







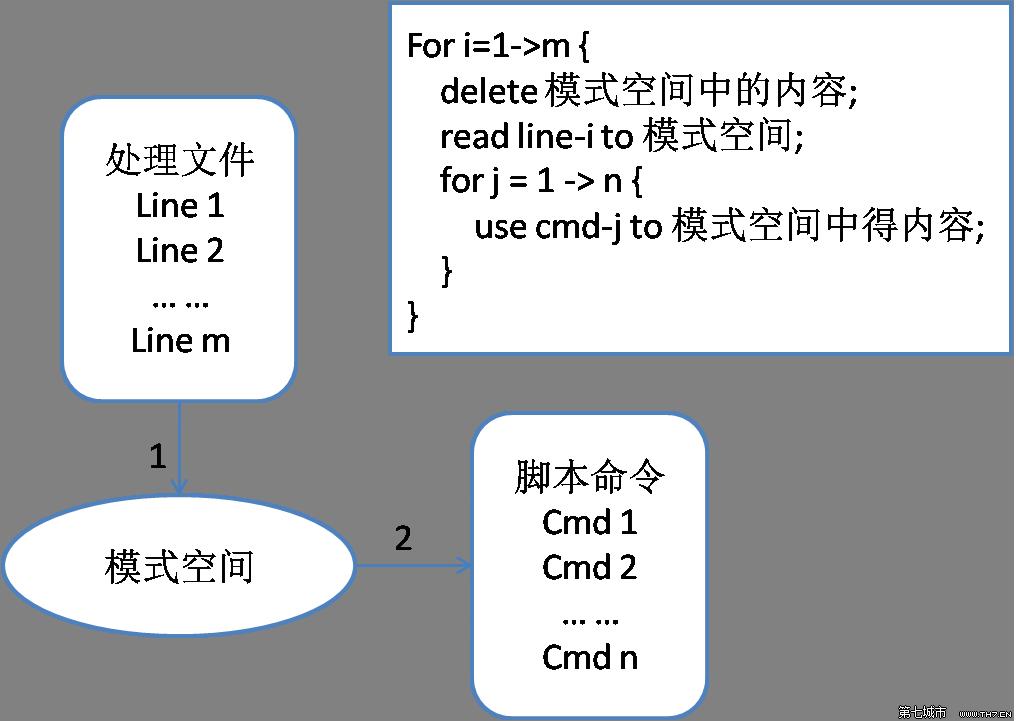
sed和awk的工作模式,对输入行的改动不会影响真正的输入文件
sed,流编辑器
指定简单的命令 sed [-e] 'instruction' file
用 '单引号' 是个好习惯,可以阻止shell解释编辑指令中的特殊字符或空格
1不需要单引号也可,2必须有单引号,有空格
1. sed ‘s/MA/Massachusetts/' file
2. sed ‘s/MA/, Massachusetts/' file
sed是隐式全局的,将命令应用于每一行。
通过向前面的替换命令提供地址Address,这样只对包含Address的替换CA为California
sed '/Address/s/CA/California/g' file
阻止输入行的自动显示 -n, 用打印命令p
sed - n -e 's/MA/Massachusetts/p' file
执行多条指令
1. 多分号分割指令
sed ‘s/MA/Massachusetts/ ; s/PA/, Pennsylvania/' file
2. 每个命令前加-e
sed -e‘s/MA/Massachusetts/ ' -e ' s/PA/, Pennsylvania/' file
3. 输入单引号后加return
执行脚本文件 sed -f scriptfile file
sed命令地址是一个描述模式、行号或者行寻址符号的正则表达式。可以指定0or1or2地址:
0个地址:命令应用于每一行
1个地址:命令应用于匹配行
2个地址(逗号隔开):应用于闭区间[第一个地址,第二个地址],可以把第一地址作为启动地址,第二个作为禁用地址,一旦启动,直到第二个匹配;没有的第二个匹配的话,删除第一个以后所有行
地址后跟!:应用于不匹配该地址的其他所有行
举例(d 删除所有行):
1d 删除第一行
$d 删除最后一行。$不同于正则表达式中的元字符,在sed表示最后一行
/^$/d 删除空行,正则表达式^$必须封闭在斜杠/ /内
50,$d 删除50至最后一行
1,/^$/d 删除第一行到第一个空行之间的所有行,此处混用了行地址和模式地址
分组命令,sed使用大括号{}将一个地址嵌套在另一个地址中,或者在相同的地址上应用多个命令
左大括号必须在行模,右大括号必须单独占一行,确保大括号后没有空格
1. 嵌套地址
/^\.TS/,/^\.TE/{
/^$/d
}
删除TS TE之间的的空行
2. 应用多个命令,
/^\.TS/,/^\.TE/{
/^$/d
s/^\.ps 10/.ps 8/
s/^\.vs 12/.vs 10/
}
不仅删除空行,而且使用替换命令s
基本sed命令
在命令后加空格是不允许的,命令的结尾必须在行的结尾处。可以用分号间隔同一行的多个命令
命令的语法格式:[address]command。
当sed不理解一个命令时,会报错command garbled(命令不清)
注释行第一个字符必须是#,语法:#[n]。如果#n则脚本不会自动产生输出,跟命令行-n等价
替换命令s
[address]s/pattern/replacement/flags
在replacement中&用正则表达式匹配的内容进行替换,举例:
s/See Section [1-9][0-9]*\.[1-9][0-9]*/(&)/
形如See Section 12.9 加上括号,替换为(See Section 12.9)
追加a插入i更改c命令每一个都要求 后面跟一个反斜杠\用于转义第一个行尾,text必须从下一行开始
输入多行,每行必须用反斜杠\结束
[line-address]a\
text
[line-address]i\
text
[line-address]c\
text
列表命令l ( L )用于显示模式空间的内容,将非打印的字符显示为两个数字的ASCII代码
sed -e 'l' file
转换命令y,按位置将abc中转为xyz中的对应字符
[address]y/abc/xyz/
小写改为大写:y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/
打印行号=,地址后跟等号=
[line-address]=
退出命令q,是sed停止读取新的输入行
[line-address]q
sed '100q' file 打印前100行
awk,程序设计语言
命令行awk 'instructions' file
脚本文件awk -f script file
$0 代表整个输入行, $1 、$2.....代表输入行的各个字段
使用-F将字段分隔符改为逗号(默认是空格或制表符),打印包含'MA'的输入行的第一个字段
awk -F, '/MA/{print $1}' file
awk将变量初始化为空字符串,使用某个变量之前不需要先赋值
$是引用字段操作符: w=$1
空格是字符串连接操作符: z="hello" "world",相当于把“helloworld”赋给了z
系统变量
1. 变量的默认值可以改变,例如默认的字段FS和记录分隔符RS。
2. 变量自动更新,如当前记录的编号NF,当前输入文件的名字FILENAME
this is a char (NR:1)
and two lines (NR:2)
以上是两个记录(换行分割),第一个记录有4个字段(空格分隔)
NR是当前输入记录的编号,FNR与当前文件相关的当前记录的编号
NF是当前记录的字段个数, 打印当前记录最后一个字段{print $NF}
FS/OFS 定义输入/输出字段分隔符,默认是空格
RS/ORS定义输入/输出记录分隔符,默认是换行
关系操作符和布尔操作符
NF==6 {print $1, $6} 当前记录有6个字段的时候会打印
/^$/ { print " this is a black line"} 当空行时候打印
$5 ~ /MA/ {print $1} #当第五个字段与正则表达式MA匹配时候,打印
$5 !~ state {print $1} #当第五个字段与变量state不匹配时候,打印
可以加括号表示优先级,可以!取反,举例:
!( (NR>1 && NF <=2) || ($1 ~/\t/) )
例子:
环境
$ls -l
-rw-rw-rw- 1 dale project 6041 jan 1 12:30 com.tmp
......
drwxrwxrwx 3 dale project 960 FEB 1 15:47 sed
......
total 555
#ls -lR递归列出子目录
ls -lR $* | awk '
#shell 使用 $* 变量来扩展通过命令行传递的所有变量
#输出列的标题,仅执行一次
BEGIN { print "BYTES", "\t", "FILE" }
#测试是否9个字段,文件以“-”开始
NF == 9 && /^-/ {
sum += $5 #累计文件大小
++filenum #系统文件个数
print $5, "\t", $9 #打印文件名和大小
}
#测试是否9个字段,目录以“d”开始
NF == 9 &&/^d/ {
print "<dir>", "\t", $9 #打印<dir>和名字
}
#测试ls -lR行 ./dir
#$1 匹配 (以句点开头,其后跟任意数量的字符并以冒号结尾: ./old: )
$1 ~ /^\..*:$/ {
print "\t" $0 #打印用制表符处理的行
#所有工作已完成
END {
#打印所有文件总的大小和文件数目,仅进行一次
print "Total: ", sum, "bytes(" filenum "files)"
}'
#ls -lR递归列出子目录
ls -lR $* | awk '
#shell 使用 $* 变量来扩展通过命令行传递的所有变量
#输出列的标题,仅执行一次
BEGIN { print "BYTES", "\t", "FILE" }
#测试是否9个字段,文件以“-”开始
NF == 9 && /^-/ {
sum += $5 #累计文件大小
++filenum #系统文件个数
print $5, "\t", $9 #打印文件名和大小
}
#测试是否9个字段,目录以“d”开始
NF == 9 &&/^d/ {
print "<dir>", "\t", $9 #打印<dir>和名字
}
#测试ls -lR行 ./dir
#$1 匹配 (以句点开头,其后跟任意数量的字符并以冒号结尾: ./old: )
$1 ~ /^\..*:$/ {
print "\t" $0 #打印用制表符处理的行
#所有工作已完成
END {
#打印所有文件总的大小和文件数目,仅进行一次
print "Total: ", sum, "bytes(" filenum "files)"
}'
格式化打印 printf,借用了C语言
向脚本传递参数
awk 'script' var=value inputfile
awk -f scriptfile high=100 low=60 datafile
或者 shell脚本名为awket
则 awket 100 60
awk -f scriptfile "high=$1" "low=$2" datafile
awk对于大括号和语句的位置没有特殊的要求,与sed不同
条件语句
if (expression){
statement1;statement2
statement3
}
}
else
statement4
条件语句
expr? action1:action2
while do for都与c类似
数组
awk中不需要指定数组的大小,所有的数组都是关联数组(map)
array[NR] = data #系统变量NR作为数组的下标,对于每个记录它是递增的
#访问数组的所有元素
for (val in array)
print arrar[val]
使用#!/bin/awk -f #awk路径后-f选项
{print $0} #不需要使用引号‘’















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









