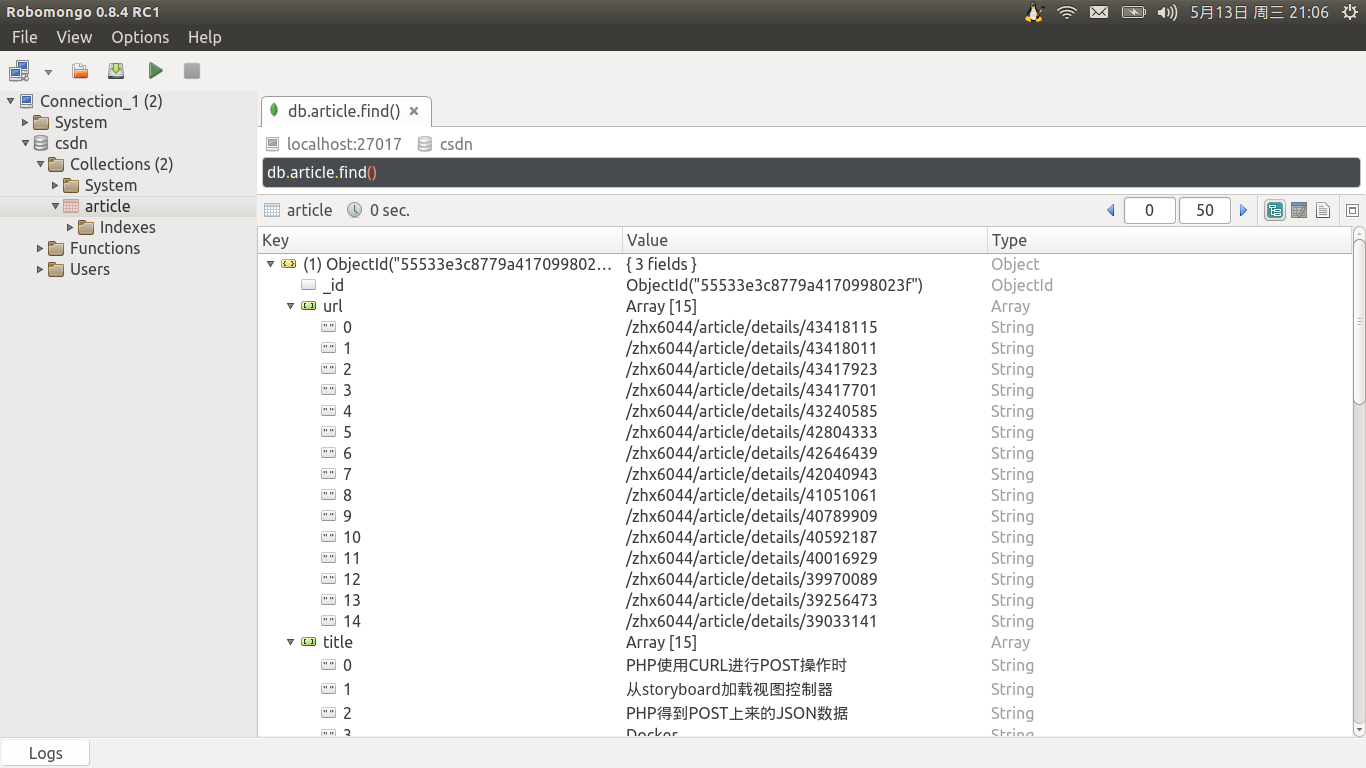
2015-05-13 21:05:15+0800 [csdn_crawler] DEBUG: Scraped from <200 http://blog.csdn.net/zhx6044/article/list/14>mongodb中的数据
整个代码可以在这里获得。















 4079
4079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









