







PaddleSpeech是百度飞桨(PaddlePaddle)深度学习平台下的一个语音服务工具包,飞桨官网它提供了一系列功能,包括语音识别、语音翻译、语音合成等。例如PaddleNLP
PaddleSpeech基于飞桨的语音方向模型库,支持大量基于深度学习前沿和有影响力的模型,为开发者提供了便捷、高效的语音处理解决方案。
PaddleSpeech特别关注于解决实际应用中的挑战,例如中英文混合语音识别。为了应对这种多语言混合的挑战,PaddleSpeech发布了一个中英文语音识别预训练模型Conformer_talcs,这个模型可以通过PaddleSpeech封装的命令行工具CLI或者Python接口快速使用。开发者可以利用这个模型来搭建自己的智能语音应用,或者参考示例训练自己的中英文语音识别模型。
一、概要
PaddleSpeech是PaddlePaddle的子项目,随着人工智能技术的发展,语音合成技术(Text-to-Speech,简称TTS)在各个领域的应用越来越广泛,如智能客服、有声读物、语音助手等。PaddleSpeech,作为PaddlePaddle生态下的语音工具包,为我们提供了一个高效、易用的平台来训练自己的TTS模型,飞酱aistudio很多好玩的东西,非常值得关注。
PaddleSpeech的应用场景广泛,包括但不限于智能内容创作、AI数字人、AI数据分析、智能客服、智能办公等行业智能应用。通过PaddleSpeech,开发者可以构建具有语音识别能力的智能应用,从而提升用户体验和效率。此外,PaddleSpeech还支持通过自定义数据集进行模型训练,使得开发者能够根据具体的应用场景优化模型,提高识别的准确性和适应性
PaddleSpeech还支持自定义数据集训练,允许用户根据自己的需求进行模型训练。这包括准备自定义的数据集,进行数据预处理,以及选择合适的模型进行训练。PaddleSpeech提供了丰富的数据预处理工具和多种语音识别模型,如DeepSpeech、Conformer等,以满足不同场景下的语音识别需求。
二、环境准备
在开始使用PaddleSpeach之前,我们需要确保已经安装了PaddlePaddle、PaddleSpeech以及Python环境。我们本次安装的是CPU版本,因为作者的电脑独立显卡是AMD的,目前speach对AMD显卡支持的不太友好,且只支持预测不支持训练,但是对英伟达的支持非常友好,所以鉴于本身机器硬件本身的限制,GPU版本的暂时先不安装。如果你对GPU特别感兴趣,可以参考作者之前写的英伟达并行运算CUDA介绍。
- 操作系统:
Win10操作系统
Microsoft Windows [版本 10.0.18363.592]
(c) 2019 Microsoft Corporation。保留所有权利。- Python环境:
python --version
Python 3.8.10- paddle主要安装依赖关系
Package Version
--------------------------- -----------
numba 0.58.1
numpy 1.24.4
omegaconf 2.3.0
onnx 1.16.2
onnxruntime 1.19.2
OpenCC 1.1.9
opencc-python-reimplemented 0.1.6
opencv-python 4.6.0.66
opt-einsum 3.3.0
packaging 23.2
paddle-bfloat 0.1.7
paddle2onnx 1.0.6
paddleaudio 1.1.0
paddlefsl 1.1.0
paddlenlp 2.5.2
paddlepaddle 2.4.2
paddlesde 0.2.5
paddleslim 2.6.0
paddlespeech 1.4.1
paddlespeech-feat 0.1.0
pandas 2.0.3
parameterized 0.9.0
parso 0.8.4
pathos 0.2.8特别说明:
PaddlePaddle是独立的平台,PaddleSpeach只是基于它的应用之一,故而两个是独立的项目,所以在安装时候各个版本的依赖关系非常重要,如果版本依赖没搞明白,即时安装成功,在实际的运行中也会遇到各种问题。
目前测试下来,能够正常运行的版本,即本地基于window10 的搭建版本:
- wind10操作系统
- Python:3.8.10
- Paddlepaddle:2.4.2
- Paddlespeech:1.4.1
- Paddlenlp:2.5.2
三、安装步骤
1,静态镜像地址:
- https://pypi.tuna.tsinghua.edu.cn/simple #清华
- http://mirrors.aliyun.com/pypi/simple/ #阿里云
- https://pypi.mirrors.ustc.edu.cn/simple/ #中国科技大学
- http://pypi.hustunique.com/ #华中理工大学
- http://pypi.sdutlinux.org/ #山东理工大学
- http://pypi.douban.com/simple/ #豆瓣
2,Paddlepaddle安装
指定版本安装,否则会安装最新的发布版本2.6.1(与speach不兼容)
python -m pip install paddlepaddle==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple如果之前安装过其他版本,请先卸载,再安装
pip uninstall paddlepaddle如果安装过程遇到其他问题,可以根据要求降低相关配置,本机实例遇到仅供参考
# 降版本
pip install onnx==1.12.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install protobuf==3.20.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install opencc-python-reimplemented==0.1.62,Paddlespeech安装
指定版本安装,否则会安装最新的发布版本1.4.1(导致与paddlepaddle不兼容)
python -m pip install paddlespeech==1.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple如果之前安装过其他版本,请先卸载,再安装
pip uninstall paddlespeech3,paddlenlp安装
由于执行过以上两个安装命令,paddlenlp因为是模块的依赖模块,多以会在动安装上,但是由于自动安装依赖版本,安装的是网上最新的可用版本,故而在安装时候会有很多依赖需要降级。
通过如下指令查看依赖版本号
pip list如果版本过高,需要先卸载已安装的版本
pip uninstall paddlenlp在安装指定版本的paddlenlp
python -m pip install paddlenlp==2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simple四、简单的命令行测试
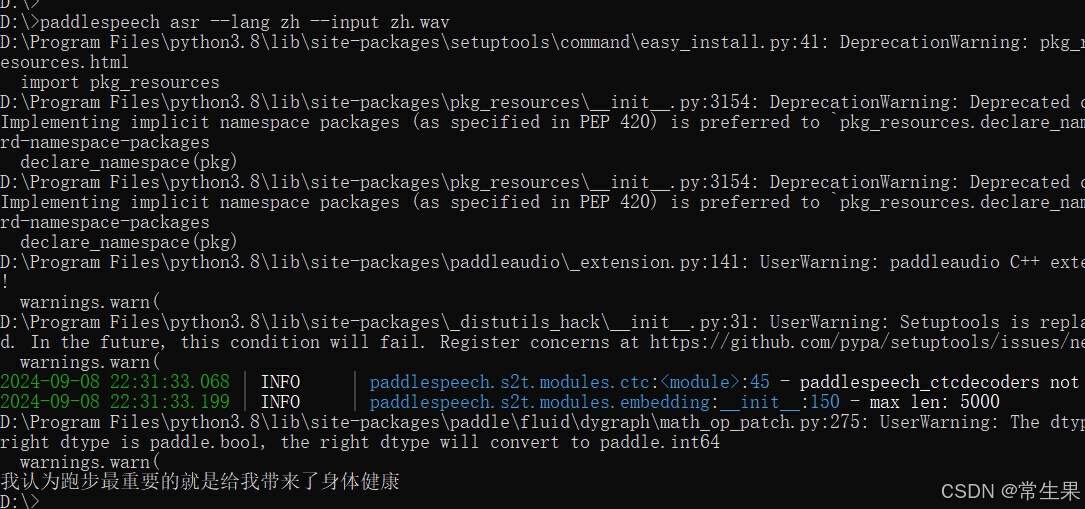
- 语音识别:paddlespeech asr --lang zh --input zh.wav
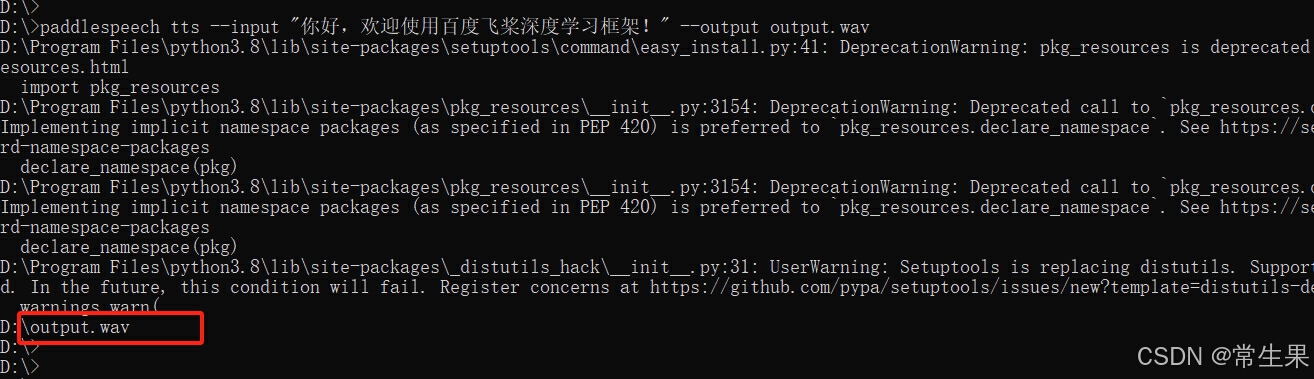
- 语音合成:paddlespeech tts --input "你好,欢迎使用百度飞桨深度学习框架!" --output output.wav
-
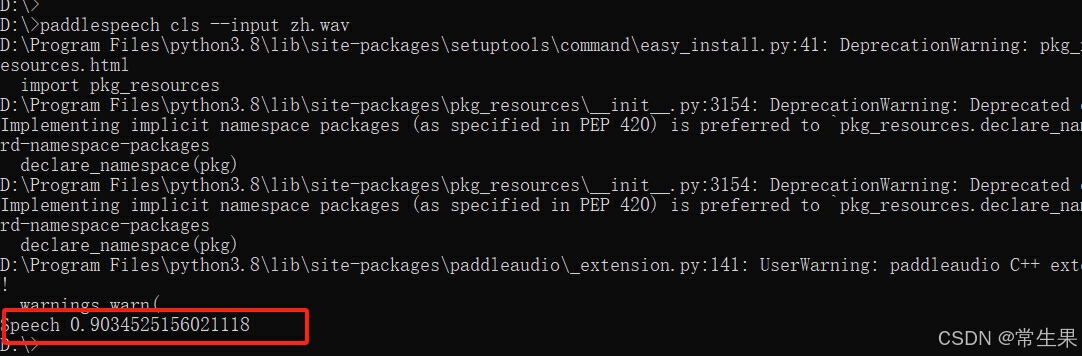
声音分类:paddlespeech cls --input zh.wav
-
声纹提取:paddlespeech vector --task spk --input zh.wav
-
标点恢复:paddlespeech text --task punc --input "今天的你下午有空我想约你一起去吃饭"
-
语音翻译: paddlespeech st --input en.wav
-
中英识别:paddlespeech asr --model conformer_talcs --lang zh_en --codeswitch True --input ./ch_zh_mix.wav -v(指定模型)
指定模型相关参数
- paddlespeech asr --model conformer_wenetspeech --lang zh --input zh.wav
- paddlespeech asr --model conformer_talcs --lang zh_en --codeswitch True --input ./ch_zh_mix.wav -v
- paddlespeech tts --input "湖北十堰竹山县的桃花摇曳多姿,和蓝天白云一起,构成一幅美丽春景。" --output output.wav --am fastspeech2_csmsc --voc hifigan_csmsc --lang zh --spk_id 174
- paddlespeech tts --input "一家人在广东深圳为孩子举办了升学宴。" --output output.wav --am fastspeech2_csmsc --voc speedyspeech_csmsc --lang zh
五、Python接口体验
1,简单的TTS
from paddlespeech.cli.text.infer import TextExecutor
text_punc = TextExecutor()
result = text_punc(text=u"今天的天气真不错啊你下午有空吗我想约你一起去吃饭")
print(result)2,语音识别
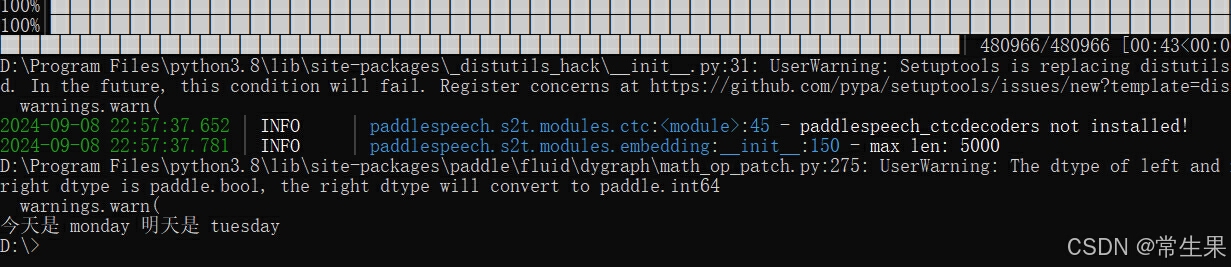
import paddle
from paddlespeech.cli.asr import ASRExecutor
asr_executor = ASRExecutor()
text = asr_executor(
model='conformer_talcs',
lang='zh_en',
sample_rate=16000,
config=None,
ckpt_path=None,
audio_file='./ch_zh_mix.wav',
codeswitch=True,
force_yes=False,
device=paddle.get_device())
print('ASR Result: \n{}'.format(text))
------------------------------
ASR Result:
今天是 monday 明天是tuesday3,分词 DDParser
from ddparser import DDParser
ddp = DDParser(prob=True, use_pos=True)
ddp.parse(["百度是一家高科技公司"])
>>> [{'word': ['百度', '是', '一家', '高科技', '公司'], 'postag': ['ORG', 'v', 'm', 'n', 'n'], 'head': [2, 0, 5, 5, 2], 'deprel': ['SBV', 'HED', 'ATT', 'ATT', 'VOB'], 'prob': [1.0, 1.0, 1.0, 1.0, 1.0]}]4,中英混合识别
import time # 引入time模块
from paddlespeech.cli.tts.infer import TTSExecutor
tts_executor = TTSExecutor()
title ="孙卓已到南京工业大学报到,称学校绿化特别好,还透露“喜欢江南" \
"9月7日,孙卓晒出赴南京工业大学报到、与父母、姐姐在校园打卡的合照,发文称“九月微风轻拂,来到梦开始的地方”。同日,孙卓的妈妈也发布孩子的入学视频,称“为孩子感到高兴和自豪”,视频当中,孙卓也透露自己(报志愿时)想往江浙这边考,比较喜欢江南。"
text = "据荔枝新闻报道,孙卓称这是自己第一次到南京,对南京工业大学的初印象不错:“跟在来之前上网查到的感觉差不多,绿化做得特别好。”孙卓称,早在入学前,学校就联系上他,热心提供入学提醒和指引报到流程,很多提前在线上就完成了,很便利。" \
"据此前报道,2007年10月9日19时许,当时4岁的孙卓在深圳被人拐走。此后孙海洋踏上了四处寻子之路,其经历后来被改编成为打拐电影《亲爱的》中角色原型之一。在警方的努力下,案件于2021年告破,孙海洋得以与失散14年的儿子孙卓认亲团聚。" \
"2024年,孙卓顺利参加高考。7月25日,孙卓通过个人社交账号发布视频称,“OK了家人们,也是有大学上了。”视频晒出的录取通知书显示,孙卓被南京工业大学数理科学学院应用物理学专业录取。" \
"据网介绍,南京工业大学办学历史可溯源于1902年创办的三江师范学堂,2001年由化工部南京化工大学与建设部南京建筑工程学院合并组建。是首批国家“高等学校创新能力提升计划”(2011计划)牵头高校、江苏高水平大学建设高峰计划A类建设高校。学校设有11个学部,28个学院,各类学生4万余人。涵盖工、理、管、经、文、法、医、艺、教9个学科。" \
"13日,孙海洋发布视频称,一家人在广东深圳为孩子举办了升学宴。"
startTime = time.time();
output_file = "mix.wav"
tts_executor(text=title+text, output=output_file,
am="fastspeech2_mix", voc="hifigan_csmsc",
lang="zh", spk_id=174)
print("结束,耗时:"+(time.time()-startTime))
六、持流式ASR /TTS
1,流式ASR
启动流式语音识别服务
paddlespeech_server start --config_file conf/ws_conformer_application.yaml
访问流式语音识别服务
paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input zh.wav
2,流式TTS
启动流式语音合成服务
paddlespeech_server start --config_file conf/tts_online_application.yaml
访问流式语音合成服务
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --input "您好,欢迎使用百度飞桨深度学习框架!" --output output.wav
3,声纹识别
启动声纹识别服务
paddlespeech_server start --config_file conf/vector_application.yaml
获取说话人音频声纹
paddlespeech_client vector --task spk --server_ip 127.0.0.1 --port 8090 --input 85236145389.wav
两个说话人音频声纹打分
paddlespeech_client vector --task score --server_ip 127.0.0.1 --port 8090 --enroll 123456789.wav --test 85236145389.wav
七、预训练模型
模型 语言转换 语言 采样率
conformer_wenetspeech False zh 16k
conformer_online_multicn False zh 16k
conformer_aishell False zh 16k
conformer_online_aishell False zh 16k
transformer_librispeech False en 16k
deepspeech2online_wenetspeech False zh 16k
deepspeech2offline_aishell False zh 16k
deepspeech2online_aishell False zh 16k
deepspeech2offline_librispeech False en 16k
conformer_talcs True zh_en 16k'speedyspeech_csmsc',
'fastspeech2_csmsc',
'fastspeech2_ljspeech',
'fastspeech2_aishell3',
'fastspeech2_vctk',
'fastspeech2_mix',
'tacotron2_csmsc',
'tacotron2_ljspeech',
'fastspeech2_male',
'fastspeech2_canton',


















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











