







在Recsys中看到一个关于如何解决数据集偏斜的问题,遂想到以前也考虑过这个问题,所以就总结了一些以前看的资料。
问题定义
先来说说样本的偏斜问题,也叫数据集偏斜(unbalanced),它指的是参与分类的两个类别(也可以指多个类别)样本数量差异很大。比如说正类有10,000个样本,而负类只给了100个,这会引起的问题显而易见,可以看看下面的图:

方形的点是负类。H,H1,H2是根据给的样本算出来的分类面,由于负类的样本很少很少,所以有一些本来是负类的样本点没有提供,比如图中两个灰色的方形点,如果这两个点有提供的话,那算出来的分类面应该是H’,H2’和H1,他们显然和之前的结果有出入,实际上负类给的样本点越多,就越容易出现在灰色点附近的点,我们算出的结果也就越接近于真实的分类面。但现在由于偏斜的现象存在,使得数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。
解决方法
这个问题可以有多种方法去解决:
1. 对训练数据undersampling,即对多数类数据进行抽样,或者将少数类翻倍,使得两类数量相同,这种方法在效果上也还说得过去。但是这种方法会有一些问题:1) 重采样改变了样本的分布,对于某些依赖于样本概率分布的算法来说这个方法行不通。2) 对多数类采样会使信息减少,而对少数类翻倍并不会使得信息增多。
2. 使用Cost-sensitive learning方法,该方法是想试试看能否通过训练时候这种惩罚把预测“推”向另外一面,下面要讲的就是这种方法。
经典SVM
经典的SVM是一个硬间隔分类,其对应的优化问题:
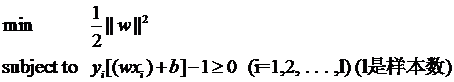
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2580
2580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









