







本讲内容:
a. Spark Streaming Job 架构和运行机制
b. Spark Streaming Job 容错架构和运行机制
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
上节回顾:
上节课谈到Spark Streaming是基于DStream编程。DStream是逻辑级别的,而RDD是物理级别的。DStream是随着时间的流动内部将集合封装RDD。对DStream的操作,归根结底还是对其RDD进行的操作。
如果将Spark Streaming放在坐标系中,并以Y轴表示对RDD的操作,RDD的依赖关系构成了整个job的逻辑应用,以X轴作为时间。随着时间的流逝,以固定的时间间隔(Batch Interval)产生一个个job实例,进而在集群中运行。
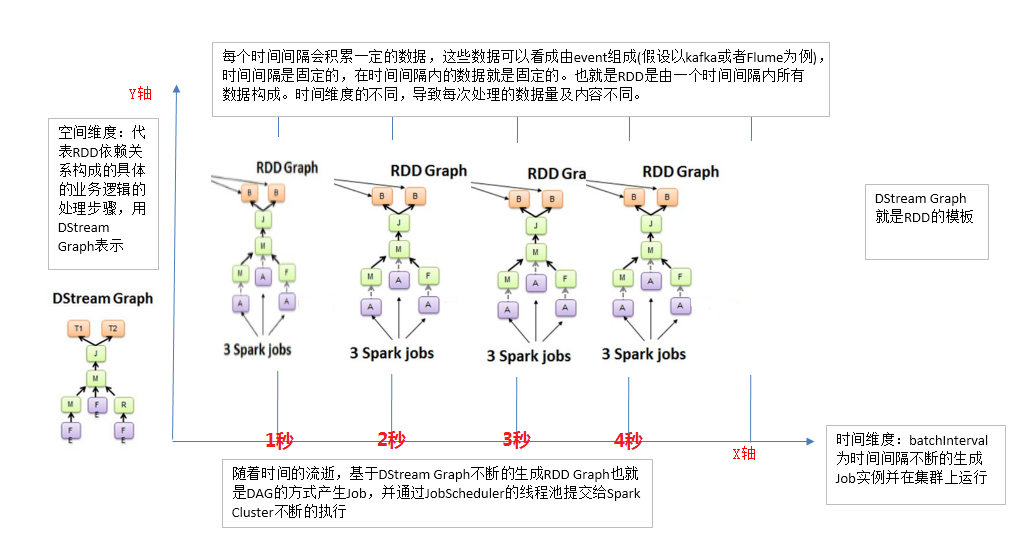
同时也为大家详细总结并揭秘 Spark Streaming五大核心特征:特征1:逻辑管理、特征2:时间管理、特征3:流式输入和输出、特征4:高容错、特征5:事务处理。最后结合Spark Streaming源码做了进一步解析。
**
开讲
**
由上一讲可以得知,以固定的时间间隔(Batch Interval)产生一个个job实例。那么在时间维度和空间维度组成的时空维度的Spark Streaming中,Job的架构和运行机制、及其容错架构和运行机制是怎样的呢?
那我们从爱因斯坦的相对时空讲起吧:
a、时间和空间是紧密联系的统一体,也称为时空连续体。
b、时空是相对的,不同的观察者看到的时间,长度,质量都可以不一样。
c、对于两个没有联系的事件,没有绝对的先后顺序。但是因果关系可以确定事件的先后,比如Job的实例产生并运行在集群中,那么Job实例的产生事件必然发生在Job运行集群中之前。
就是说Job的实例产生和单向流动的时间之间,没有必然的联系;在这里时间只是一种假象。
怎么更好的理解这句话呢?那我们就得从以下方面为大家逐步解答。
什么是Spark Streaming Job 架构和运行机制 ?
对于一般的Spark应用程序来说,是RDD的action操作触发了Job的运行。那对于SparkStreaming来说,Job是怎么样运行的呢?我们在编写SparkStreaming程序的时候,设置了BatchDuration,Job每隔BatchDuration时间会自动触发,这个功能是Spark Streaming框架提供了一个定时器,时间一到就将编写的程序提交给Spark,并以Spark job的方式运行。
通过案例透视Job架构和运行机制
案例代码如下:
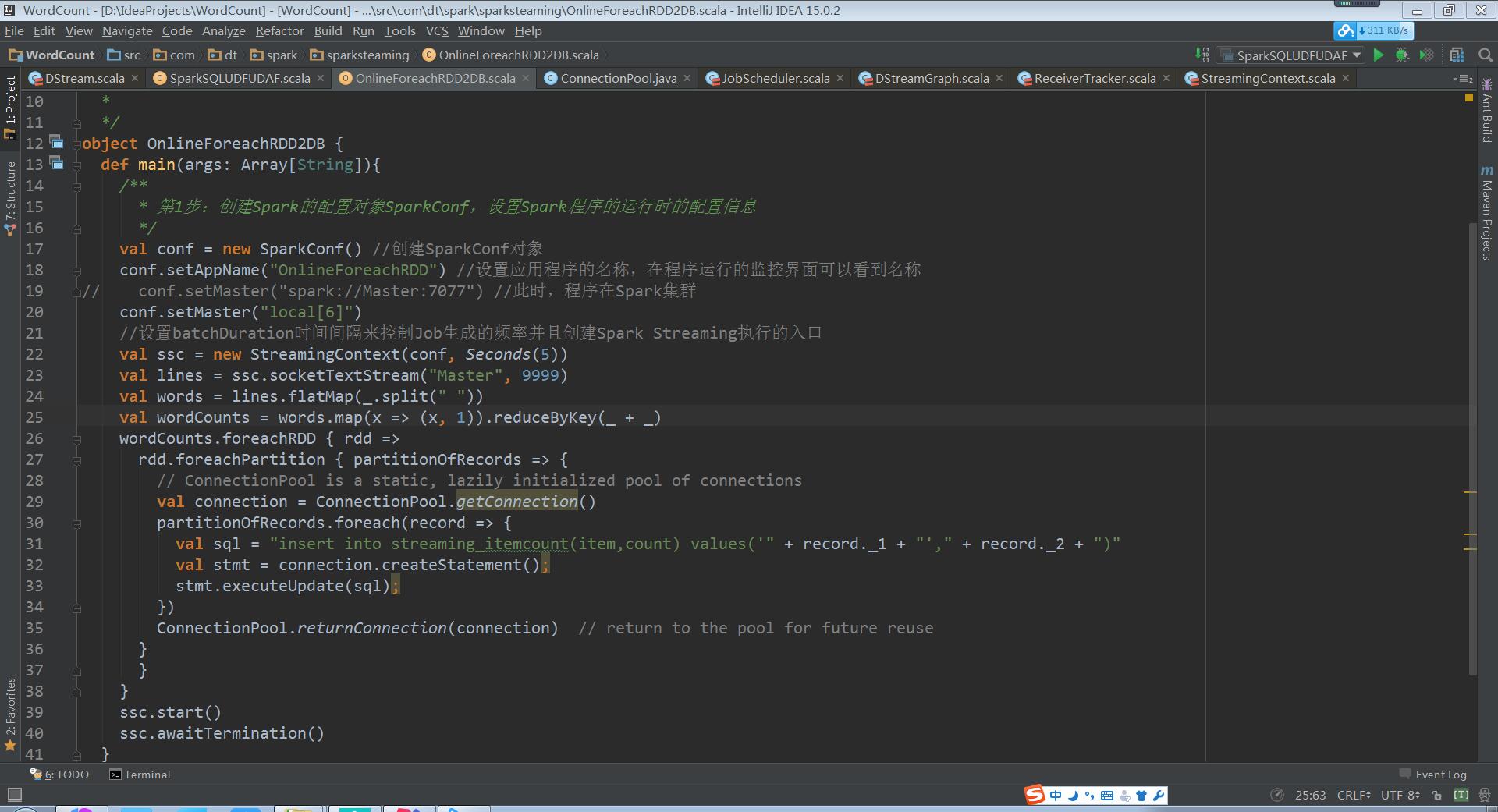
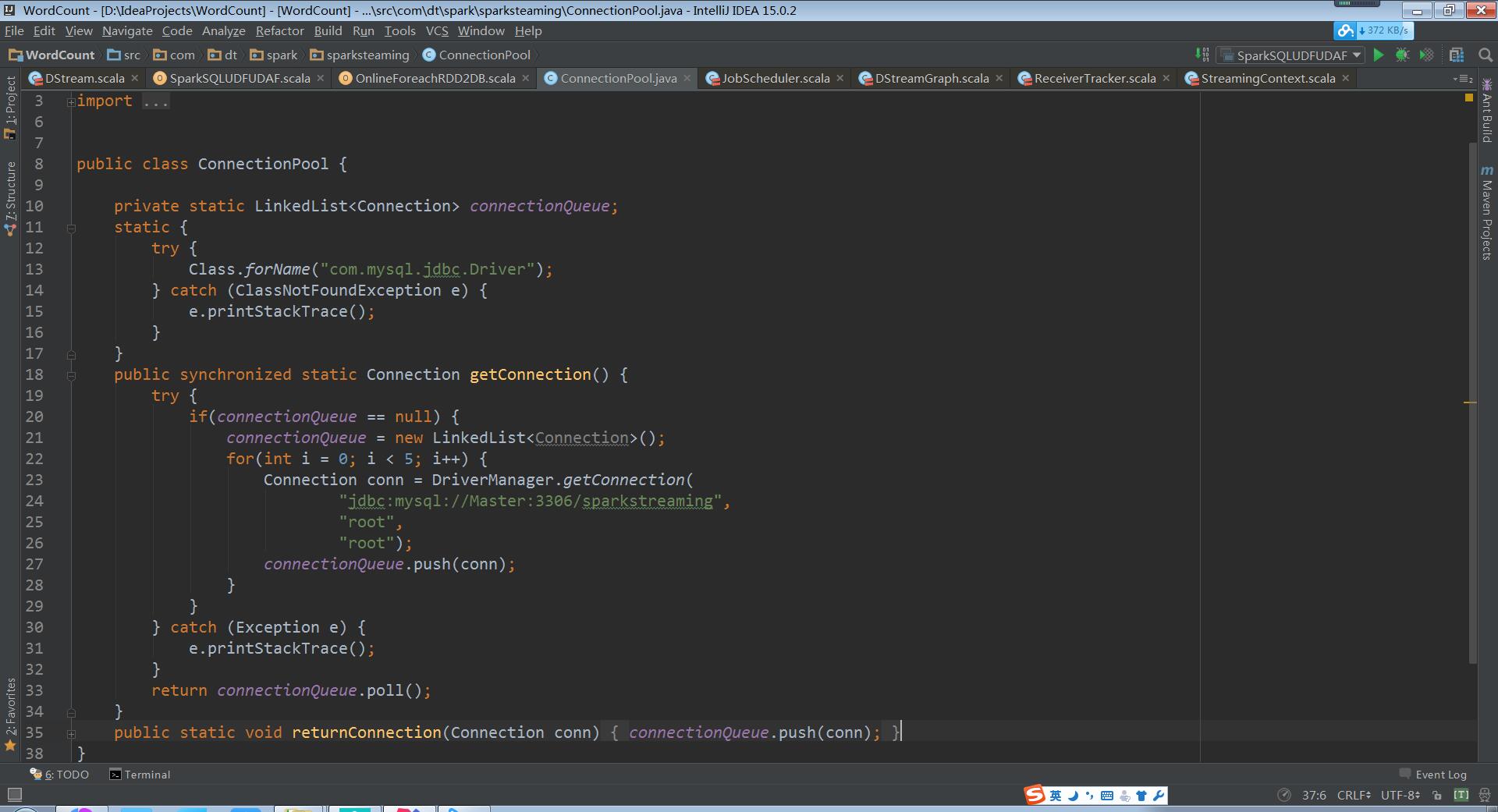
将上述代码打成JAR包,再上传到集群中运行
集群中运行结果如下
运行过程总图如下
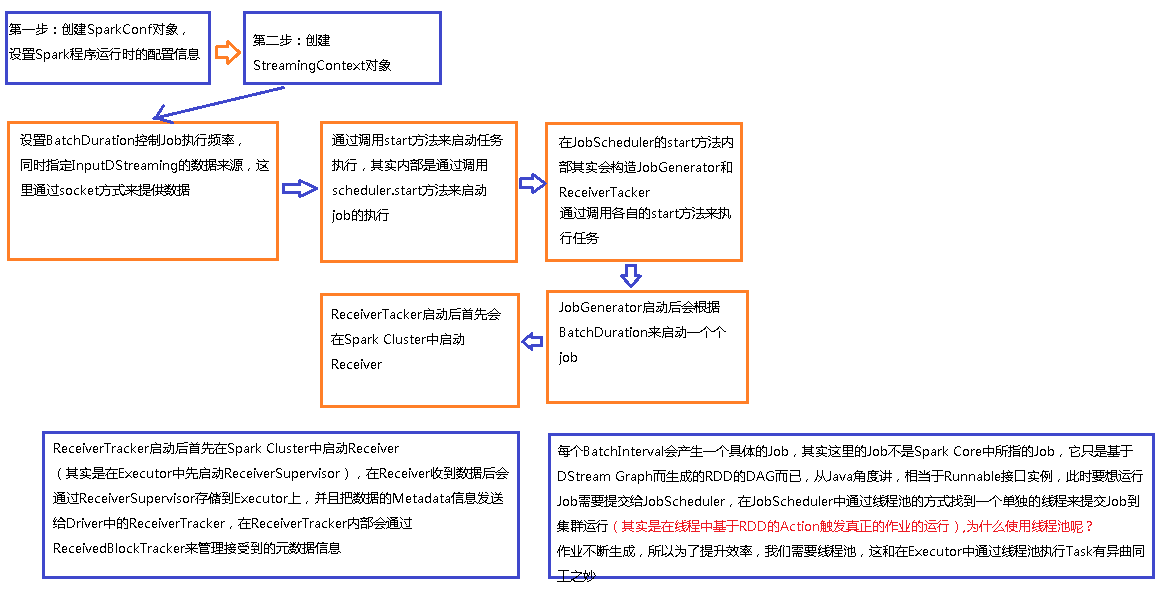
案例详情解析
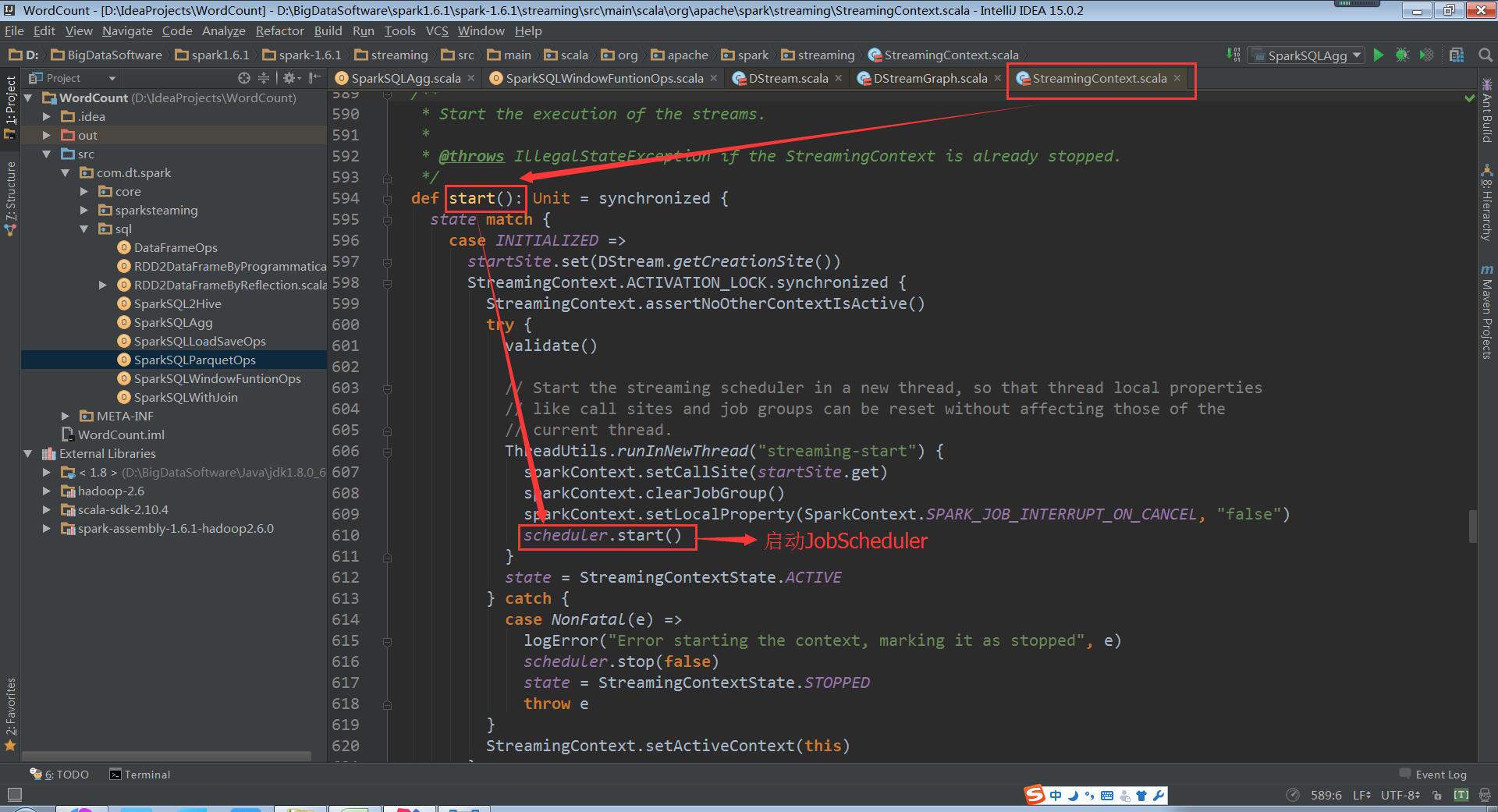
a、 首先通过StreamingContext调用start方法,其内部再启动JobScheduler的Start方法,进行消息循环;
(StreamingContext.scala,610行代码)
(JobScheduler.scala,83行代码)
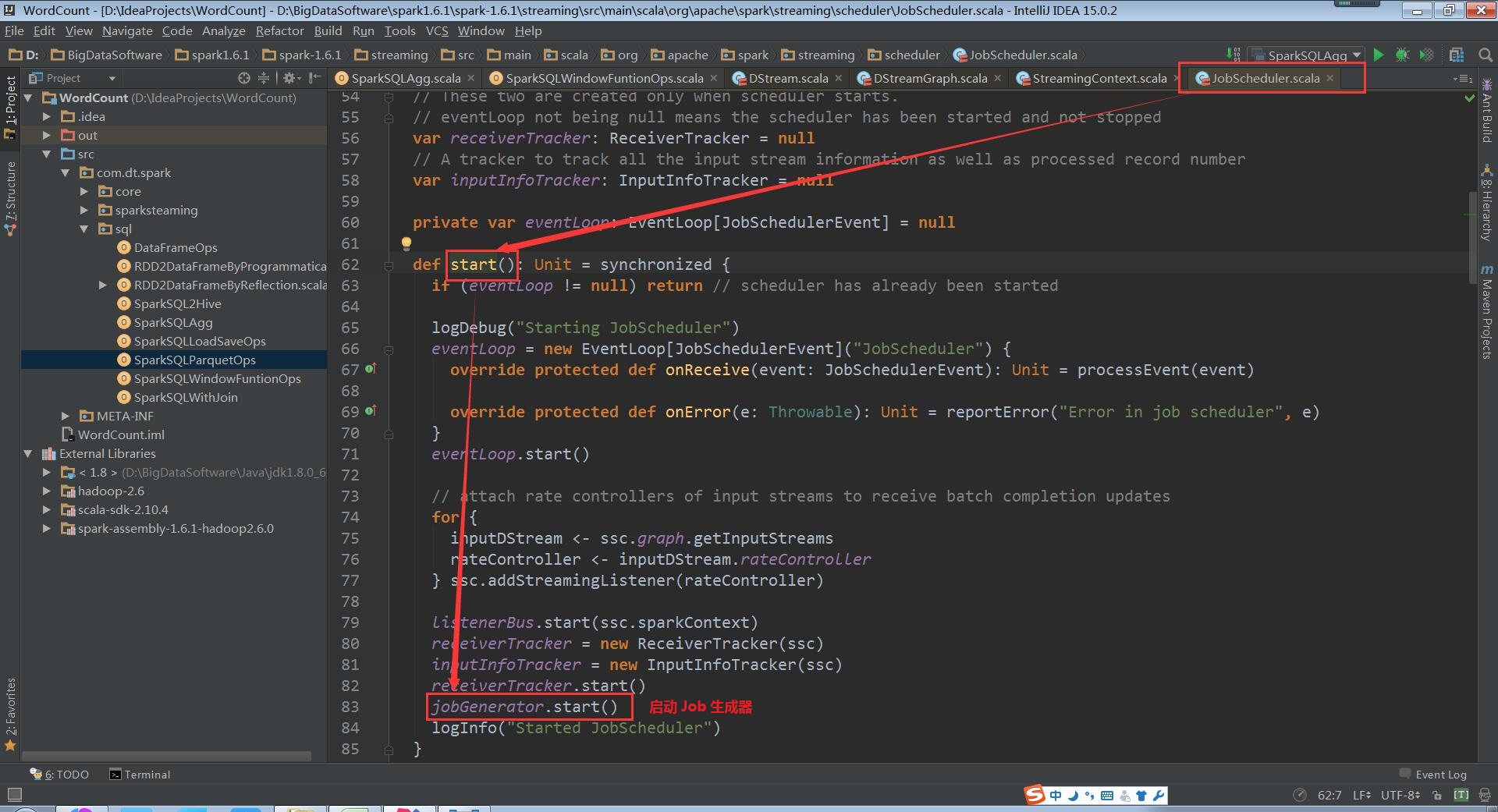
b、 在JobScheduler的start内部会构造JobGenerator和ReceiverTacker;
(JobScheduler.scala,82、83行代码)
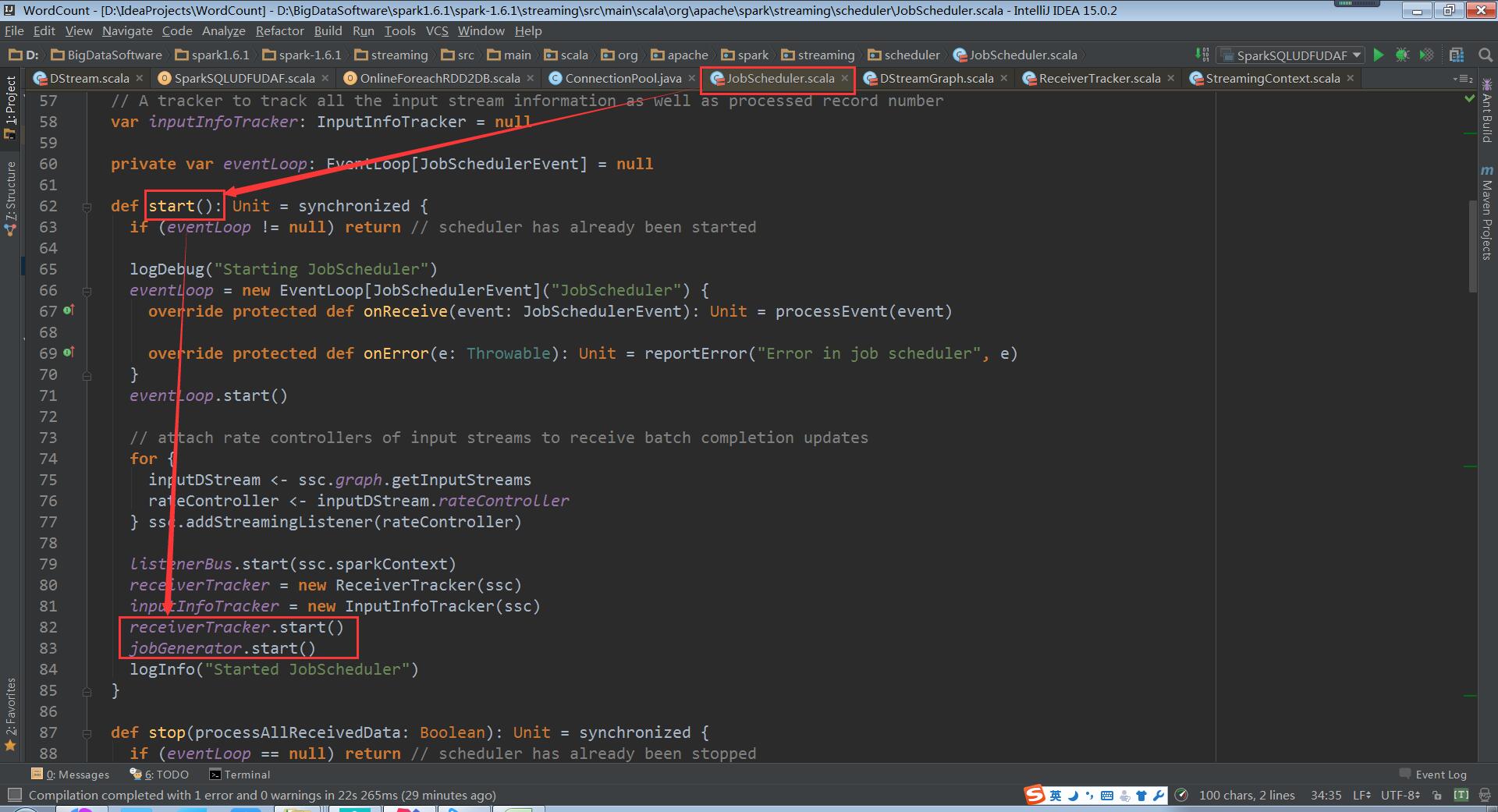
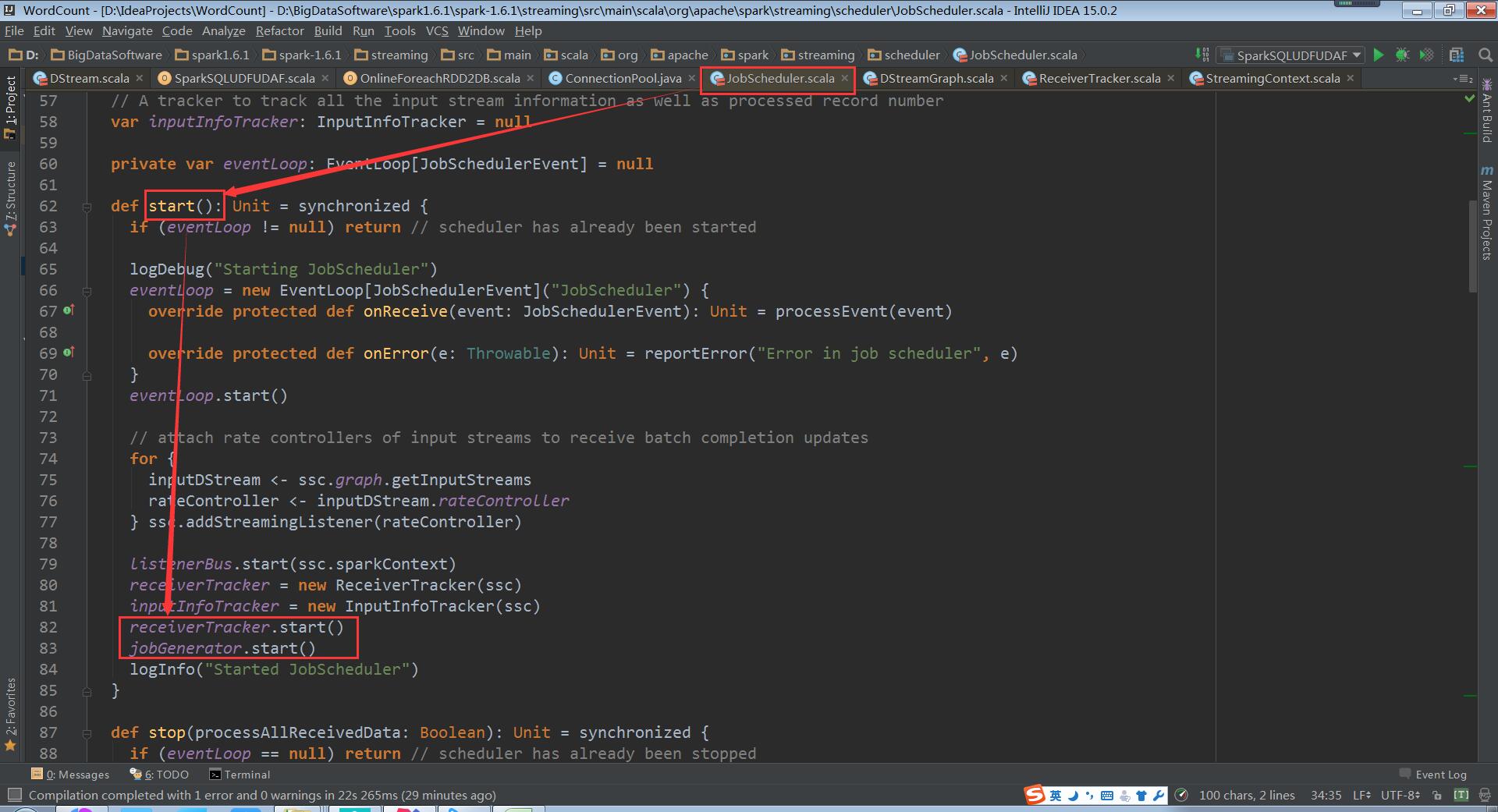
c、 然后调用JobGenerator和ReceiverTacker的start方法执行以下操作:
(JobScheduler.scala,79、98行代码)
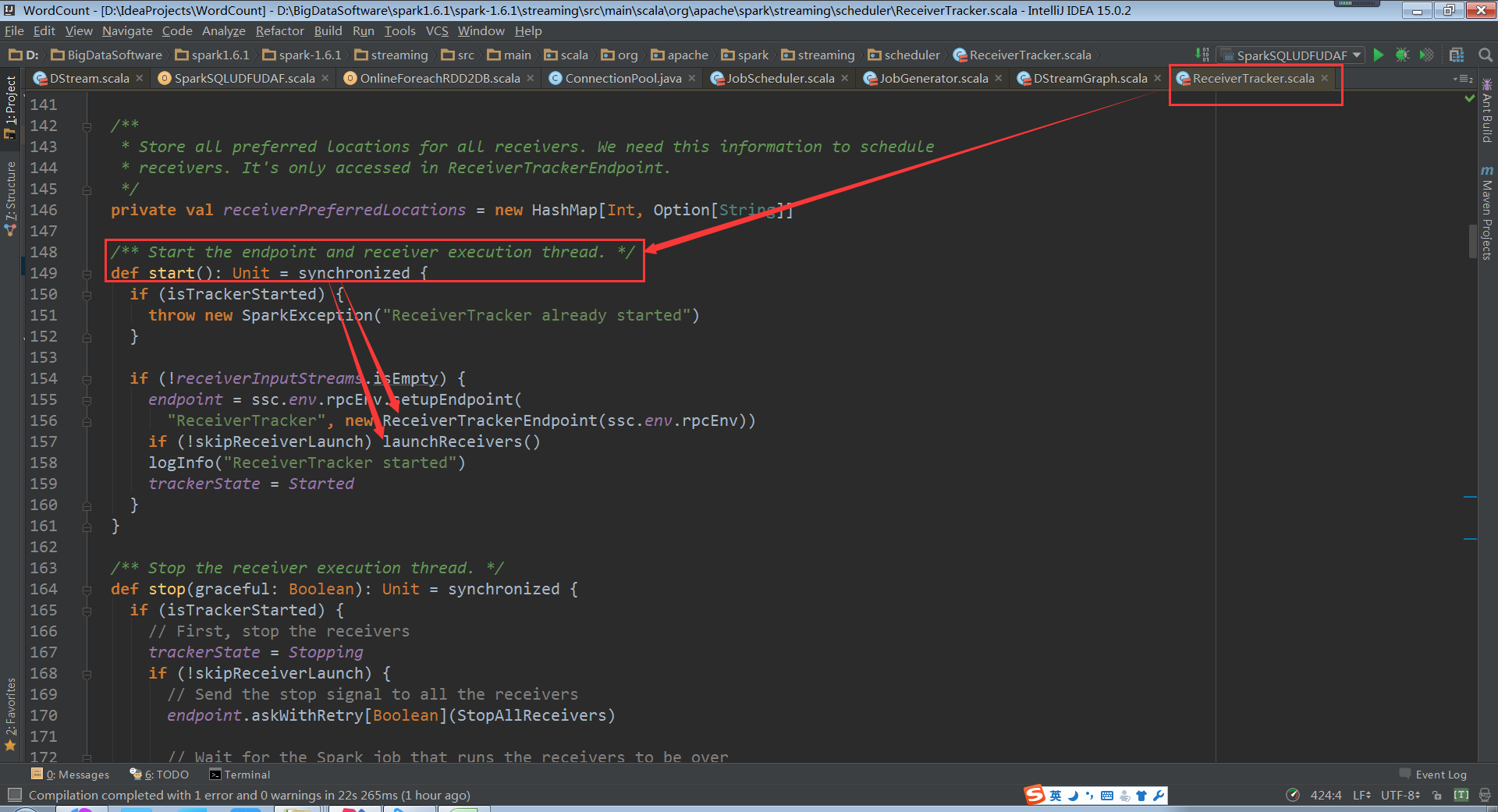
(ReceiverTacker.scala,149、157行代码)
- JobGenerator启动后会不断的根据batchDuration生成一个个的Job ;
(JobScheduler.scala,208行代码)
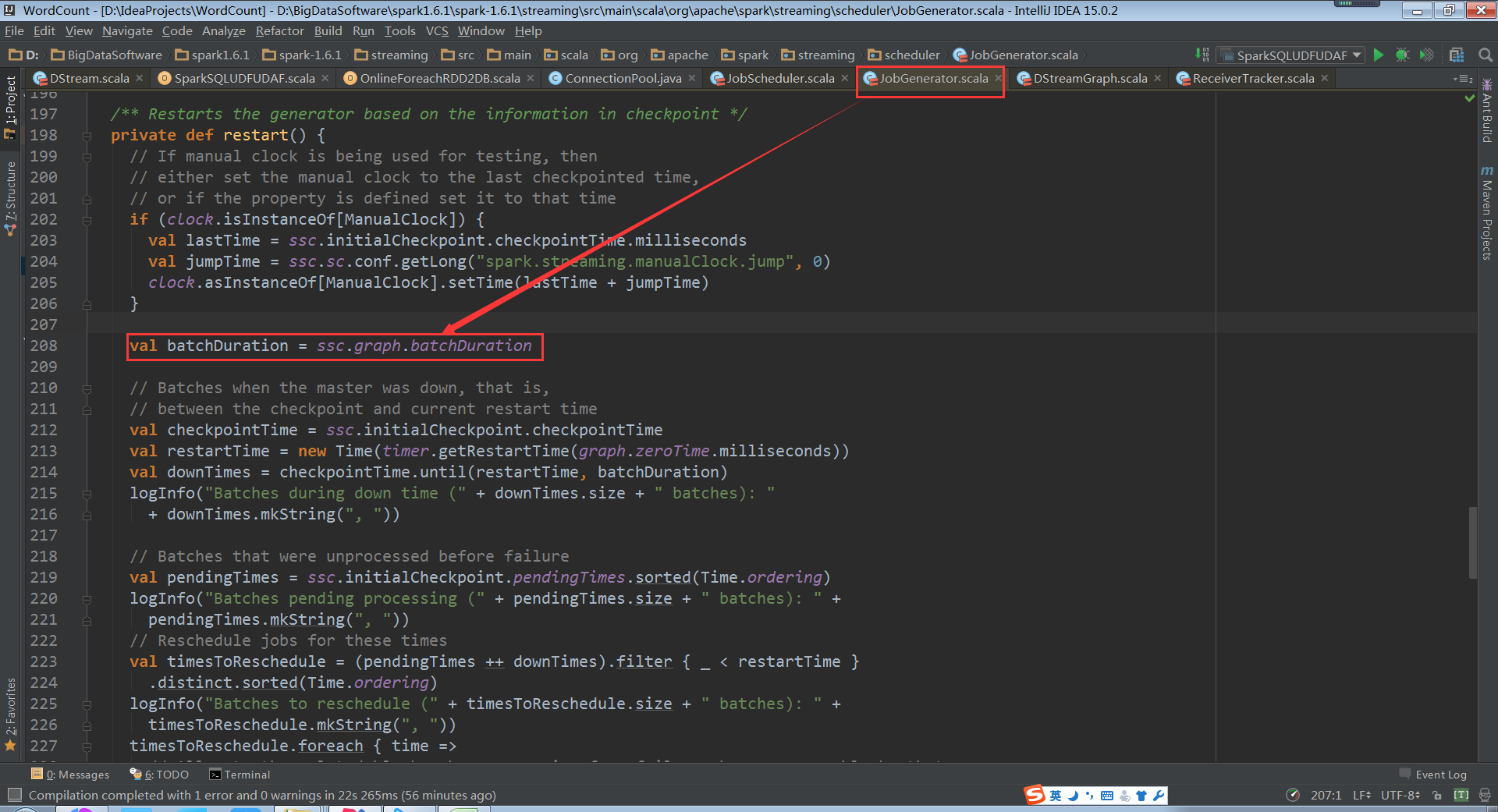
- ReceiverTracker的作用主要是两点:
1.对Receiver的运行进行管理,ReceiverTracker启动时会调用lanuchReceivers()方法,进而会使用rpc通信启动Receiver(实际代码中,Receiver外面还有一层包装ReceiverSupervisor实现高可用)
(ReceiverTracker.scala,423行代码)
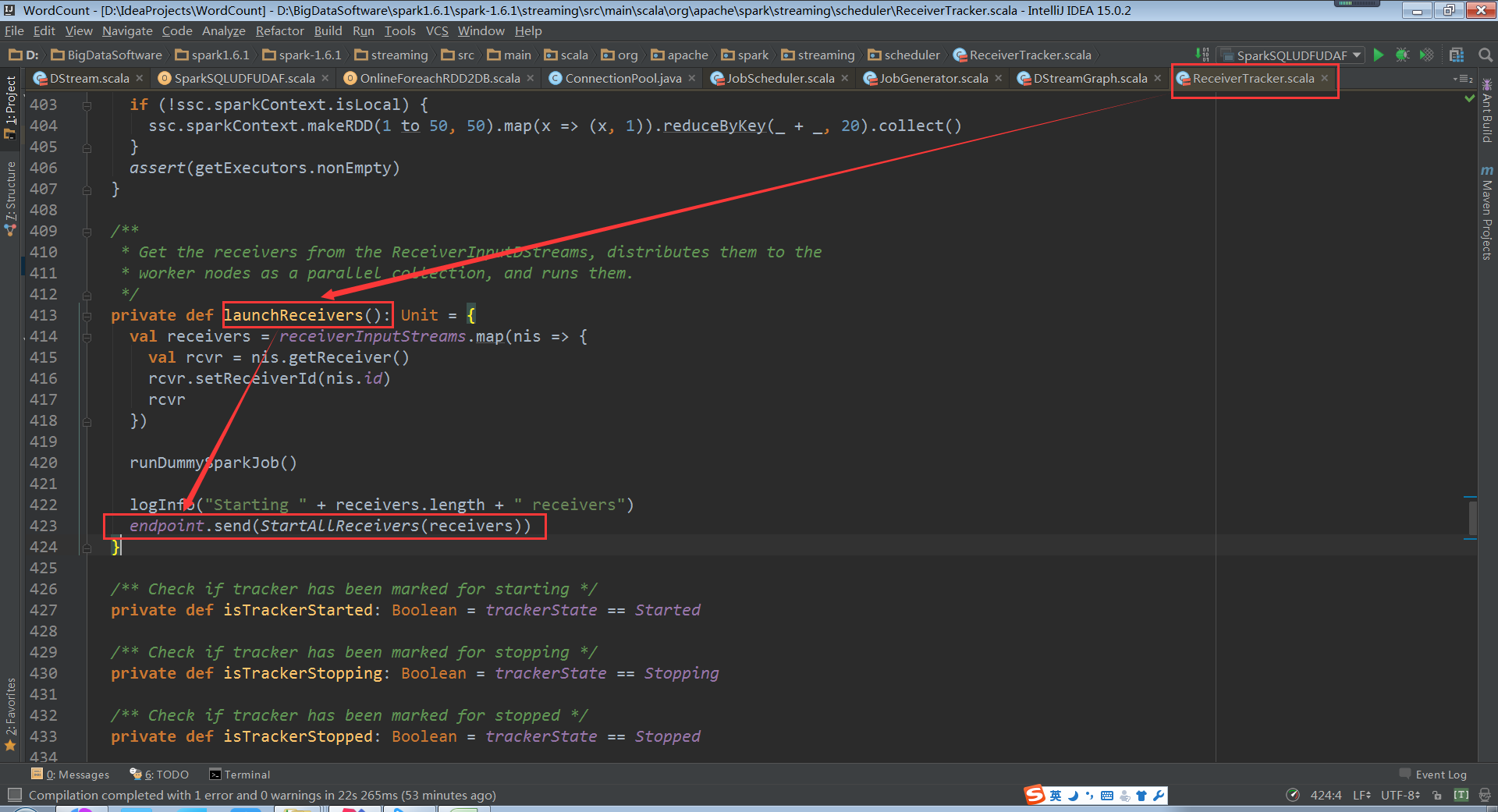
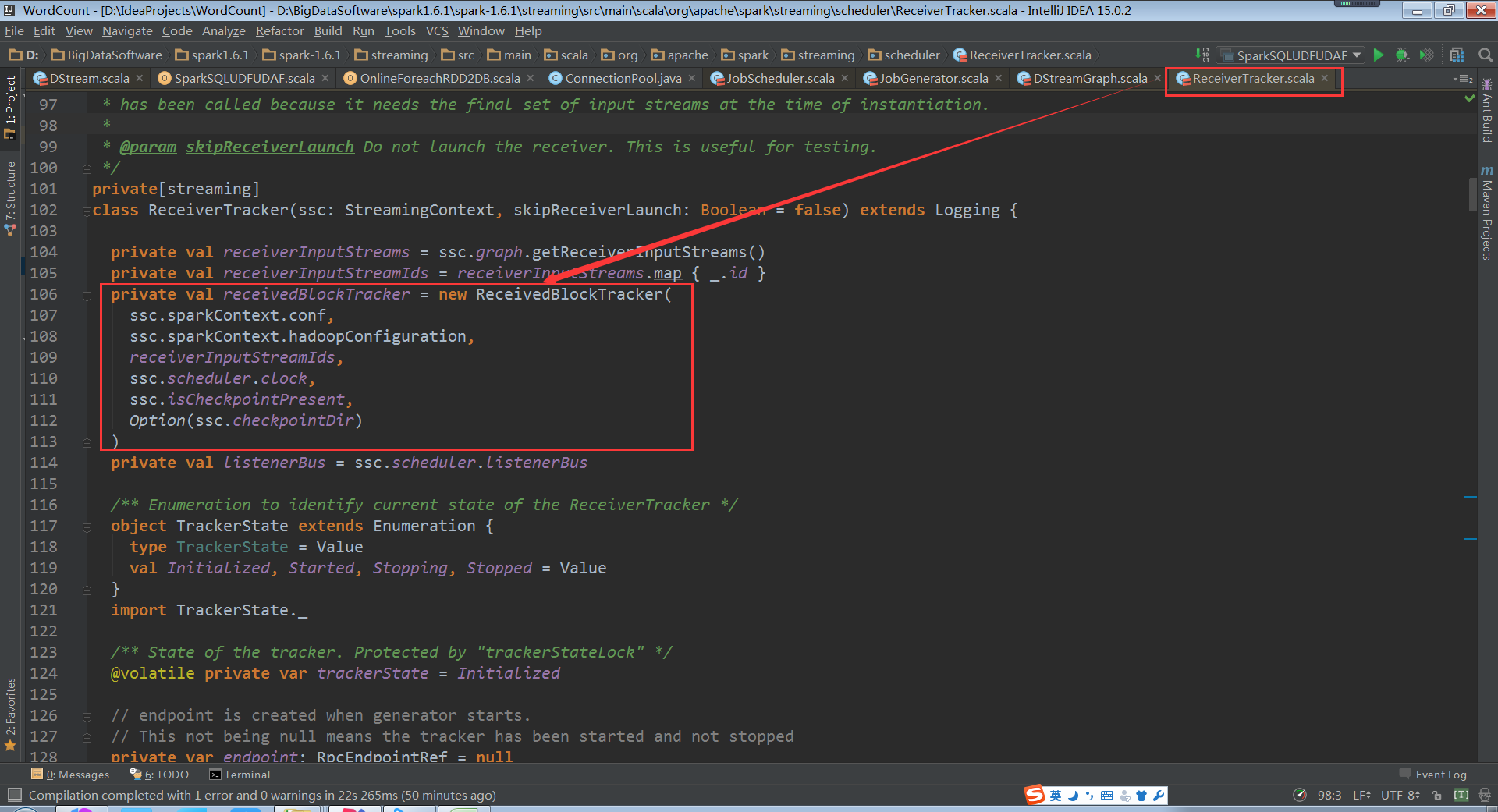
2.管理Receiver的元数据,供Job对数据进行索引,元数据的核心结构是receivedBlockTracker
(ReceiverTracker.scala,106~112行代码)
d、 在Receiver收到数据后会通过ReceiverSupervisor存储到Executor的BlockManager中 ;
e、 同时把数据的Metadata信息发送给Driver中的ReceiverTracker,在ReceiverTracker内部会通过ReceivedBlockTracker来管理接受到的元数据信息;
这里面涉及到两个Job的概念:
每个BatchInterval会产生一个具体的Job,其实这里的Job不是Spark Core中所指的Job,它只是基于DStreamGraph而生成的RDD的DAG而已,从Java角度讲,相当于Runnable接口实例,此时要想运行Job需要提交给JobScheduler,在JobScheduler中通过线程池的方式找到一个单独的线程来提交Job到集群运行(其实是在线程中基于RDD的Action触发真正的作业的运行)
为什么使用线程池呢?
a 、作业不断生成,所以为了提升效率,我们需要线程池;这和在Executor中通过线程池执行Task有异曲同工之妙;
b 、有可能设置了Job的FAIR公平调度的方式,这个时候也需要多线程的支持;
Spark Streaming Job 容错架构和运行机制
Spark Streaming是基于DStream的容错机制,DStream是随着时间流逝不断的产生RDD,也就是说DStream是在固定的时间上操作RDD,容错会划分到每一次所形成的RDD。
Spark Streaming的容错包括 Executor 与 Driver两方面的容错机制 :
a、 Executor 容错:
1. 数据接收:分布式方式、wal方式,先写日志再保存数据到Executor
2. 任务执行安全性 Job基于RDD容错 :
b、Driver容错 : checkpoint 。
基于RDD的特性,它的容错机制主要就是两种:
1. 基于checkpoint;
在stage之间,是宽依赖,产生了shuffle操作,lineage链条过于复杂和冗长,这时候就需要做checkpoint。
2. 基于lineage(血统)的容错:
一般而言,spark选择血统容错,因为对于大规模的数据集,做检查点的成本很高。
考虑到RDD的依赖关系,每个stage内部都是窄依赖,此时一般基于lineage容错,方便高效。
总结: stage内部做lineage,stage之间做checkpoint。















 9652
9652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









