







前言
粒度选取
论文Net2,Each Designs的Netlist的Cells,量级在20k左右。
- 而根据cell划分的粒度100,200,500,1000,2000,得到最终的Clusters是用cells的数量除以上述粒度.假设cells的数量是20k,那么所划分的clusters的数量在【10,200】。
- 根据超边的粒度500,1000,2000.得到的Clusters是由nets的数量除以上述粒度。
本实验得到的超图格式:
[超边数量] [结点数量]
超边1
超边2
超边3
。。。
而由前面工作,所生成的超图文件是以net为结点,gate为超边。因此所参考的net粒度是500,1000,2000。根据统计信息,下面是量级,并不是准确的平均值。
| design | net数量 | 超边数量 |
|---|---|---|
| b11 | 400 | 400 |
| b12 | 800 | 800 |
| b13 | 200 | 200 |
| b14 | 3000 | 3000 |
| b17 | 14000 | 14000 |
| b20 | 8000 | 8000 |
| b21 | 7500 | 7500 |
| b22 | 13000 | 13000 |
而论文数据都是:20000左右。且划分粒度在500,1000,2000,得到的划分clusters数量在10-200。
目标
- 需要将net为节点进行超图划分,然后给定net name知道划分在哪个块。
_net_P[net_name] = partID - 需要将gate为节点进行超图划分,然后给定gate name知道划分在哪个块。
_net_P[gate_name] = partID
hmetis划分
输入输出

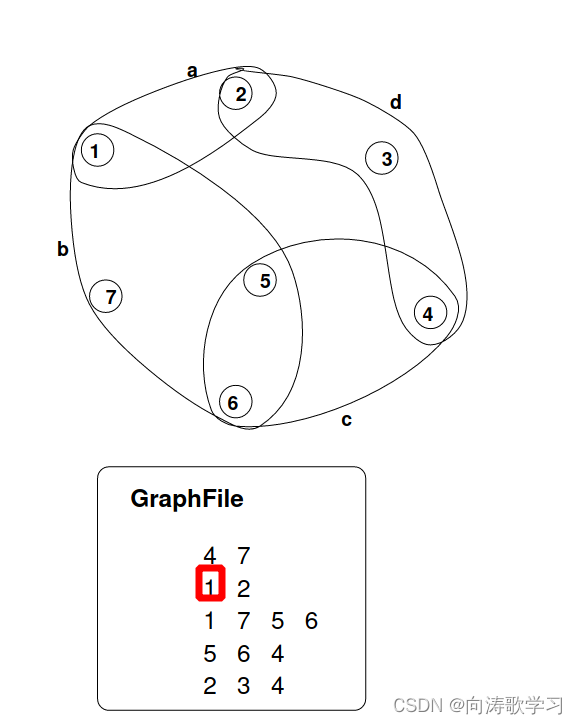
划分大小
hmetis划分是mltilevel recursive bisection,假设划分npart为2的幂次方的个数,划分后的结果的二进制就是它的划分路径!支持的可执行文件是shmetis/hmetis。
经过和老师讨论,需要将粒度划小一点。比如100,200.
下面就对粒度为100的进行划分。
划分的块数 = 节点数(nums)除以 划分一块的粒度大小(100)
import subprocess
import pandas as pd
'''
本文件对超图进行切割,按照节点数 除以 100,200
使用b11-22的mode 0的超图
shmetis
'''
res_list=[]
name = ["file","kway"]
cluster = 20
path = "partition/hypergraph_net_" + str(cluster) + "/"
for base in range(11,23):
if base ==16 or base==15 or base==18 or base==19:
continue
for clock in range(0,4):
for mode in range(0,1):
place_name = "b"+str(base)+"_"+str(clock)+"_mode_"+str(mode)
filepath = path + place_name
with open(filepath) as f:
nodeNetstr = f.readline()
f.close()
listNetNode = nodeNetstr.split(" ")
part = int(int(listNetNode[1]) / cluster)
res_list.append([place_name,part])
cmd = "partition/shmetis " + filepath + " " + str(part) + " 5"
subprocess.run(cmd,shell=True)
print(cmd)
res_csv = pd.DataFrame(columns = name,data = res_list 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2123
2123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











