






对Mall Customers 的200*4数据集提供的信息,如下图,使用不同的聚类算法对顾客进行聚类分析。

首先,需要将数据集进行预处理,包括数据清洗、数据缩放、特征选择等。对于Mall Customers数据集,我们可以使用Python的pandas库读取数据,并查看数据的基本信息。由肉眼观察知道需要进行数值化处理,进行数据缩放。
在使用DBSCAN算法进行聚类前,需要确定算法的两个参数:半径r和最小样本数min_samples。半径r决定了一个点的邻域范围,而最小样本数min_samples是指在该邻域范围内必须存在的最小样本数目。
在确定这两个参数时,可以通过可视化来判断最优参数。
1.把csv转换为dataframe格式
#把csv转换为dataframe格式
import pandas as pd
csv_file = "Mall_Customers.csv"
csv_data = pd.read_csv(csv_file, low_memory = False)#防止弹出警告
csv_df = pd.DataFrame(csv_data)
csv_df
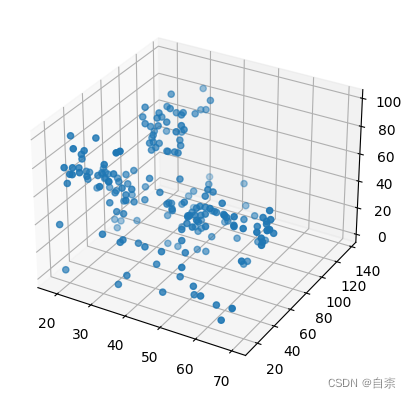
2.通过3D方式展示样本分布
#通过3D方式展示样本分布
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 读取csv文件并转换为dataframe格式
df = pd.read_csv('Mall_Customers.csv')
# 假设数据集包含x、y、z三个特征
X = df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']].values
# 通过3D方式展示样本分布
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2])
plt.show()
3.使用from sklearn.cluster import DBSCAN实现
#使用from sklearn.cluster import DBSCAN实现
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
# 读取csv文件
data = pd.read_csv('Mall_Customers.csv')
# 获取需要聚类的特征列
X = data[['Age', 'Annual Income (k$)']]
# 进行第一次聚类Age与 Annual Income (k$)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 聚类
dbscan = DBSCAN(eps=0.5, min_samples=5)
clusters = dbscan.fit_predict(X_scaled)
# 可视化结果
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=clusters)
plt.xlabel('Age')
plt.ylabel('Annual Income (k$)')
plt.show()
# 进行第二次聚类Age与Spending Score (1-100)
X = data[['Age', 'Spending Score (1-100)']]
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 聚类
dbscan = DBSCAN(eps=0.5, min_samples=5)
clusters = dbscan.fit_predict(X_scaled)
# 可视化结果
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=clusters)
plt.xlabel('Age')
plt.ylabel('Spending Score (1-100)')
plt.show()
# 进行第三次聚类Annual Income (k$)与 Spending Score (1-100)
X = data[['Annual Income (k$)', 'Spending Score (1-100)']]
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 聚类
dbscan = DBSCAN(eps=0.5, min_samples=5)
clusters = dbscan.fit_predict(X_scaled)
# 可视化结果
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=clusters)
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.show()
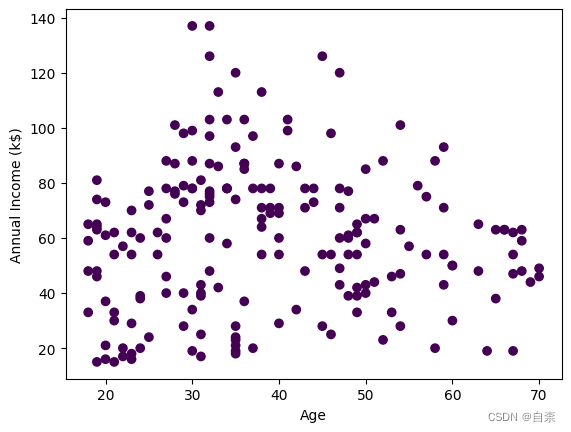
4.如果不使用sklearn等机器学习包,自定义函数实现
#不使用sklearn等机器学习包,自定义函数实现
import pandas as pd
import numpy as np
import math
# 读取csv文件
data = pd.read_csv('Mall_Customers.csv')
# 获取需要聚类的特征列
X = data[['Age', 'Annual Income (k$)']]
# 自己实现DBSCAN聚类函数
def dbscan(X, eps, min_samples):
# 标记每个样本的状态: 0-未处理, 1-已处理
labels = [0] * len(X)
# 计算样本之间的距离
dist_matrix = np.zeros((len(X), len(X)))
for i in range(len(X)):
for j in range(i, len(X)):
dist_matrix[i][j] = dist_matrix[j][i] = math.sqrt(sum((X.iloc[i] - X.iloc[j])**2))
# 遍历所有样本点
cluster_id = 0
for i in range(len(X)):
# 如果样本点已经处理过,直接跳过
if labels[i] != 0:
continue
# 获取半径eps内的所有样本点
neighbors = [j for j in range(len(X)) if dist_matrix[i][j] <= eps]
# 如果形成不了类别,则标记为噪声
if len(neighbors) < min_samples:
labels[i] = -1
# 否则(可以形成类别),将当前样本点标记为该类别,并处理其他点
else:
cluster_id += 1
labels[i] = cluster_id
for j in neighbors:
if labels[j] == -1:
labels[j] = cluster_id
if labels[j] != 0:
continue
labels[j] = cluster_id
# 继续获取该点eps半径内的样本点
new_neighbors = [k for k in range(len(X)) if dist_matrix[j][k] <= eps]
# 如果该点的eps半径内的样本点数量达到min_samples,将这些点也标记为该类别
if len(new_neighbors) >= min_samples:
neighbors.extend(new_neighbors)
return labels
# 进行第一次聚类Age与 Annual Income (k$)
labels = dbscan(X, eps=0.5, min_samples=5)
# 可视化聚类结果
import matplotlib.pyplot as plt
plt.scatter(X.iloc[:,0], X.iloc[:,1], c=labels)
plt.xlabel('Age')
plt.ylabel('Annual Income (k$)')
plt.show()
# 进行第二次聚类Age与Spending Score (1-100)
X = data[['Age', 'Spending Score (1-100)']]
labels = dbscan(X, eps=0.5, min_samples=5)
# 可视化聚类结果
import matplotlib.pyplot as plt
plt.scatter(X.iloc[:,0], X.iloc[:,1], c=labels)
plt.xlabel('Age')
plt.ylabel('Spending Score (1-100)')
plt.show()
# 进行第三次聚类Annual Income (k$)与 Spending Score (1-100)
X = data[['Annual Income (k$)', 'Spending Score (1-100)']]
labels = dbscan(X, eps=0.5, min_samples=5)
# 可视化聚类结果
import matplotlib.pyplot as plt
plt.scatter(X.iloc[:,0], X.iloc[:,1], c=labels)
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.show()
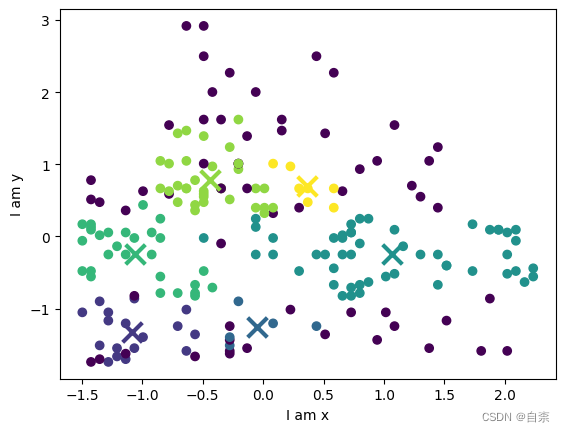
5.用可视化包或库(如,matplotlib )显示分类的结果
#用可视化包或库(如,matplotlib )显示分类的结果
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
# 读取csv文件
data = pd.read_csv('Mall_Customers.csv')
# 获取需要聚类的特征列
X = data[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']]
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 进行聚类
dbscan = DBSCAN(eps=0.5, min_samples=5)
labels = dbscan.fit_predict(X_scaled)
# 找出每个簇的中心点
cluster_centers = []
for i in range(np.max(labels)+1):
cluster_centers.append(np.mean(X_scaled[labels==i], axis=0))
# 可视化聚类结果和簇中心点
fig, ax = plt.subplots()
scatter = ax.scatter(X_scaled[:,0], X_scaled[:,1], c=labels)
for i, cluster_center in enumerate(cluster_centers):
ax.scatter(cluster_center[0], cluster_center[1], marker='x', s=200, linewidths=3, color=scatter.to_rgba(i), zorder=10)
ax.set_xlabel('I am x')
ax.set_ylabel('I am y')
plt.show()















 7886
7886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









