







在实际场景中,比如本项目的商场顾客数据集,只包含一批顾客的背景信息,但并不包含顾客的类别信息(顾客是属于什么类别的)。我们面对的许多真实数据集都是没有提供属性标签的,对于这种无标签的数据,需要通过调用机器的学习任务,完成无监督学习。聚类任务是一种常见的无监督学习。本项目,我们的目的就是利用聚类技术,对提供的商场顾客背景信息做聚类分析。
我们先对本项目提供的数据集进行加载以及可视化分析。由于本项目提供的是不带标签的数据集,因此我们主要会探索各个特征间潜在的关系,以对后续的预处理代码 预加载代码:

聚类分析所需用到的特征有一定的认识
步骤一:加载商场顾客数据集 和之前的实验一样,我们先对本项目提供的商场顾客数据集进行加载。 该数据集被包 含在 datasets 文件夹中的 Mall_Customers.csv 里:
样例代码:

运行结果:

从打印的前五个样本数据来看,每个样本都包含 5 个特征数据,但是并不包含一个目标标签值。接着,我们打印该数据表的 info 方法来看看数据表的详细信息:
样例代码:

运行结果:
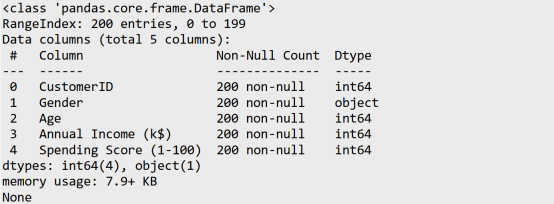
可以看出,该数据集较小,只有 200 条样本,每条样本包含 5 个特征值。其中,特征列 CustomerID 是表示顾客的 ID 编号,属于无效列,对我们后续的聚类任务没有帮助,因此我们直接忽略该列。除了 CustomerID 这一列,仅有 Gender 列是属于对象类型的,且只包含 Male 和 Female 这个值,其他列都是属于整型数据。
步骤二:基于数值列绘制统计直方图
我们首先对全体数据集进行分析,也就是包含男女性别的所有顾客数据。这里,我们分别对 Age、 Annual Income (k$)和 Spending Score (1-100)这三列数据做统计,为了直观地展示各个数值区间的样本数量,我们这里直接利用 Seaborn 的 histplot 方法绘制出统计直方图。相关的绘图方式在之前的项目中已经讲解过了,这里值得说明的是参数 kde,该参数我们设定为 True,表示在直方图中我们将高斯核密度估计曲线同时绘制出(一种概率密度函数),用于有效展示样本属于各个数据段的概率分布情况。 实现代码如下:

运行结果:
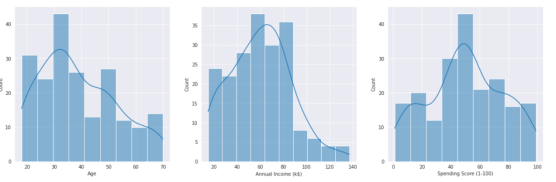
从得到的三个直方图中我们大致分析出,数据集中的年龄段在 30-35 岁之间的顾客人数最多,年收入有 5-6 万美元的顾客人数最多。消费力分数在 30-50 之间的顾客人数最多。
步骤三:绘制不同性别顾客的散点分布图
接着,我们再针对不同性别顾客,根据两两特征值我们可以绘制出三张散点图。第一张散点图我们根据顾客的年龄信息和年收入信息,绘制出的散点图能表现出不同年龄段顾客的年收入。第二张散点图我们根据顾客的年龄和消费能力分数,绘制出的散点图能表现出不同年龄段顾客的消费能力。第三张散点图我们根据顾客的年收入和消费能力分数,绘制出的散点图能表现出不同年收入顾客的消费能力。
我们利用 Seaborn 的 scatterplot 方法来绘制散点图,其中参数 hue 指定用于分组的列,即绘制出的散点图会用不同的颜色表示 hue 列不同特征值。这里,我们就是指定hue 值为 Gender,分别用不同颜色标记不同性别顾客的样本点,并以图例的形式进行说明。实现代码如下:
样例代码:

运行结果:
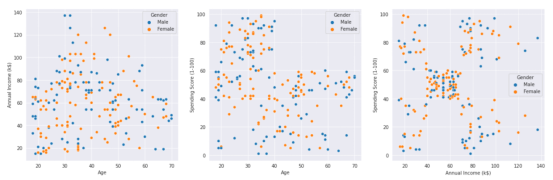
从得到的三张散点图中我们可以大致看出,无论是对哪个性别的顾客,整个图中的散点分布的比较散,很难从中总结出一定的规律。因此,我们将在下一个实验中学习机器学习中的聚类方法,通过聚类方法对顾客进行有效的聚类,从而达到对顾客分类的目标。















 1371
1371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









