







算法4笔记:堆,堆排序,优先队列
脑哦,最近刷LeetCode发现算法里堆排序和优先队列的知识有点小忘了,回去翻翻算法4复习总结了一下。
优先队列,堆,堆排序
考虑一个在众多数据中拿到最大的问题,引出优先队列,再引出其底层核心:堆
堆的概念和表示
数据结构中的二叉堆(或称有序堆,以下简称堆)能很好的实现优先队列的基本操作。堆是一种特殊的完全二叉树,在堆中,每个非叶节点上的权值都大于(或小于)所有其子节点的权值。或者说按照一定的优先级方式,每个非叶节点的优先级都比其所有子节点优先级高。
表示完全二叉树只需要使用数组而不需要指针。对于一个完全二叉树,让其根节点位于数组Heap初始位置
i
=
1
i = 1
i=1处,则对任意节点
H
e
a
p
[
i
]
Heap[i]
Heap[i]有:
父节点位置:
H
e
a
p
[
i
/
2
]
左子节点位置:
H
e
a
p
[
2
i
]
右子节点位置:
H
e
a
p
[
2
i
+
1
]
父节点位置:Heap[i/2]\\ 左子节点位置:Heap[2i]\\ 右子节点位置:Heap[2i+1]\\
父节点位置:Heap[i/2]左子节点位置:Heap[2i]右子节点位置:Heap[2i+1]
若让根节点位于Heap数组i = 0处,则对任意节点Heap[i]有 :
父节点位置:
H
e
a
p
[
(
i
−
1
)
/
2
]
左子节点位置:
H
e
a
p
[
2
i
+
1
]
右子节点位置:
H
e
a
p
[
2
i
+
2
]
父节点位置:Heap[(i-1)/2]\\ 左子节点位置:Heap[2i+1]\\ 右子节点位置:Heap[2i+2]\\
父节点位置:Heap[(i−1)/2]左子节点位置:Heap[2i+1]右子节点位置:Heap[2i+2]
所以,我们可以用数组模拟完全二叉树实现堆。
在使用堆实现优先队列时,在堆中查找任意节点的父节点/子节点是很频繁的操作,让根节点位于i=1处可以减少每次查询节点时的减法加法操作。另外,将a[0]的值用作哨兵(作为a[l]的父结点)在某些堆的应用中很有用。
堆的操作会首先进行一些简单的改动,打破堆的状态,然后再遍历堆并按照要求将堆的状态恢复。我们称这个过程叫做堆的有序化。
现在需要在保证堆结构的情况下,依次实现以下操作:
- 向堆中加入新节点。
- 删除堆的根节点。
- 通过给定元素构造堆。
以下以大根堆为例说明,即在改堆中,优先级定义为节点值的大小。
向堆中加入新节点
我们在堆的末尾(数组末尾)插入新节点,再通过**循环上浮操作swim()**使堆有序化。
新节点不断与其父节点进行优先级比较,如果优先级更高则与其父节点交换位置,直到优先级不大于父节点或者已经成为了根节点时停下,此时即完成了堆有序化。
删除堆的根节点
从堆顶端删去优先值最大的节点,并将堆的最后一个节点放到顶端,通过对该节点**循环下沉操作sink()**使堆有序化。
使该节点不断与其两个子节点的优先级进行比较,如果改节点的优先级没有比两个子节点都高,则将该节点与其两个子节点中优先级较高者进行互换,直到其优先级大于他的两个子节点或者成为了叶子节点时停下,此时即完成了堆有序化。
在实现时可以直接让节点与其子节点中较大者进行比较。
如果堆中某个节点的优先级发生了变化(往往会影响了堆的有序化状态),那么,若节点优先级是被放大的,此时同样用上浮操作来检验堆的有序化是否被破坏,如果被破坏了则不断进行循环上浮操作使堆有序化;若节点的优先值是被缩小的,此时用对应的下沉操作来检验和维持堆的有序化。
堆的构造
swim()方法构造:一个容易想到的方法是反复调用swim上浮操作进行构造堆,相当于不断地往堆中添加新节点。这种构造方法花费
O
(
l
o
g
N
)
O(logN)
O(logN)的时间。
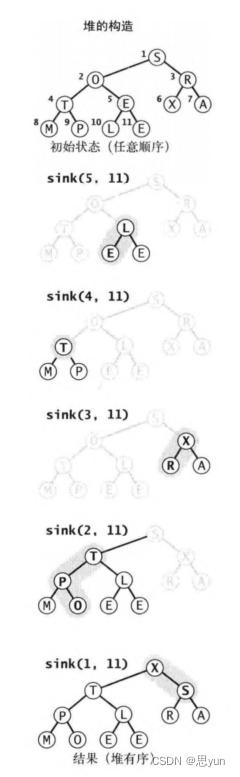
sink()方法构造:一个更聪明更高效的办法是从右至左用sink()操作构造子堆,然后逐一将这些子堆不断合并成一个堆。如果一个结点的两个子结点都已经是堆了,那么在该结点上调用sink()可以将它们变成一个堆。这个过程会递归地建立起堆的秩序。开始时我们只需要从数组中间开始,因为我们可以跳过大小为1的子堆(即跳过底层的叶子节点),不断逆向向数组位置1处遍历,之到抵达位置1即抵达根节点位置。
sink()方法构造堆只需少于2N次比较以及少于N次交换,复杂度为
O
(
N
)
O(N)
O(N).
如下为图示,sink()函数传入两个参数,操作节点标号,总节点个数。
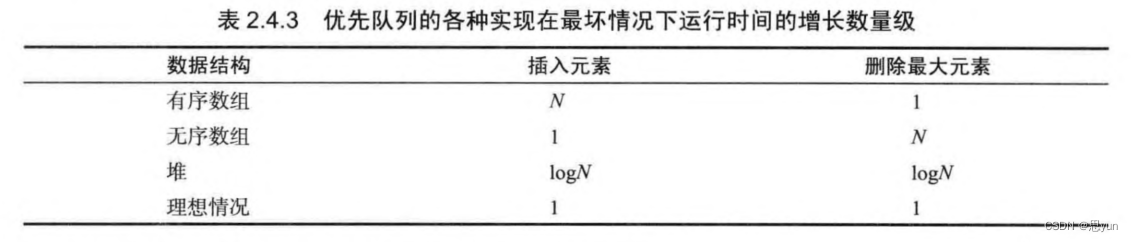
由于一棵大小为N的完全二叉树的高度为lgN。所以关于插入元素和删除元素的复杂度如下:
堆排序的主要工作都是在第二阶段完成的。这里我们将堆中的最大元素删除,然后放入堆缩小后数组中空出的位置。这个过程和选择排序有些类似(按照降序而非升序取出所有元素),但所需的比较要少得多,因为堆提供了一种从未排序部分找到最大元素的有效方法。
利用堆实现优先队列和堆排序
package queue;
/**
优先队列内维护着堆,不断维持堆的有序结构,在需要时弹出堆顶元素以获得优先级最高的元素
1. 向堆添加新节点
2. 删除堆的根节点
3. 根据所给元素构建堆
*/
import org.junit.jupiter.api.Test;
import java.util.Arrays;
import java.util.NoSuchElementException;
import java.util.stream.Stream;
/* 这里是一个简单的只考虑int[]数组的优先队列,内维护一个大根堆 */
public class PriorityQueueMaxHeapInt {
/* 优先队列,维护一个大根堆 */
private final int[] heap; // int[]实现的堆, heap[0]不用
private int heapSize; // 当前堆的大小,也用于指示堆最后一个元素的位置。
public PriorityQueueMaxHeapInt(int capacity) {
this.heapSize = capacity + 1;
this.heap = new int[capacity + 1];
}
public PriorityQueueMaxHeapInt(int capacity, int[] values) {
heap = Arrays.copyOfRange(values, 1, capacity + 1); // 复制数组,如果原数组存在则会被重构。
/* 构建堆 */
for (int i = values.length / 2 + 1; i > 0; i--) {
sink(i);
}
}
/** 工具函数,交换heap数组中i,j下标的元素 */
private void swap(int i, int j) {
int t = heap[i];
heap[i] = heap[j];
heap[j] = t;
}
/** 循环上浮操作 */
private void swim(int i) {
while (i > 1 && heap[i] > heap[i / 2]) {
swap(i, i / 2);
i = i / 2;
}
}
/** 循环下沉操作 */
private void sink(int i) {
while (2 * i <= heapSize) { // 一定是2*i 而不是2*i+1
int max;
if (2 * i + 1 < heapSize) {
// 有两个字节点,则找他们中大的那个
max = heap[i * 2] > heap[i * 2 + 1] ? i * 2 : i * 2 + 1;
} else max = i * 2;
if (heap[i] < heap[max]) {
swap(i, max);
i = max;
} else break;
}
}
/** 插入元素,若成功插入返回true */
public boolean offer(int e) {
if (heapSize + 1 < heap.length) heap[heapSize + 1] = e; // 在容量范围内
else return false;
heapSize++;
swim(heapSize);
return true;
}
/** 弹出堆顶元素 */
public int poll() {
int ret;
if (heapSize > 0) {
ret = heap[1];
swap(heapSize, 1); // 在容量范围内, 交换第一个元素和最后一个
heapSize--;
} else {
throw new NoSuchElementException("列表为空");
}
sink(1);
return ret;
}
/** 获取堆顶元素 */
public int peek() {
if (heapSize > 0) {
return heap[1];
} else {
throw new NoSuchElementException("列表为空");
}
}
/** 提供一个静态的方法,实现堆排序 */
public static void heapSort(int[] arr) {
if (arr == null || arr.length == 0) {
return;
}
for (int i = arr.length / 2 + 1; i >= 0; i--) {
sink(i, arr.length, arr);
}
int end = arr.length;
for (int i = arr.length - 1; i > 0; i--) {
int t = arr[0];
arr[0] = arr[i];
arr[i] = t;
sink(0, i, arr);
}
}
/** 用于堆排序的下沉函数 */
private static void sink(int i, int end, int[] arr) {
while (2 * i + 1 < end) { // 这里一定是2*i+1(左子节点)因为要考虑index小的那个节点
int max;
if (2 * i + 2 < end) {
max = arr[i * 2 + 1] > arr[i * 2 + 2] ? i * 2 + 1 : i * 2 + 2; // 设计这种下标读取的,必须先检查再读取
} else max = i * 2 + 1;
if (arr[i] < arr[max]) {
int t = arr[i];
arr[i] = arr[max];
arr[max] = t;
i = max;
} else break;
}
}
}
class PriorityQueueMaxHeapIntTest {
@Test
public void test() {
/* 生成随机数组,测试堆排序 */
int[] arr = Stream.generate(() -> (int) (Math.random() * 100)).distinct().limit(20).mapToInt(x -> x).toArray();
System.out.println(Arrays.toString(arr));
PriorityQueueMaxHeapInt.heapSort(arr);
System.out.println(Arrays.toString(arr));
}
}
补充:堆排序的优劣
堆排序在排序复杂性的研究中有着重要的地位,因为它是我们所知的唯一能够同时最优地利用空间和时间的方法——在最坏的情况下它也能保证使用
2
N
l
o
g
N
2NlogN
2NlogN 以内次比较和恒定的额外空间。
当空间十分紧张的时候(例如在嵌入式系统或低成本的移动设备中)它很流行,因为它只用几行就能实现(甚至机器码也是)较好的性能。
但现代系统的许多应用很少使用它,因为它无法利用缓存。数组元素很少和相邻的其他元素进行比较,因此缓存未命中的次数要远远高于大多数比较都在相邻元素间进行的算法,如快速排序、归并排序,甚至是希尔排序。















 3110
3110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









