







本博文主要包括以下内容:
- 解密Spark Streaming Job架构和运行机制
- 解密Spark Streaming容错架构和运行机制
一、解密SparkStreaming Job架构和运行机制:
理解SparkStreaming的Job的整个架构和运行机制对于精通SparkStreaming是至关重要的。我们知道对于一般的Spark应用程序来说,是RDD的action操作触发了Job的运行。那对于SparkStreaming来说,Job是怎么样运行的呢?我们在编写SparkStreaming程序的时候,设置了BatchDuration,Job每隔BatchDuration时间会自动触发,这个功能肯定是SparkStreaming框架提供了一个定时器,时间一到就将编写的程序提交给Spark,并以Spark job的方式运行。
这里面涉及到两个Job的概念:
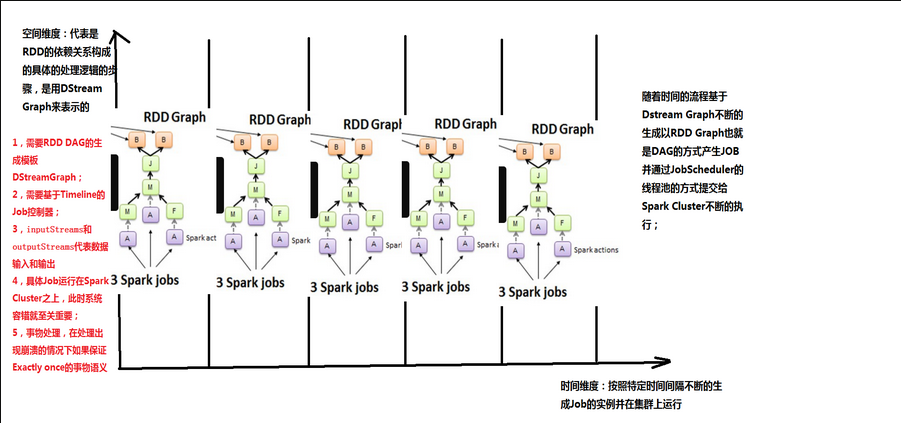
每个BatchInterval会产生一个具体的Job,其实这里的Job不是Spark Core中所指的Job,它只是基于DStreamGraph(代表RDD的依赖关系具体构成)而生成的RDD的DAG而已,从Java角度讲,相当于Runnable接口实例,此时要想运行Job需要提交给JobScheduler,在JobScheduler中通过线程池的方式找到一个单独的线程来提交Job到集群运行(其实是在线程中基于RDD的Action触发真正的作业的运行),为什么使用线程池呢?
- 作业不断生成,所以为了提升效率,我们需要线程池;这和在Executor中通过线程池执行Task有异曲同工之妙;
- 有可能设置了Job的FAIR公平调度的方式,这个时候也需要多线程的支持;
上面提交的Spark Job本身。单从这个时刻来看,此次的Job和Spark core中的Job没有任何的区别。
下面我们看看job运行的过程:
1.首先实例化SparkConf,设置运行期参数。
val conf = new SparkConf().setAppName("--")2.实例化StreamingContext,设置batchDuration时间间隔来控制Job生成的频率并且创建Spark Streaming执行的入口。
val ssc = new StreamingContext(conf,Seconds(20))3,StreamingContext.scala的第183行
private[streaming] val scheduler = new JobScheduler(this)4,JobScheduler.scala的第50行
private val jobGenerator = new JobGenerator(this)5,StreamingContext调用start方法。
def start(): Unit = synchronized {
state match {
c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









