






一、环境搭建准备
安装Anaconda
Anaconda3-2024.02-1-Windows-x86_64.exe
CUDA安装
下载地址:https://developer.nvidia.cn/zh-cn/cuda-toolkit
下载安装 cuda_11.7.0_516.01_windows.exe
cuDNN安装
地址为:cuDNN Archive | NVIDIA Developer
先找到与CUDA对应的版本
cudnn-windows-x86_64-8.4.1.50_cuda11.6-archive.zip
将cuDNN目录下三个文件粘贴到CUDA的目录下
二、为paddlespeech创建虚拟环境
以下命令为创建名为”paddle_speech“ 的虚拟环境
创建命令:conda create -n paddle_speech python=3.8
激活conda环境:conda activate paddle_speech
三、安装C++编译环境
(如果你系统上已经安装了 C++ 编译环境,请忽略这一步。)
对于 Windows 系统,需要安装 Visual Studio 来完成 C++ 编译环境的安装。
下载地址:https://visualstudio.microsoft.com/visual-cpp-build-tools/
主要是Visual Studio Installer 中勾选 C++桌面开发。
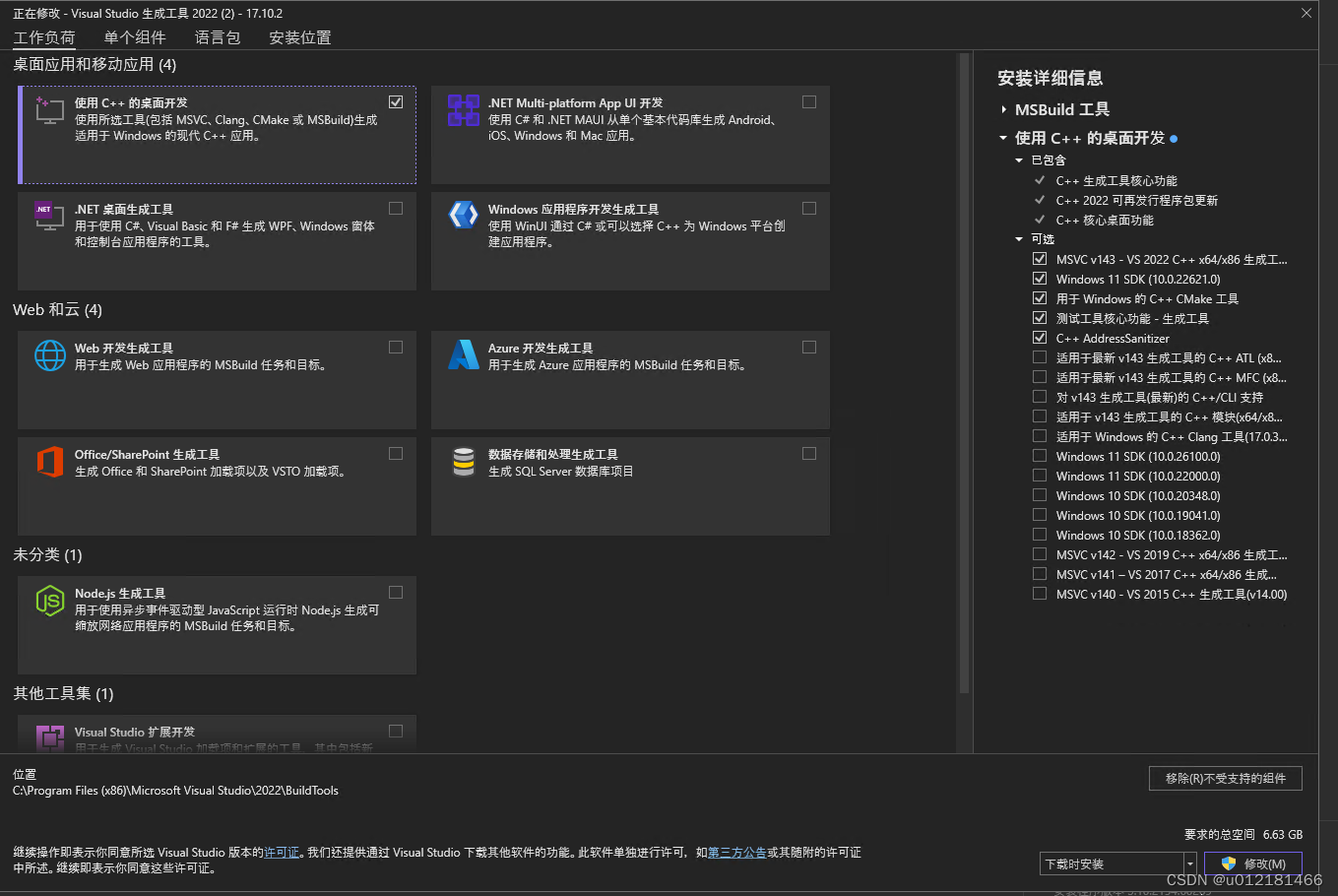
勾选完成直接点继续,开始安装
安装paddlepaddle
paddlespeech依赖于paddlepaddle,我们需要先安装paddlepaddle:
CPU版
python -m pip install paddlepaddle==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
GPU版
python -m pip install paddlepaddle-gpu==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装paddlespeech
最后安装paddlespeech
pip install paddlespeech==1.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
测试效果
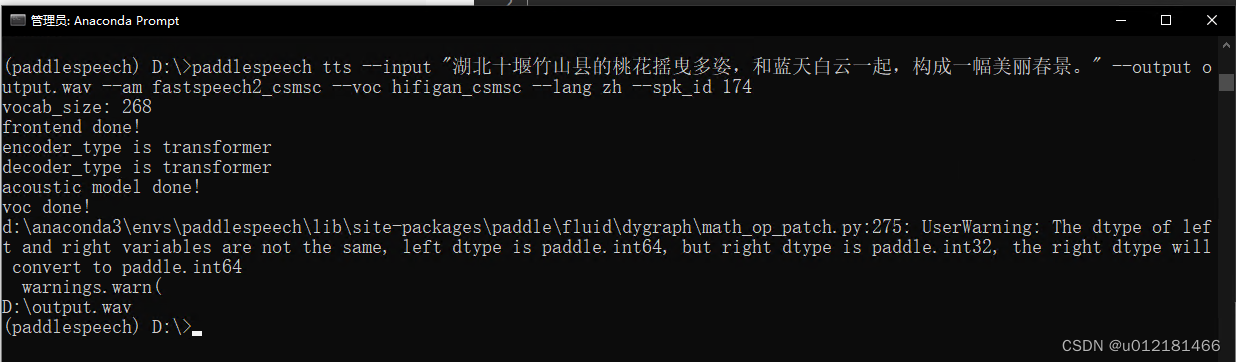
paddlespeech tts --input "湖北十堰竹山县的桃花摇曳多姿,和蓝天白云一起,构成一幅美丽春景。" --output output.wav --am fastspeech2_csmsc --voc hifigan_csmsc --lang zh --spk_id 174
最后清单列表如下:
(paddlespeech) D:\>pip list
Package Version
------------------- -----------
aiohttp 3.9.5
aiosignal 1.3.1
annotated-types 0.7.0
anyio 4.4.0
astor 0.8.1
async-timeout 4.0.3
attrs 23.2.0
audioread 3.0.1
Babel 2.15.0
bce-python-sdk 0.9.14
blinker 1.8.2
Bottleneck 1.4.0
certifi 2024.6.2
cffi 1.16.0
charset-normalizer 3.3.2
click 8.1.7
colorama 0.4.6
coloredlogs 15.0.1
colorlog 6.8.2
contourpy 1.1.1
cycler 0.12.1
Cython 3.0.10
datasets 2.20.0
decorator 5.1.1
dill 0.3.4
Distance 0.1.3
dnspython 2.6.1
editdistance 0.8.1
email_validator 2.1.2
exceptiongroup 1.2.1
fastapi 0.111.0
fastapi-cli 0.0.4
filelock 3.15.3
Flask 3.0.3
Flask-Babel 2.0.0
flatbuffers 24.3.25
fonttools 4.53.0
frozenlist 1.4.1
fsspec 2024.5.0
future 1.0.0
g2p-en 2.1.0
g2pM 0.1.2.5
h11 0.14.0
h5py 3.11.0
httpcore 1.0.5
httptools 0.6.1
httpx 0.27.0
huggingface-hub 0.23.4
humanfriendly 10.0
idna 3.7
importlib_metadata 7.1.0
importlib_resources 6.4.0
inflect 7.2.1
itsdangerous 2.2.0
jieba 0.42.1
Jinja2 3.1.4
joblib 1.4.2
jsonlines 4.0.0
kaldiio 2.18.0
kiwisolver 1.4.5
librosa 0.8.1
llvmlite 0.41.1
loguru 0.7.2
lxml 5.2.2
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.7.5
mdurl 0.1.2
mock 5.1.0
more-itertools 10.3.0
mpmath 1.3.0
multidict 6.0.5
multiprocess 0.70.12.2
nara-wpe 0.0.10
nltk 3.8.1
numba 0.58.1
numpy 1.22.0
onnxruntime 1.18.0
opt-einsum 3.3.0
orjson 3.10.5
packaging 24.1
paddle-bfloat 0.1.7
paddle2onnx 1.0.6
paddleaudio 1.0.1
paddlefsl 1.1.0
paddlenlp 2.5.2
paddlepaddle 2.4.2
paddlespeech 1.0.1
paddlespeech-feat 0.1.0
pandas 2.0.3
pathos 0.2.8
pattern_singleton 1.2.0
pillow 10.3.0
pip 24.1
platformdirs 4.2.2
pooch 1.8.2
portalocker 2.8.2
pox 0.3.4
ppft 1.7.6.8
praatio 5.0.0
prettytable 3.10.0
protobuf 3.20.0
pyarrow 16.1.0
pyarrow-hotfix 0.6
pycparser 2.22
pycryptodome 3.20.0
pydantic 2.7.4
pydantic_core 2.18.4
Pygments 2.18.0
pyparsing 3.1.2
pypinyin 0.51.0
pypinyin-dict 0.8.0
pyreadline3 3.4.1
python-dateutil 2.9.0.post0
python-dotenv 1.0.1
python-multipart 0.0.9
pytz 2024.1
pywin32 306
pyworld 0.3.4
PyYAML 6.0.1
regex 2024.5.15
requests 2.32.3
resampy 0.2.2
rich 13.7.1
sacrebleu 2.4.2
scikit-learn 1.3.2
scipy 1.10.1
sentencepiece 0.1.99
seqeval 1.2.2
setuptools 69.5.1
shellingham 1.5.4
six 1.16.0
sniffio 1.3.1
soundfile 0.12.1
starlette 0.37.2
sympy 1.12.1
tabulate 0.9.0
TextGrid 1.6.1
threadpoolctl 3.5.0
timer 0.3.0
tqdm 4.66.4
typeguard 2.13.3
typer 0.12.3
typing_extensions 4.12.2
tzdata 2024.1
ujson 5.10.0
urllib3 2.2.2
uvicorn 0.30.1
visualdl 2.4.2
watchfiles 0.22.0
wcwidth 0.2.13
weAI编程brtcvad 2.0.10
websockets 12.0
Werkzeug 3.0.3
wheel 0.43.0
win32-setctime 1.1.0
xxhash 3.4.1
yacs 0.1.8
yarl 1.9.4
zhon 2.0.2
zipp 3.19.2















 4022
4022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









