







一、作用
Logistic regression可以用来回归,也可以用来分类,主要是二分类。
参考:http://www.lovedata.cn/focus/351.html
1) 可用于概率预测,也可用于分类。
2) 仅能用于线性问题
3) 各feature之间不需要满足条件独立假设,但各个feature的贡献是独立计算的。
二、基本原理
1. 什么是回归
参考:http://www.lovedata.cn/focus/351.html
回归其实就是对已知公式的未知参数进行估计。大家可以简单的理解为,在给定训练样本点和已知的公式后,对于一个或多个未知参数,机器会自动枚举参数的所有可能取值(对于多个参数要枚举它们的不同组合),直到找到那个最符合样本点分布的参数(或参数组合)。(当然,实际运算有一些优化算法,肯定不会去枚举的)
2. 线性回归
根据往年数据找出最佳的参数a, b,c....的取值,使 y = a * x + by+cz+........ 在所有样本集上误差最小。
以卖鞋为例,y表示销售额sell
线性回归能过获得好效果的前提是y = a*x + b 至少从总体上是有道理的(因为我们认为鞋子越贵,卖的数量越少,越便宜卖的越多。另外鞋子质量、广告投入、客流量等都有类似规律);但并不是所有类型的变量都适合用线性回归,比如说x不是鞋子的价格,而是鞋子的尺码),那么无论回归出什么样的(a,b),错误率都会极高(因为事实上尺码太大或尺码太小都会减少销量)。总之:如果我们的公式假设是错的,任何回归都得不到好结果。
3. 逻辑回归
以下内容转载自:
http://blog.csdn.net/zouxy09/article/details/20319673
假设我们的样本是{x, y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:
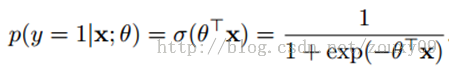
这里θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
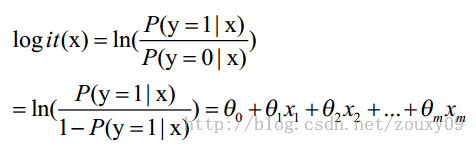
换句话说,y也就是我们关系的变量,例如她喜不喜欢你,与多个自变量(因素)有关,例如你人品怎样、车子是两个轮的还是四个轮的、长得胜过潘安还是和犀利哥有得一拼、有千尺豪宅还是三寸茅庐等等,我们把这些因素表示为x1, x2,…, xm。那这个女的怎样考量这些因素呢?最快的方式就是把这些因素的得分都加起来,最后得到的和越大,就表示越喜欢。但每个人心里其实都有一杆称,每个人考虑的因素不同,萝卜青菜,各有所爱嘛。例如这个女生更看中你的人品,人品的权值是0.6,不看重你有没有钱,没钱了一起努力奋斗,那么有没有钱的权值是0.001等等。我们将这些对应x1, x2,…, xm的权值叫做回归系数,表达为θ1, θ2,…, θm。他们的加权和就是你的总得分了。请选择你的心仪男生,非诚勿扰!哈哈。
所以说上面的logistic回归就是一个线性分类模型,它与线性回归的不同点在于:为了将线性回归输出的很大范围的数,例如从负无穷到正无穷,压缩到0和1之间,这样的输出值表达为“可能性”才能说服广大民众。当然了,把大值压缩到这个范围还有个很好的好处,就是可以消除特别冒尖的变量的影响(不知道理解的是否正确)。而实现这个伟大的功能其实就只需要平凡一举,也就是在输出加一个logistic函数。另外,对于二分类来说,可以简单的认为:如果样本x属于正类的概率大于0.5,那么就判定它是正类,否则就是负类。实际上,SVM的类概率就是样本到边界的距离,这个活实际上就让logistic regression给干了。
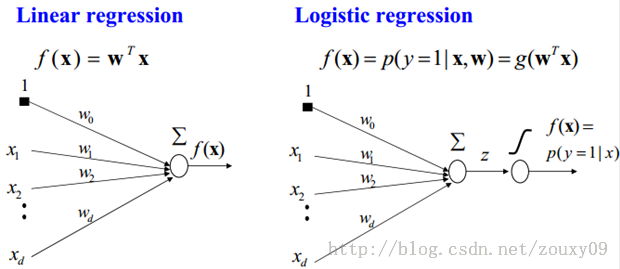
所以说,LogisticRegression 就是一个被logistic方程归一化后的线性回归,仅此而已。
好了,关于LR的八卦就聊到这。归入到正统的机器学习框架下,模型选好了,只是模型的参数θ还是未知的,我们需要用我们收集到的数据来训练求解得到它。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









