









1. 前言
今天老板甩过来一套这学期的数据采集课程的学生考试试卷, 让我统计一下分数, 那就统计呗。 结果, 突然发现, 考试试卷的出现顺序和学生信息表上的顺序是不一致的, 我们当然可以手工输入一下, 可是本人还是比较懒, 不喜欢玩这种无效劳动, 于是就想着, 能不能自动合并数据项呢?于是, 我们想到了数据库, 然后一整天都花在研究如何将数据导入到数据库中去, 这个问题上了。。。。。
弄完之后, 感觉用牛刀杀鸡还是蛮爽的, 哈哈~~
2. 处理流程
2.1 使用excel 录入学生期末考试信息
没办法, 这个步骤是省略不了的, 虽然, 我们非常希望能够, 有个设备能够自动检测卷面上的分数信息, 然后, 自动录入到pc中。。。。
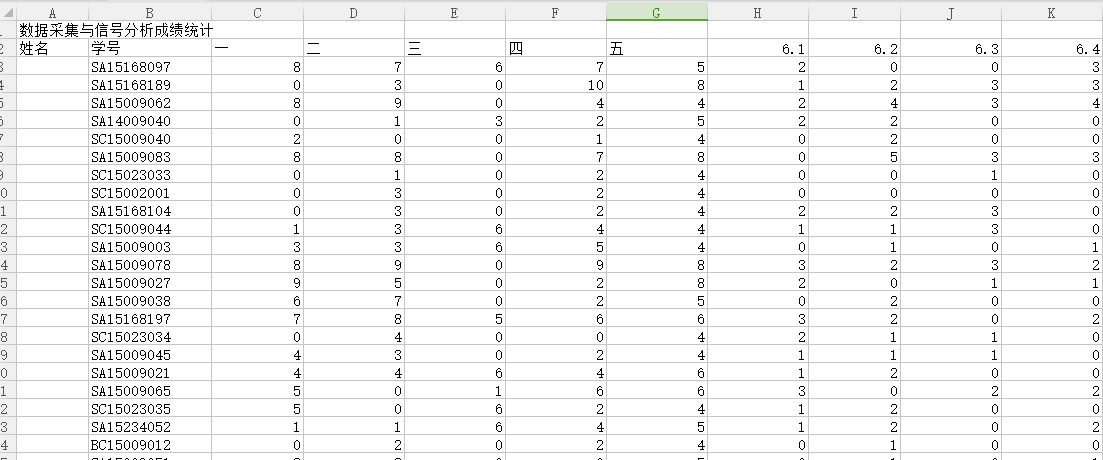
然后是平时成绩信息表
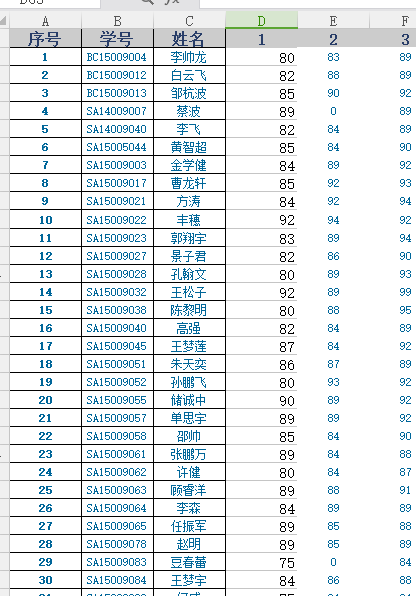
之前已经说了, 我们需要根据学号信息, 将这两张表格连接起来, 但是, 这里我们想装逼一下, 于是就想使用数据库来处理这个问题。。。。。
2.2 从excel 导出所需要的相应表数据
我们首先导出3个txt 文件, 对应我们 3 个数据库的初始信息
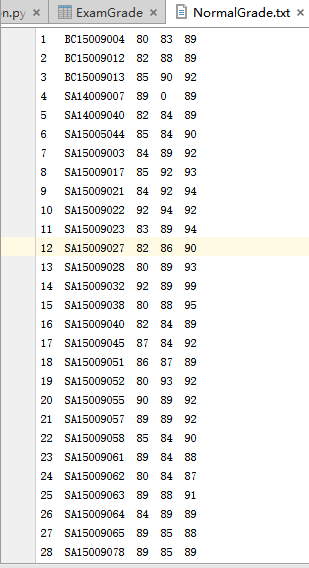
NormalGrade.txt
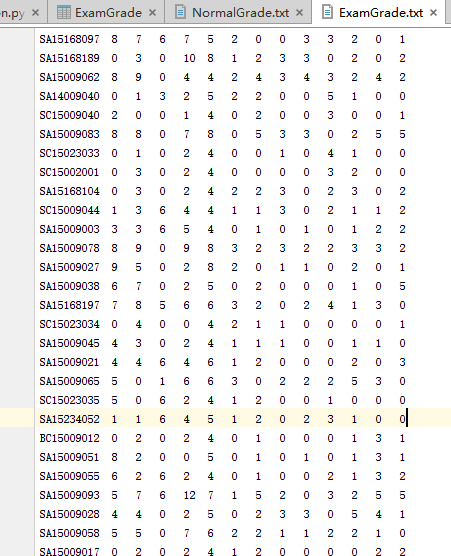
ExamGrade.txt
StudentInfo.txt
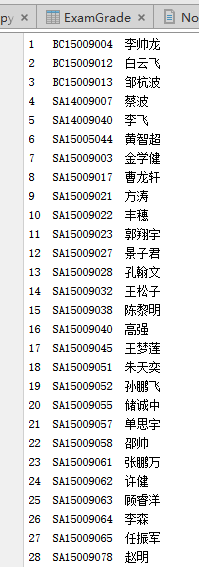
2.3 使用sqlalchemy 建立相应的表对象
- 首先需要普及一下 sqlalchemy: http://docs.sqlalchemy.org/en/latest/orm/tutorial.html
- sqlalchemy ORM是一个对象关系数据库映射模型, 通过这个框架, 我们可以通过操作对象的方式, 方便的操作我们的底层数据库, 当然, 也支持数据库的更改
2.3.1 设计数据库表对象
StudentInfo
id 为主键, stu_id 为学生学号信息, stu_name 为学生姓名class StudentInfo(Base): ''' 学生选课信息表 ''' __tablename__ = 'StudentInfo' id = Column(Integer, primary_key=True, autoincrement=True) stu_id = Column(String) stu_name = Column(String) def __repr__(self): return "<StudentInfo(stu_id=%s, stu_name=%s)>" % (self.stu_id, self.stu_name)NormalGrade
id, 为主键, stu_id 为学生的学号信息, gradeX 为 平时成绩信息class NormalGrade(Base): ''' 学生平时成绩表 ''' __tablename__ = 'NormalGrade' id = Column(Integer, primary_key=True, autoincrement=True) stu_id = Column(String) grade1 = Column(Integer) grade2 = Column(Integer) grade3 = Column(Integer) def __repr__(self): return "<StudentInfo(stu_id=%s, grade1=%s, grade2=%s, grade3=%s)>" % (self.stu_id, self.grade1, self.grade2, self.grade3)ExamGrade
ps: id 为表的主键, stu_id 为学生的学号信息, gradeXX 表示试卷各个小题的扣分情况, 满分100class ExamGrade(Base): ''' 学生期末考试成绩表 ''' __tablename__ = 'ExamGrade' id = Column(Integer, primary_key=True, autoincrement=True) stu_id = Column(String) grade1 = Column(Integer) grade2 = Column(Integer) grade3 = Column(Integer) grade4 = Column(Integer) grade5 = Column(Integer) grade61 = Column(Integer) grade62 = Column(Integer) grade63 = Column(Integer) grade64 = Column(Integer) grade65 = Column(Integer) grade66 = Column(Integer) grade67 = Column(Integer) grade68 = Column(Integer) def __repr__(self): return "<StudentInfo(stu_id=%s, grade1=%s, grade2=%s, grade3=%s, grade4=%s, grade5=%s, grade61=%s, grade62=%s, grade63=%s, grade64=%s, grade65=%s, grade66=%s, grade67=%s, grade68=%s)>" \ % (self.stu_id, self.grade1, self.grade2, self.grade3, self.grade4, self.grade5, self.grade61, self.grade62, self.grade63, self.grade64, self.grade65, self.grade66, self.grade67, self.grade68)
2.3.2 插入学生信息
主要借助session的add_all 方法
2.3.3 查询数据库
使用多表查询即可, 借助session的query 方法
3. 遇到的问题
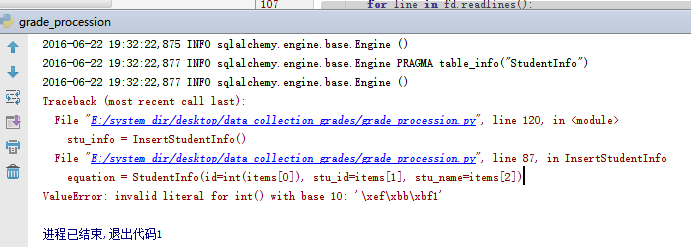
文件编码问题
这里面解析到了 字符: ‘\xef\xbb\xbf1’, 网上查询之后发现, 这是UTF 带BOM 格式, 将文件数据改成 不带 BOM 的utf8 格式即可, (ps: 编码格式真讨厌!!!)字符编码问题
我们解析出来的字符, 不是utf8格式的, 而sqlalchemy 框架建议使用 unicode 进行转换sqlalchemy 查询操作
出现这个问题, 主要是因为我们希望使用字符串形式来处理数据库, ie, 使用原始sql 语句来处理, 结果发现不行, 还是得使用sqlalchemy orm 提供的api 处理

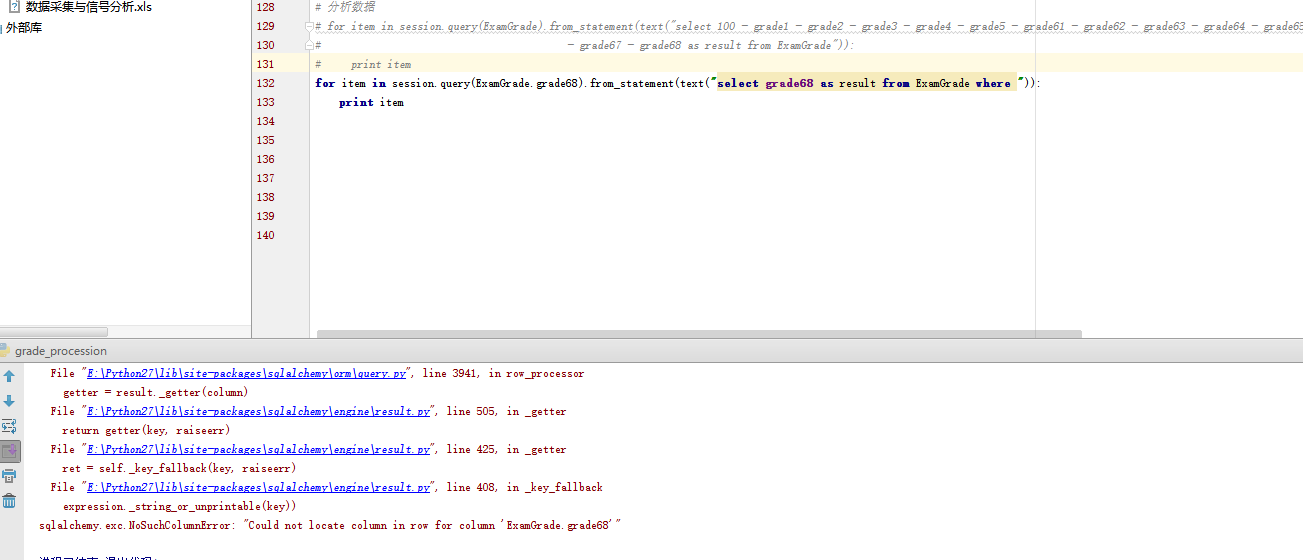
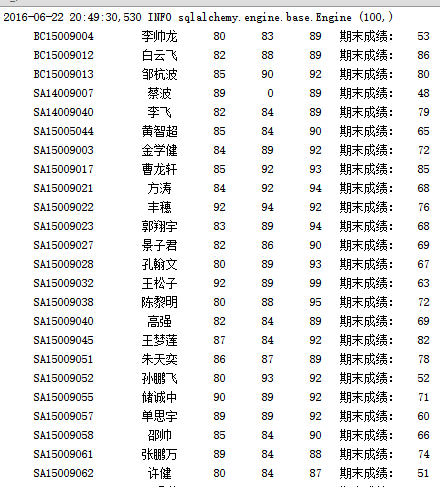
4. 处理效果
5. 实现代码
# -*- coding:utf8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import sqlalchemy
from sqlalchemy import create_engine, text
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, String, Integer
from sqlalchemy.orm import sessionmaker, aliased
import os
# 创建数据库表对象
engine = create_engine("sqlite:///grades.db", echo = True)
Base = declarative_base()
class StudentInfo(Base):
'''
学生选课信息表
'''
__tablename__ = 'StudentInfo'
id = Column(Integer, primary_key=True, autoincrement=True)
stu_id = Column(String)
stu_name = Column(String)
def __repr__(self):
return "<StudentInfo(stu_id=%s, stu_name=%s)>" % (self.stu_id, self.stu_name)
class NormalGrade(Base):
'''
学生平时成绩表
'''
__tablename__ = 'NormalGrade'
id = Column(Integer, primary_key=True, autoincrement=True)
stu_id = Column(String)
grade1 = Column(Integer)
grade2 = Column(Integer)
grade3 = Column(Integer)
def __repr__(self):
return "<StudentInfo(stu_id=%s, grade1=%s, grade2=%s, grade3=%s)>" % (self.stu_id, self.grade1, self.grade2, self.grade3)
class ExamGrade(Base):
'''
学生期末考试成绩表
'''
__tablename__ = 'ExamGrade'
id = Column(Integer, primary_key=True, autoincrement=True)
stu_id = Column(String)
grade1 = Column(Integer)
grade2 = Column(Integer)
grade3 = Column(Integer)
grade4 = Column(Integer)
grade5 = Column(Integer)
grade61 = Column(Integer)
grade62 = Column(Integer)
grade63 = Column(Integer)
grade64 = Column(Integer)
grade65 = Column(Integer)
grade66 = Column(Integer)
grade67 = Column(Integer)
grade68 = Column(Integer)
def __repr__(self):
return "<StudentInfo(stu_id=%s, grade1=%s, grade2=%s, grade3=%s, grade4=%s, grade5=%s, grade61=%s, grade62=%s, grade63=%s, grade64=%s, grade65=%s, grade66=%s, grade67=%s, grade68=%s)>" \
% (self.stu_id, self.grade1, self.grade2, self.grade3, self.grade4, self.grade5, self.grade61, self.grade62, self.grade63, self.grade64, self.grade65, self.grade66, self.grade67, self.grade68)
# 建立表
Base.metadata.create_all(engine)
Session = sessionmaker(bind = engine)
session = Session()
def InsertStudentInfo():
equations = []
with open("StudentInfo.txt") as fd:
for line in fd.readlines():
items = line.strip().split('\t')
if len(items) < 3:
continue
equation = StudentInfo(id=int(items[0]), stu_id=items[1], stu_name=unicode(items[2]))
# equation = 'StudentInfo(id="%s", stu_id="%s", stu_name="%s")' % (items[0], items[1], items[2])
equations.append(equation)
return equations
def InsertNormalGrade():
equations = []
with open("NormalGrade.txt") as fd:
for line in fd.readlines():
items = line.strip().split('\t')
if len(items) < 5:
continue
equation = NormalGrade(id=items[0], stu_id=items[1], grade1=items[2], grade2=items[3], grade3=items[4])
# equation = 'NormalGrade(id="%s", stu_id="%s", grade1="%s", grade2="%s", grade3="%s")' % (items[0], items[1], items[2], items[3], items[4])
equations.append(equation)
return equations
def InsertExamGrade():
equations = []
with open("ExamGrade.txt") as fd:
for line in fd.readlines():
items = line.strip().split('\t')
if len(items) < 14:
continue
equation = ExamGrade(stu_id=items[0], grade1=items[1], grade2=items[2], grade3=items[3], grade4=items[4], grade5=items[5], grade61=items[6], grade62=items[7],
grade63=items[8], grade64=items[9], grade65=items[10], grade66=items[11], grade67=items[12], grade68=items[13])
# equation = 'ExamGrade(stu_id="%s", grade1="%s", grade2="%s", grade3="%s", grade4="%s", grade5="%s", grade61="%s", grade62="%s", \
# grade63="%s", grade64="%s", grade65="%s", grade66="%s", grade67="%s", grade68="%s")' % (items[0], items[1], items[2],
# items[3], items[4], items[5], items[6], items[7],items[8], items[9], items[10],items[11], items[12], items[13])
equations.append(equation)
return equations
# 实现将成绩信息录入到数据库中
stu_info = InsertStudentInfo()
normal_grade = InsertNormalGrade()
exam_grade = InsertExamGrade()
session.add_all(stu_info)
session.add_all(normal_grade)
session.add_all(exam_grade)
session.commit()
# 分析数据
# 将平时成绩和期末成绩合并到同一张表中
for stu_id, name, grade1, grade2, grade3, exam_grade in session.query(StudentInfo.stu_id, StudentInfo.stu_name, NormalGrade.grade1, NormalGrade.grade2, NormalGrade.grade3,
100 - ExamGrade.grade1 - ExamGrade.grade2 - ExamGrade.grade3 - ExamGrade.grade4 - ExamGrade.grade5 - ExamGrade.grade61
- ExamGrade.grade62 - ExamGrade.grade63 - ExamGrade.grade64 - ExamGrade.grade65 - ExamGrade.grade66 - ExamGrade.grade67
- ExamGrade.grade68).filter(StudentInfo.stu_id == ExamGrade.stu_id)\
.filter(NormalGrade.stu_id == StudentInfo.stu_id):
print "%15s\t%10s\t%5s\t%5s\t%5s\t期末成绩:%5s" % (stu_id, name, grade1, grade2, grade3, exam_grade)














 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









