









1.Redis 为什么是单线程? 为什么单线程还能这么快?
单线程能够避免线程切换和竞态产生的消耗,而且单线程可以简化数据结构和算法的实现
至于单线程还快,是因为Redis是基于内存的数据库,内存响应速度是很快的,并且采用epoll作为I/O多路复用技术,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多时间
epoll是为了解决Linux内核处理大量文件描述符提出的方案,属于Linux下多路I/O复用接口中select/poll的增强,经常用于Linux下高并发服务型程序,特别是大量并发连接中只有少部分处于活跃下的情况,能提高CPU利用率。
epoll采用事件驱动,只需要遍历那些被内核IO事件异步唤醒之后加入到就绪队列并返回到用户空间的描述符集合
epoll提供两种触发模式,水平触发(LT)和边沿触发(ET),目前效率最高的IO操作方案是:epoll+ET+非阻塞IO模型
2.Redis 使用场景
最多的应用于缓存,其他可以用于排行榜、计数器、消息队列等
3.Redis 淘汰策略
Redis 3.0 版本支持的策略
volatile-lru:从设置过期时间的数据集(server.db[i].expires)中挑选出最近最少使用的数据淘汰。没有设置过期时间的key不会被淘汰,这样就可以在增加内存空间的同时保证需要持久化的数据不会丢失。
volatile-ttl:除了淘汰机制采用LRU,策略基本上与volatile-lru相似,从设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰,ttl值越大越优先被淘汰。
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰。当内存达到限制无法写入非过期时间的数据集时,可以通过该淘汰策略在主键空间中随机移除某个key。
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰,该策略要淘汰的key面向的是全体key集合,而非过期的key集合。
allkeys-random:从数据集(server.db[i].dict)中选择任意数据淘汰。
no-enviction:禁止驱逐数据,也就是当内存不足以容纳新入数据时,新写入操作就会报错,请求可以继续进行,线上任务也不能持续进行,采用no-enviction策略可以保证数据不被丢失,这也是系统默认的一种淘汰策略。在此我向大家推荐一个架构学习交流圈。交流学习指导伪鑫:1253431195(里面有大量的面试题及答案)里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
4.Redis 持久化机制
1.RDB持久化:
把当前进程数据生成快照保存到硬盘的过程,触发方式有手动触发和自动触发
手动触发命令:save和bgsave命令
save命令:阻塞当前Redis服务,直到RDB过程完成为止,不建议线上环境使用
bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束,阻塞只发生在fork阶段,一般时间很短
自动触发:
使用save相关配置,如"save m n"。表示m秒内数据集存在n次修改时,自动触发
如果从节点执行全量复制操作,主节点自动执行bgsave 生成RDB文件并发送给从节点
执行debug reload命令重新加载Redis时,也会自动触发save操作
默认情况下执行shutdown命令时,如果没有开始AOF持久化则自动执行bgsave
RDB文件保存在dir配置指定的目录下,文件名通过dbfilename配置指定,可以通过执行config set dir {newDir} 和 config set dbfilename {newFileName} 运行期动态执行,当下次运行时RDB文件会保存到新目录
遇到磁盘损坏或写满时,可以通过config set dir 在线修改文件路径到可用的磁盘路径,之后执行bgsave进行磁盘切换
redis默认采用LZF算法对生成的RDB文件进行压缩,压缩后文件元小于内存大小,默认开启,可以通过参数config set rdbcompression {yes|no}动态修改
RDB优点:
RDB是一个紧凑的二进制文件,代表Redis在某个时间点上的数据快照,适合备份,全量复制等场景
Redis加载RDB恢复数据远远快于AOF方式
RDB缺点:
没办法做到实时持久化/秒级持久化
RDB文件使用特定二进制保存,存在兼容问题
2.AOF持久化
以独立日志的方式记录每次写命令,写入的内容直接是文本协议格式,重启时再重新执行AOF文件中的命令达到恢复数据的目的,解决了数据持久化实时性问题
开启AOF:appendonly yes,默认不开启
AOF文件名: appendfilename 配置,默认appendonly.aof
保存路径:同RDB,通过dir配置
AOF工作流程:
所有的写入命令追加到aof_buf(缓冲区)中
AOF缓冲区根据对应的策略向硬盘做同步操作
随着AOF文件越来越大,需要定期对AOF文件进行重写,压缩,父进程执行fork创建子进程,由子进程根据内存快照执行AOF重写,父进行继续响应后面的命令,在子进程完成重写后,父进程再把新增的写入命令写入到新的AOF文件中
Redis服务重启,加载AOF文件进行数据恢复
AOF为什么直接采用文本协议格式?
文本协议具有良好的兼容性
开启AOF后,所有写入命令都包含追加操作,直接采用协议格式,避免二次处理开销
文本协议具有可读性,方便直接修改和处理
AOF 为什么把命令追加到aof_buf中
写入缓存区aof_buf中,能提高性能,并且Redis提供了多种缓存区同步硬盘策略
重写后的AOF文件为什么可以变小?
进程内已经超时的数据不再写入文件
旧的AOF文件含有无效命令,重写使用进程内数据直接生成,新的AOF文件只保留最终数据的写入命令
多条写命令可以合并为一个,为了防止溢出,以64个元素为界拆分为多条
AOF缓冲区同步策略,通过参数appendfsync控制
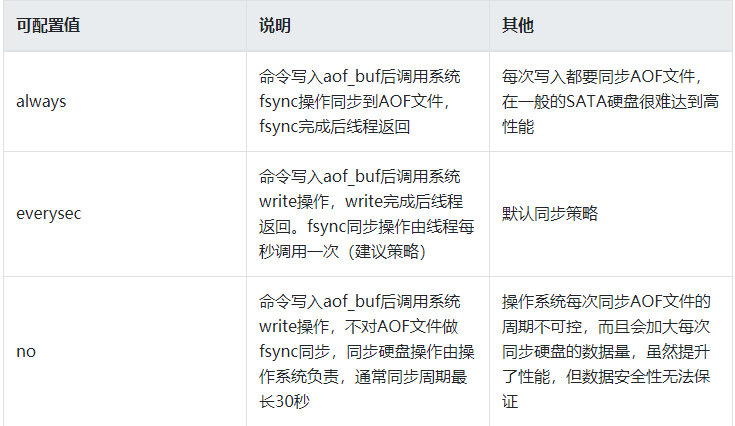
AOF手动触发:调用bgrewriteaof命令
自动触发:有两个参数
auto-aof-rewrite-min-size: 表示运行时AOF重写时文件最小体积,默认64MB
auto-aof-rewrite-percentage: 代表当前AOF文件空间(aof_current_size)和上一次重写后AOF文件空间(aof_base_size) 的比值
自动触发时机=aof_current_size > auto-aof-rewrite-min-size && (aof_current_size -aof_base_size) / aof_base_size >= auto-aof-rewrite-percentage
RDB和AOF同时开启,并且AOF文件存在,优先加载AOF文件
AOF文件错误,可以通过redis-check-aof-fix 修复















 3136
3136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









