







本讲内容:
a. Executor的WAL机制详解
b. 消息重放Kafka
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
上节回顾
上一讲中,我们主要解密了ReceiverTracker具体的架构及其功能、源码实现;
ReceiverTracker的架构设计
a. ReceiverTracker以Driver中具体的算法在具体的Executor之上启动Receiver,而且启动Receiver的方式是把每个Receiver封装成一个Task, 此时一个Job中就一个Task,而Task中就一条数据,也就是Receiver数据,实质上说,ReceiverTracker启动Receiver之时就会封装在一个个Job,有多个Job就有多个Receiver,即有多个Receiver启动就有多个Job封装
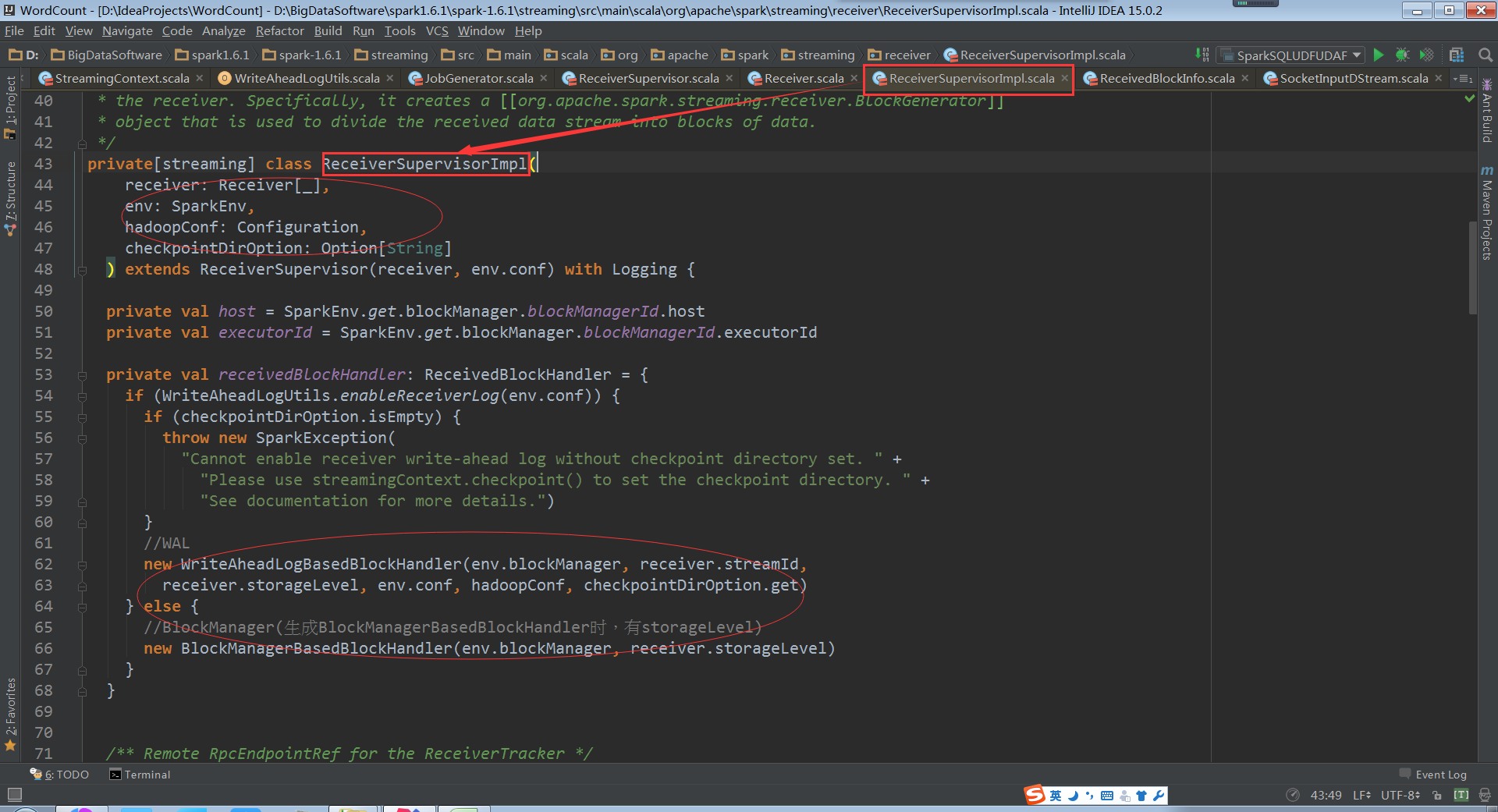
b. ReceiverTracker在启动Receiver的时候,有一个Receiversupervisor其里面有一个ReceiversupervisorImpl实现类, Receiversupervisor实际上启动之时就启动了Receiver,Receiver不断的接收数据,通过BlockGenerator把自已“接收的数据”变成一个个的Block。然后在时间定时器的作用下会不断的把数据存储(此时存储有2种方式,第一种是通过BlockManager方式存储,另一种先写日志Write,通过WAL方式),数据存储之后ReceiverSupervisorImpl会把存储后的数据的元数据Metadate汇报给ReceiverTracker,其实是汇报给ReceiverTracker中的RPC实体ReceiverTrackerEndpoint
c. ReceiverTracker用来管理Receiver中的数据执行,数据执行层面包括Receiver的启动、回收、执行过程中接收数据的管理,当然也包括“Receiver”的容错
d. Receiver接收到数据之后合并存储数据后,ReceiverSupervisorImpl会把数据汇报给ReceiverTracker, ReceiverTracker接收到元数据,其内部汇报的是RPC通信体,接收到数据之后,内部有ReceivedBlockTracker会管理数据的分配,JobGenerator会将每个Batch,每次工作的时候会根据元数据信息从ReceiverTracker中获取相应的元数据信息生成RDD。
e. ReceiverBlockTracker中 allocateBlocksToBatch专门管理Block元数据信息,作为一个内部的管理对象。
还了解了什么是门面设计模式
从设计模式来讲:ReceiverTrackerEndpoint和ReceivedBlockTracker是门面设计模式,。
ReceiverTracker和ReceivedBlockTracker的关系是:内部实际干事情的是ReceivedBlockTracker,外部通信体或者代表者就是ReceiverTracker
开讲
本讲我们从安全角度来讲解Spark Streaming,由于Spark Streaming会不断的接收数据、不断的产生job、不断的提交job。所以数据的安全性至关重要。
首先我们来谈谈,对于数据安全性的考虑:
a. Spark Streaming是基于Spark Core之上的,如果能够确保数据安全可好的话,在Spark Streaming生成Job的时候里面是基于RDD,即使运行的时候出现问题,那么Spark Streaming也可以借助Spark Core的容错机制自动容错
b. 对于executor的安全容错主要是数据的安全容错。Executor计算时候的安全容错是借助Spark core的RDD的,所以天然是安全的
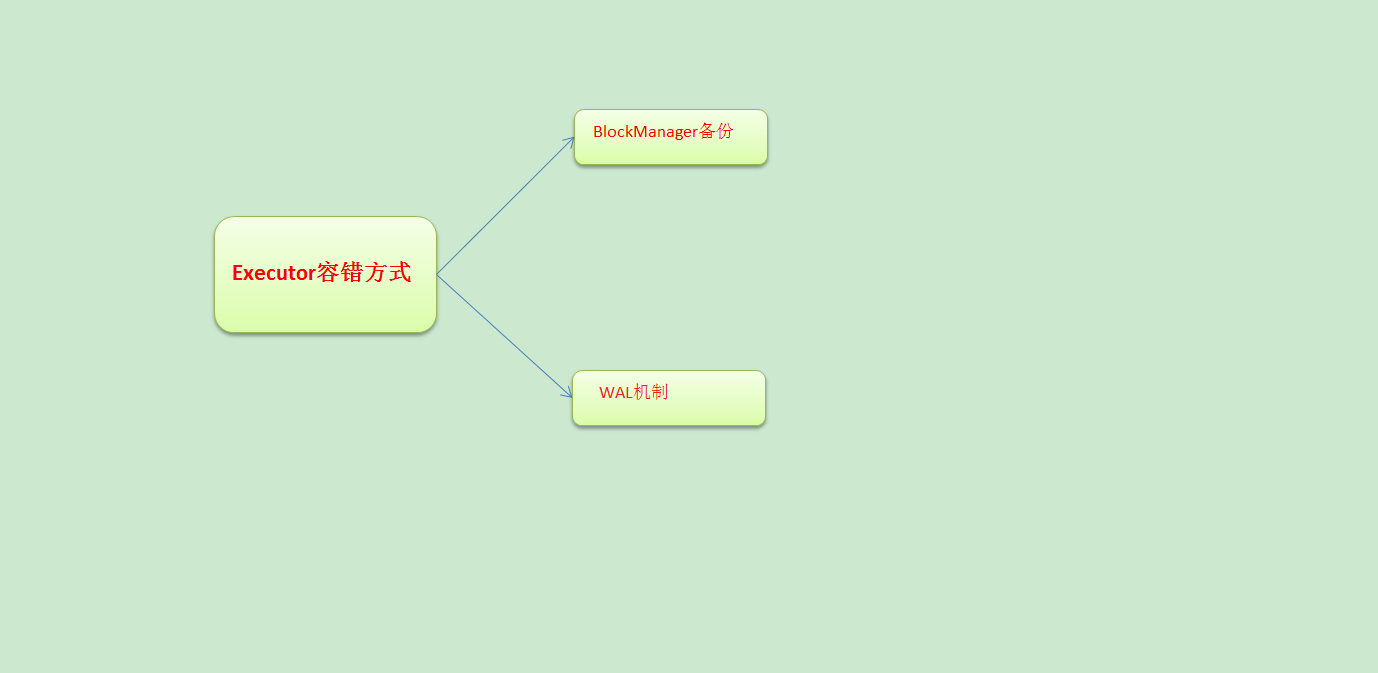
那么Executor容错方式是什么呢?
a. 最简单的容错是副本方式,基于底层BlockManager副本容错,也是默认的容错方式
b. 接收到数据之后不做副本,支持数据重放,所谓重放就是支持反复读取数据
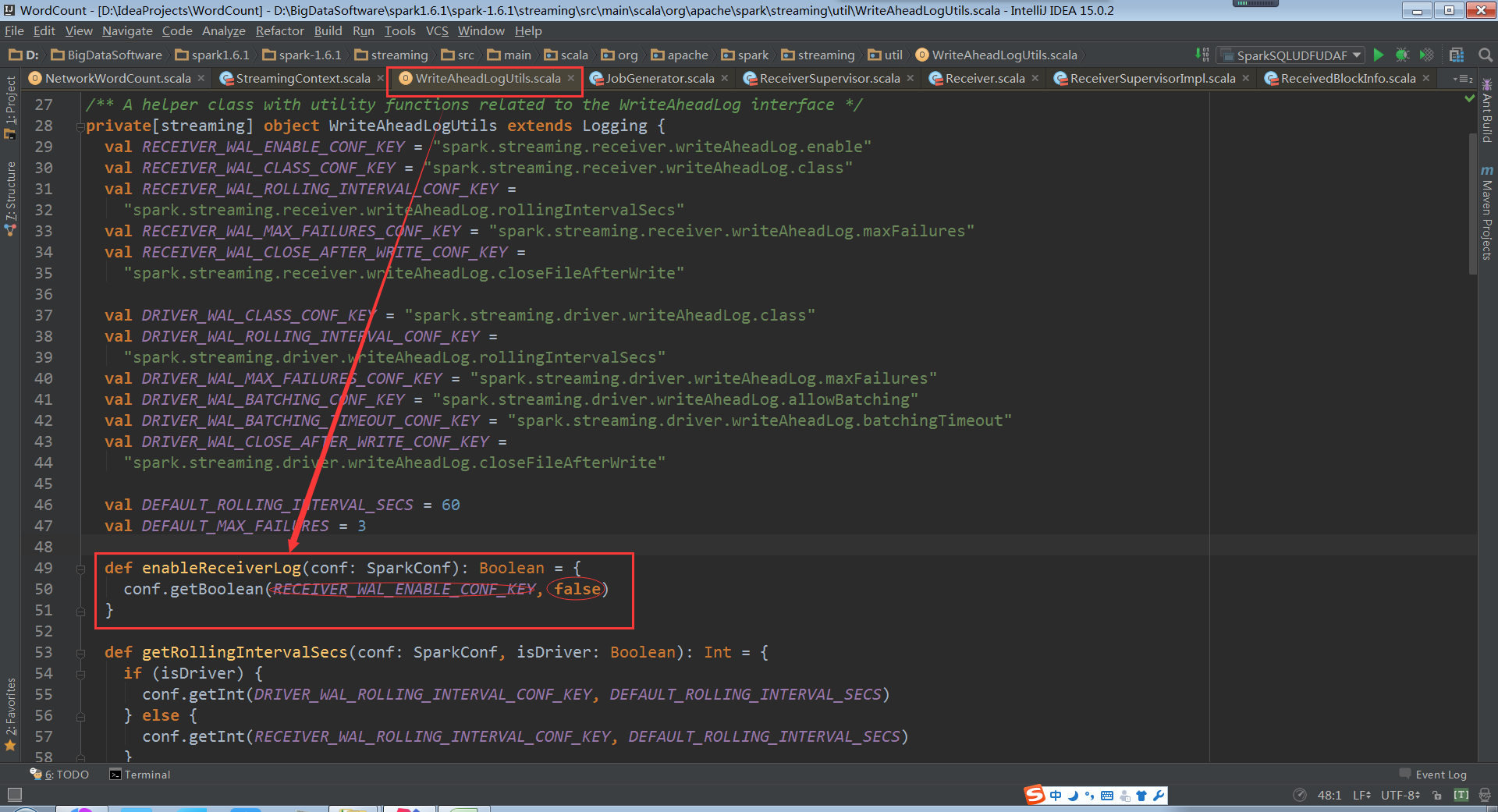
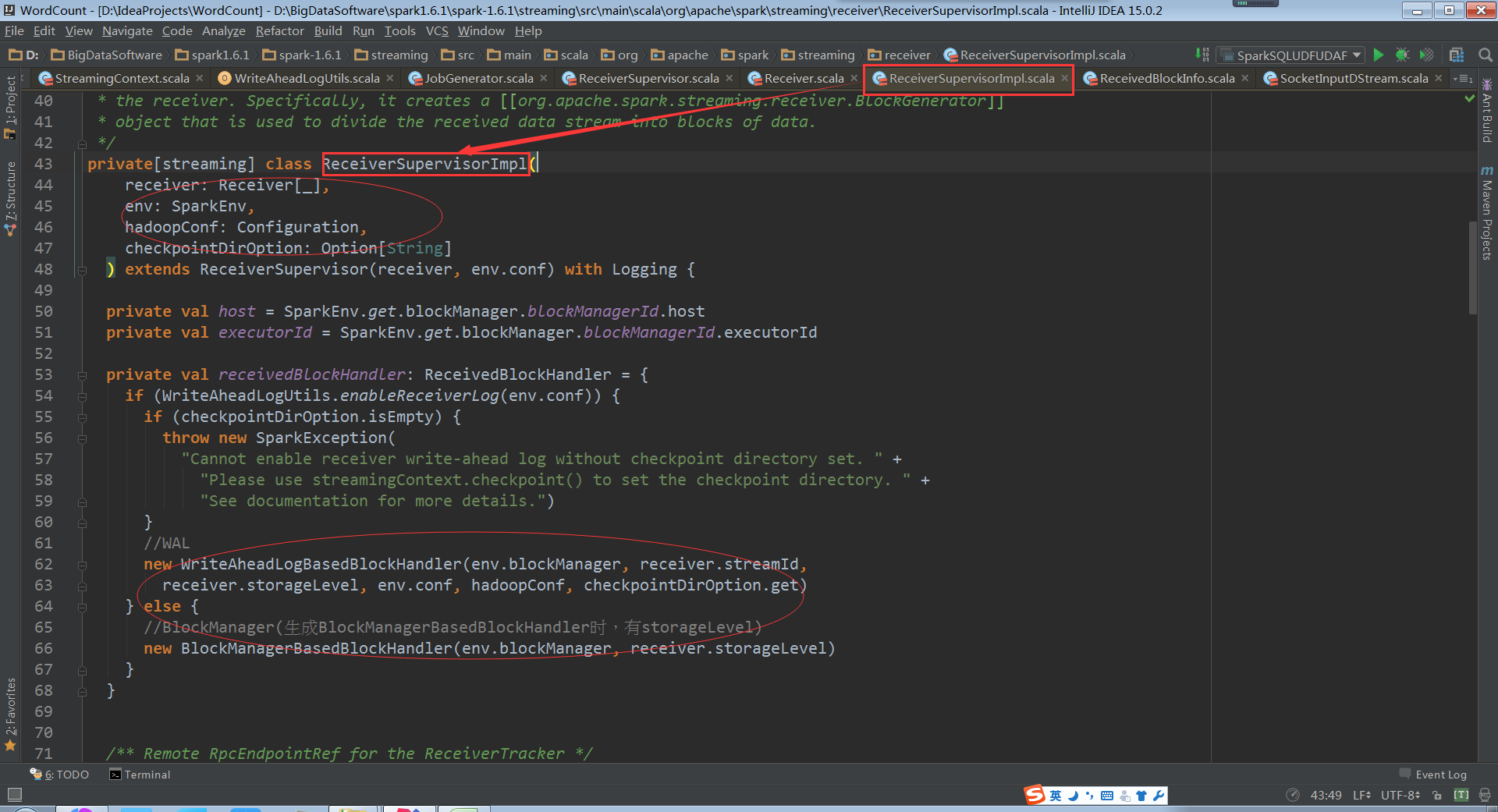
ReceiverSupervisorImpl在存储数据的时候会有两种方式,一种是WAL的方式,究竟是不是WAL得方式是通过配置修改的。默认是false。如果用WAL的方式必须有checkpoint的目录,因为WAL的数据是放在checkpoint的目录之下的
BlockManager备份
Blockmanager存储数据的时候有很多storagelevel,Receiver接收数据后,存储的时候指定storagelevel为MEMORY_AND_DISK_SER_2的方式。Blockmanager早存储的时候会先考虑memory,只有memory不够的时候才会考虑disk,一般memory都是够的。所以至少两个executor上都会有数据,假设一个executor挂掉,就会马上切换到另一个executor
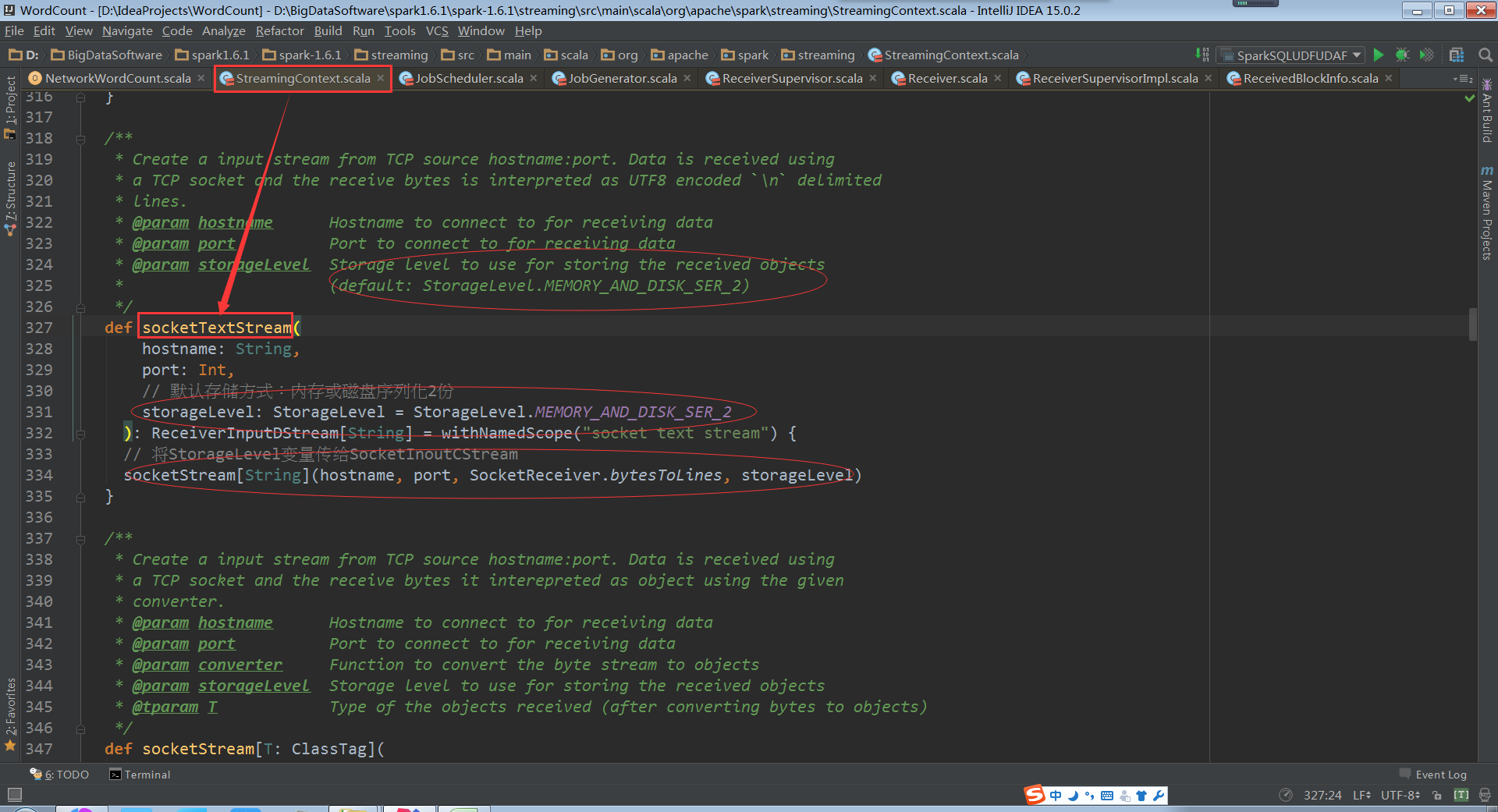
Storagelevel是在构建InputDStream的时候传入的,默认就是MEMORY_AND_DISK_SER_2
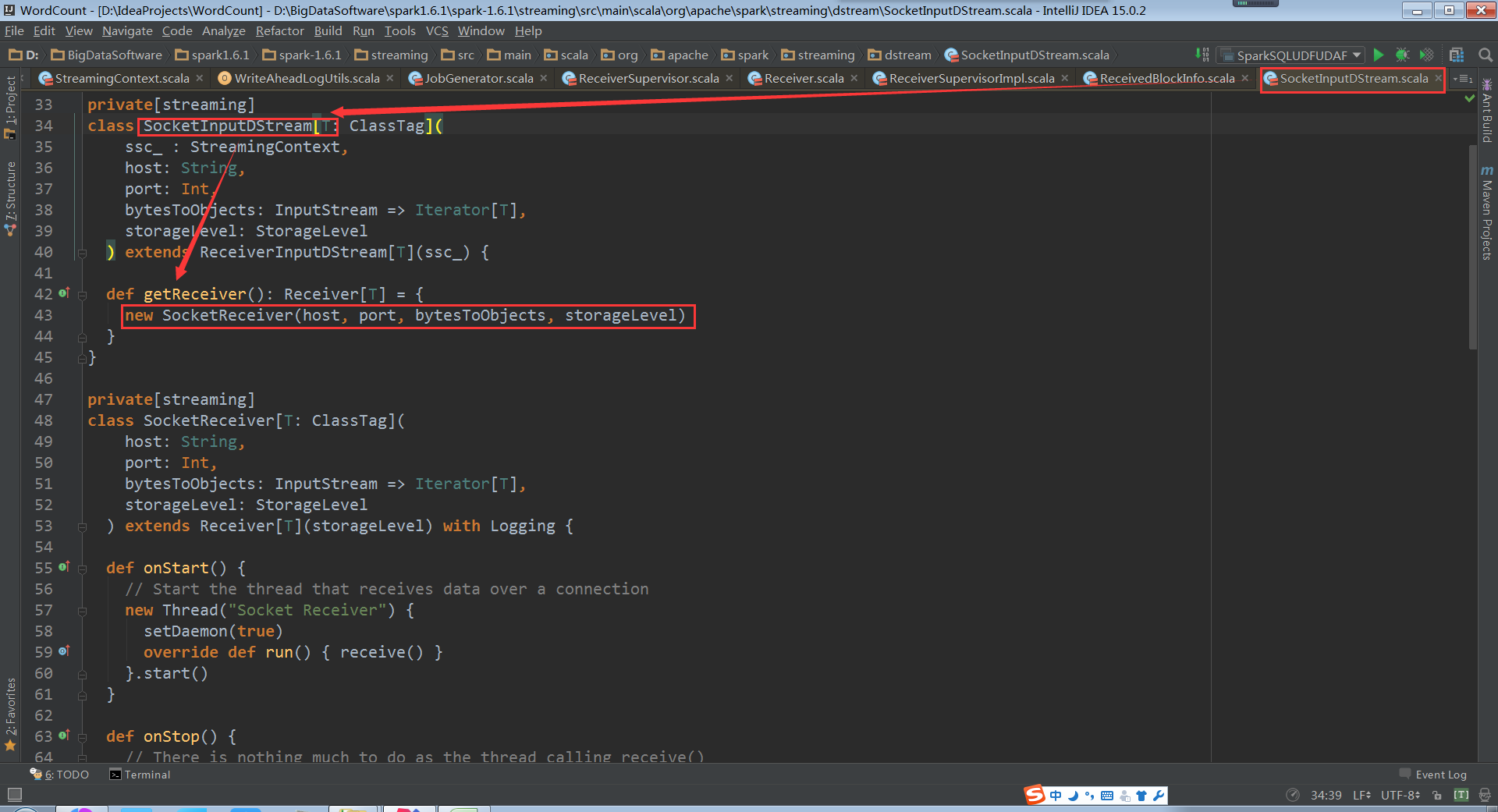
我们来看看Receiver,发现都有StorageLevel变量
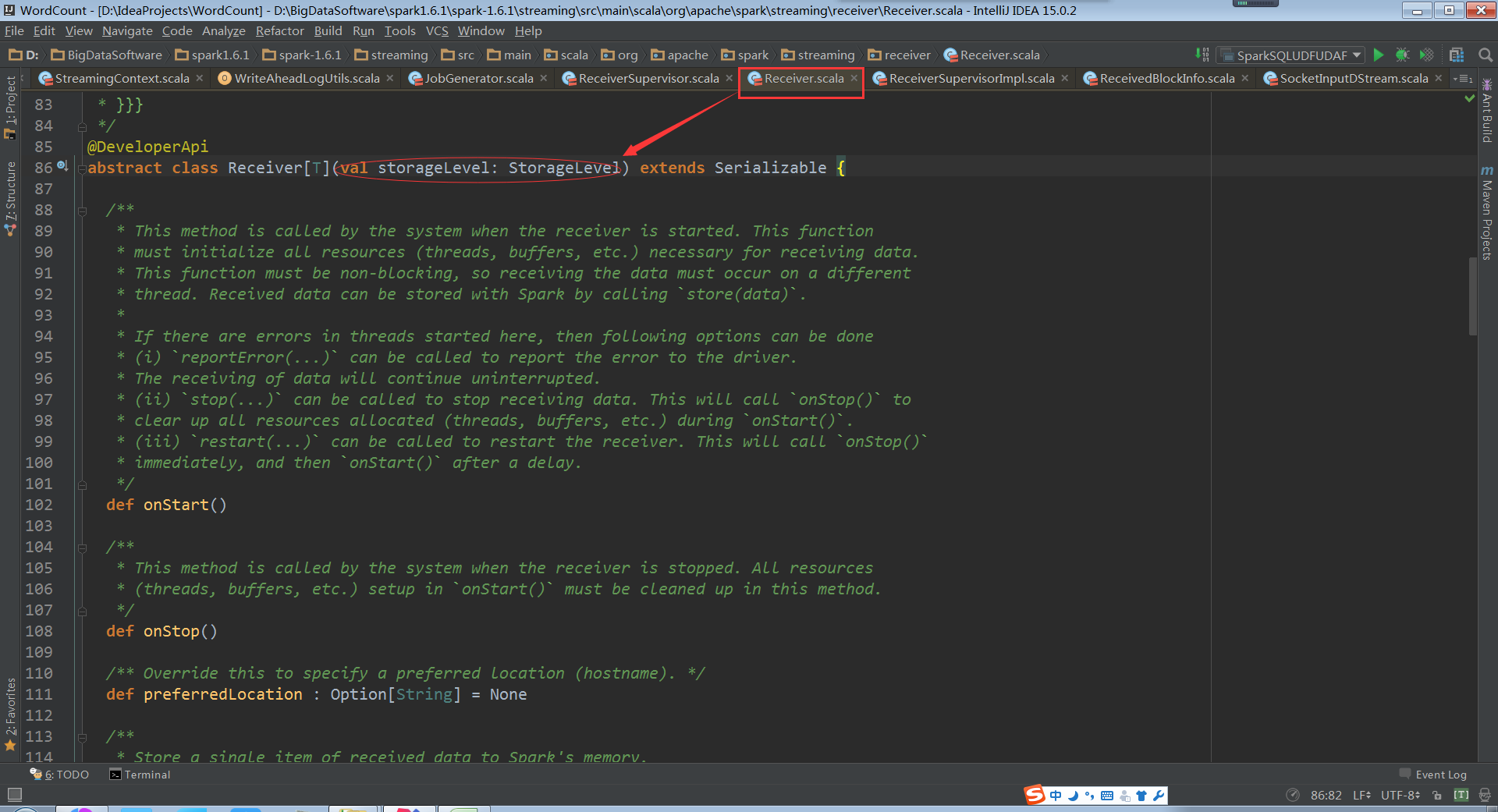
现在来看ReceiverSupervisorImpl
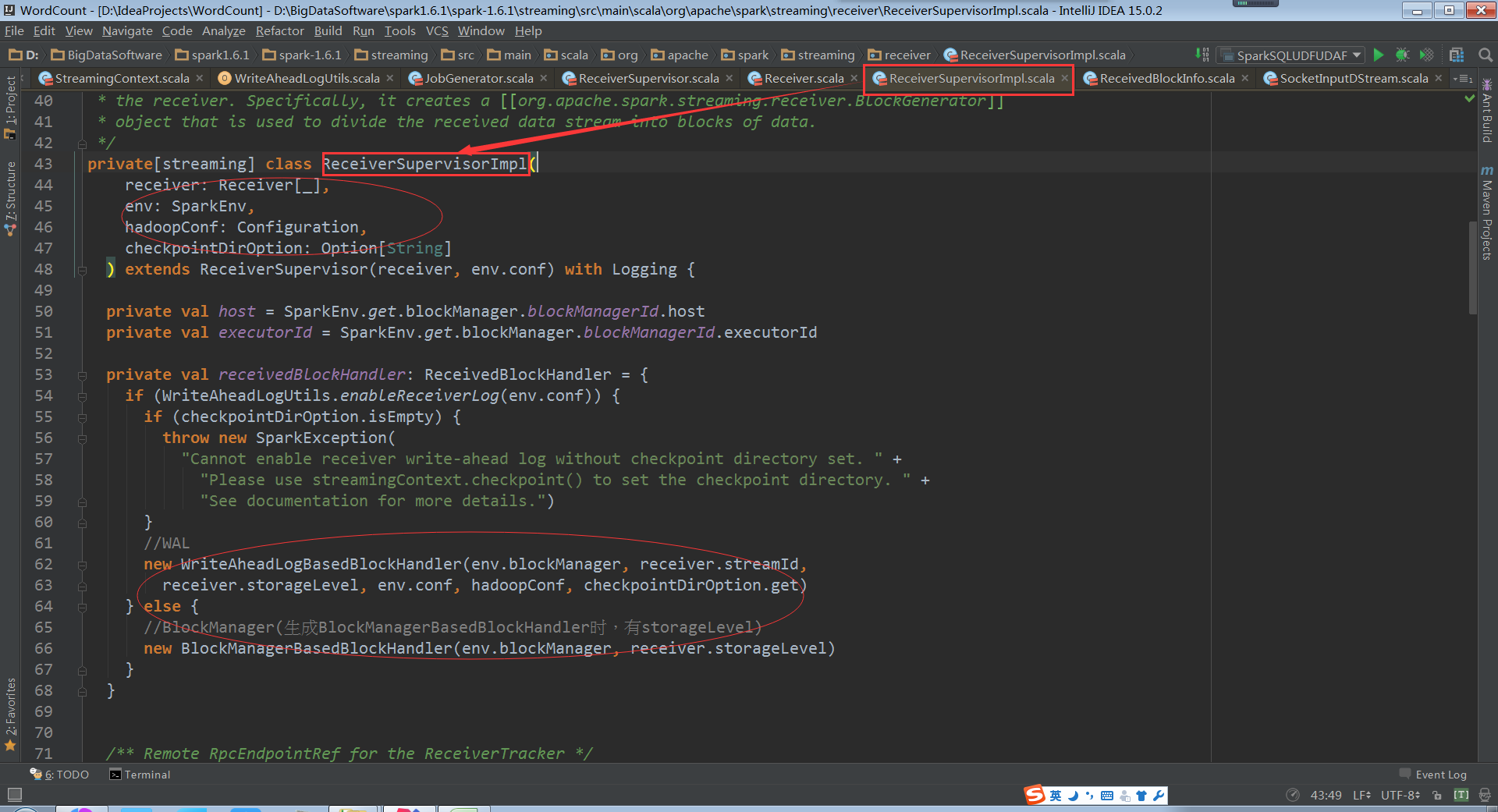
所以ReceiverSupervisorImpl在以副本方式存储数据的时候;根据指定的storagelevel把接收的blocks交给blockmanager。也就是通过blockmanager来存储
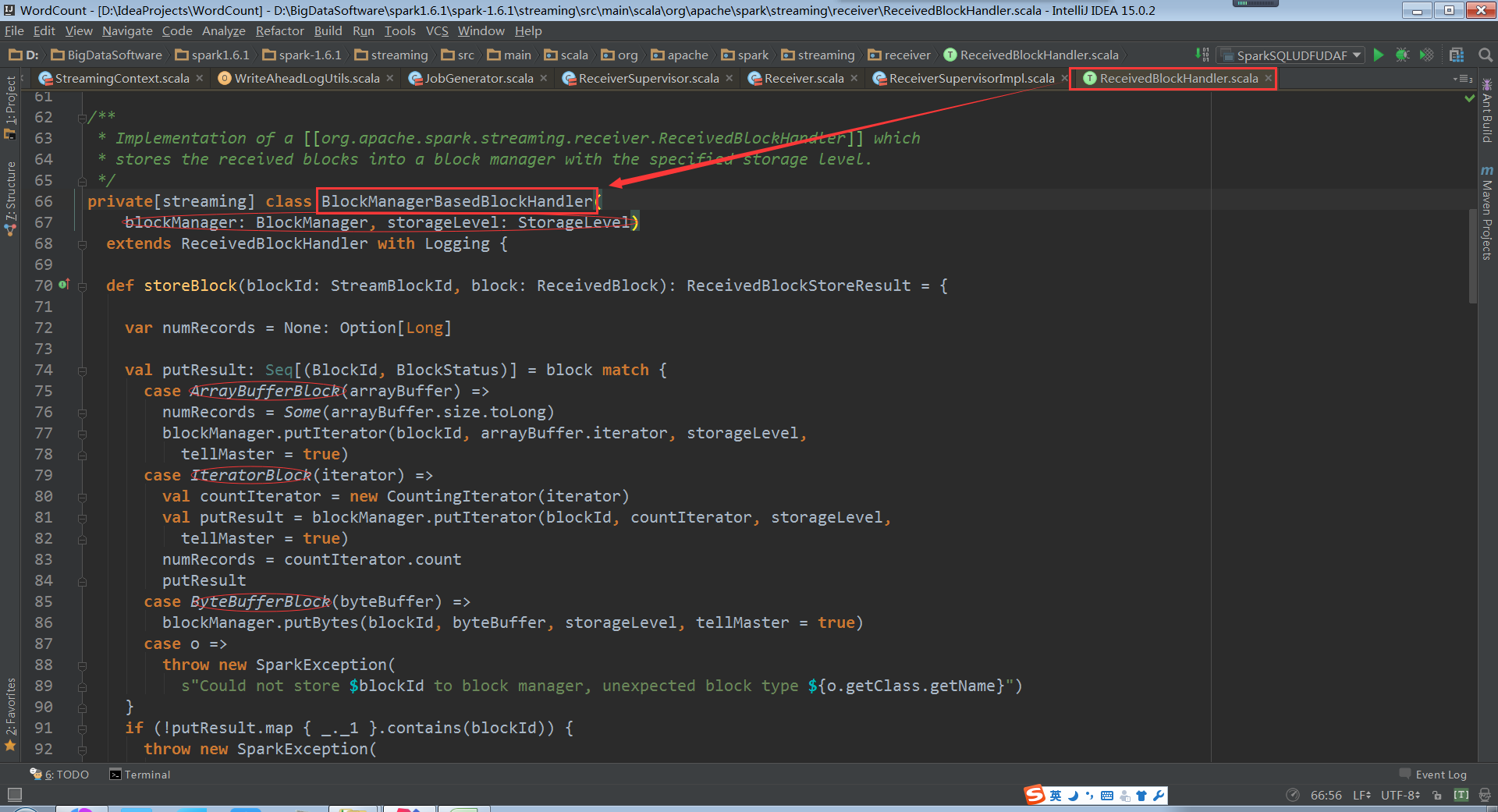
Blockmanager存储的时候会分为多种不同的数据类型,ArrayBufferBlock,IteratorBlock,ByteBufferBlock
有上面的BlockManagerBasedBlockHandler源码具体实现是通过putIterator
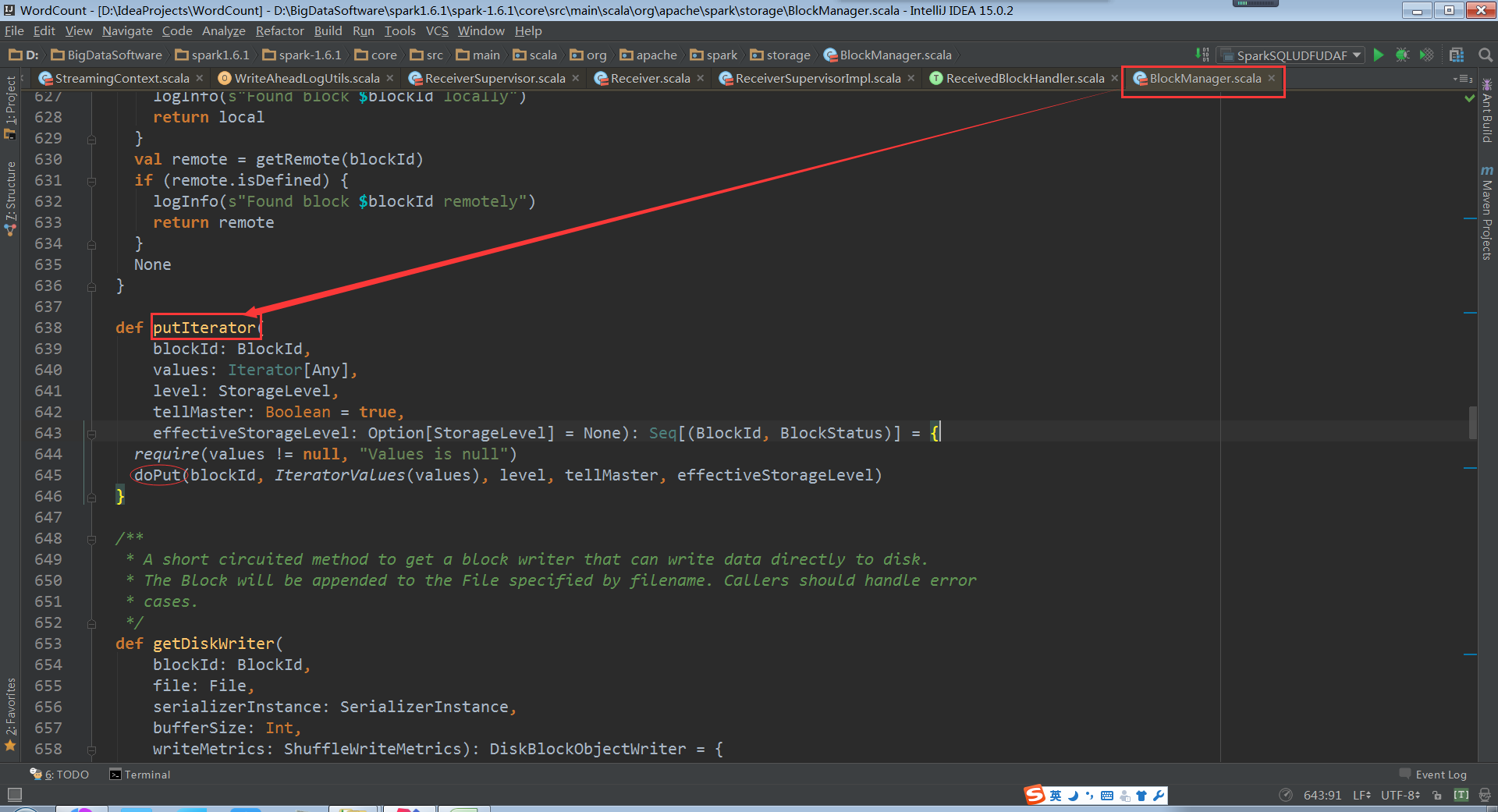
doPut源码如下
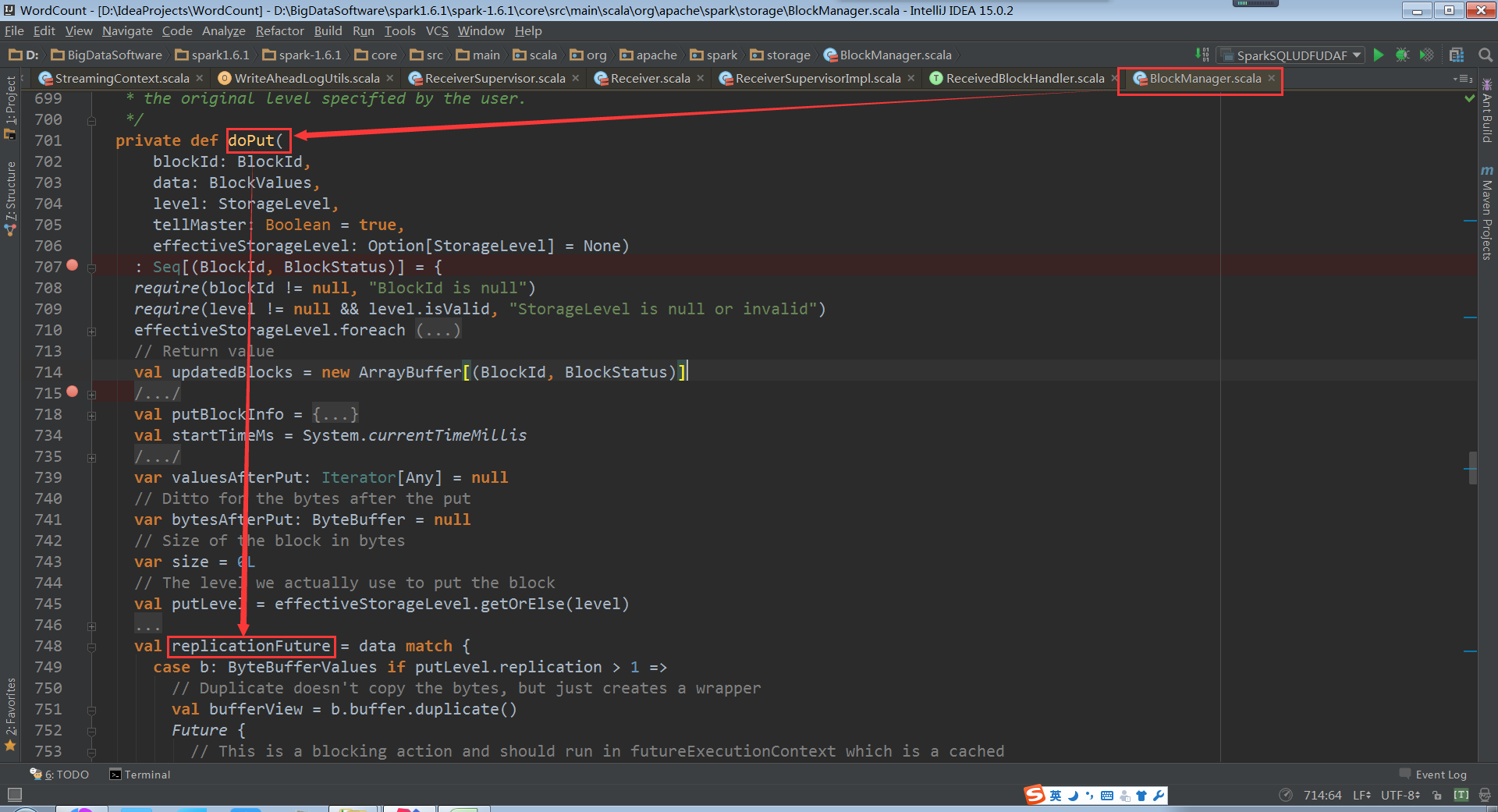
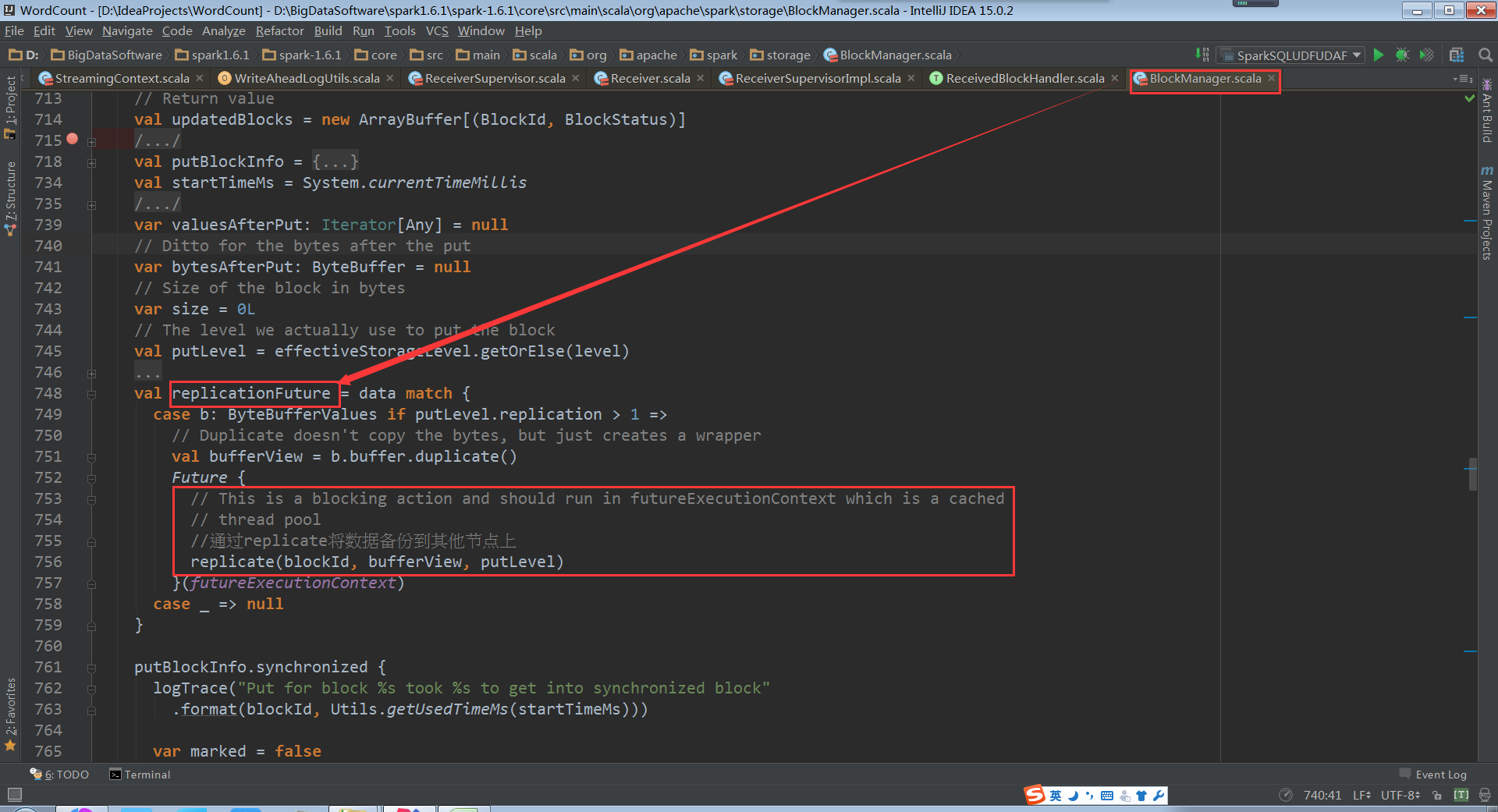
replicate源码如下:
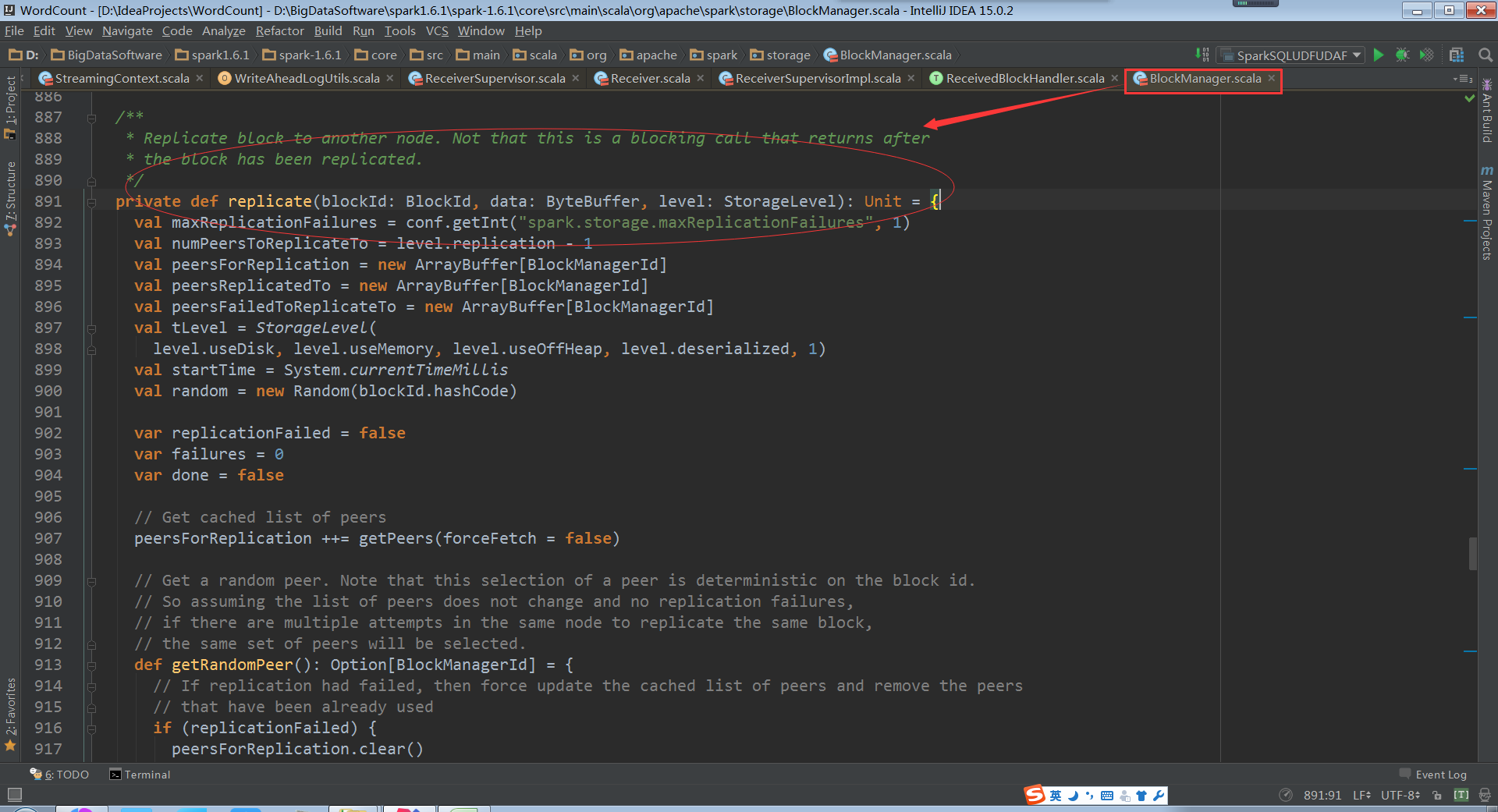
把数据备份到另一个节点
WAL方式
WAL的方式原理:在具体的目录下会做一份日志,假设后续处理的过程中出了问题,可以基于日志恢复,日志是写在checkpoint下。在生产环境下checkpoint是在HDFS上,这样日志就会有三份副本
进入到ReceivedBlockHandler源码
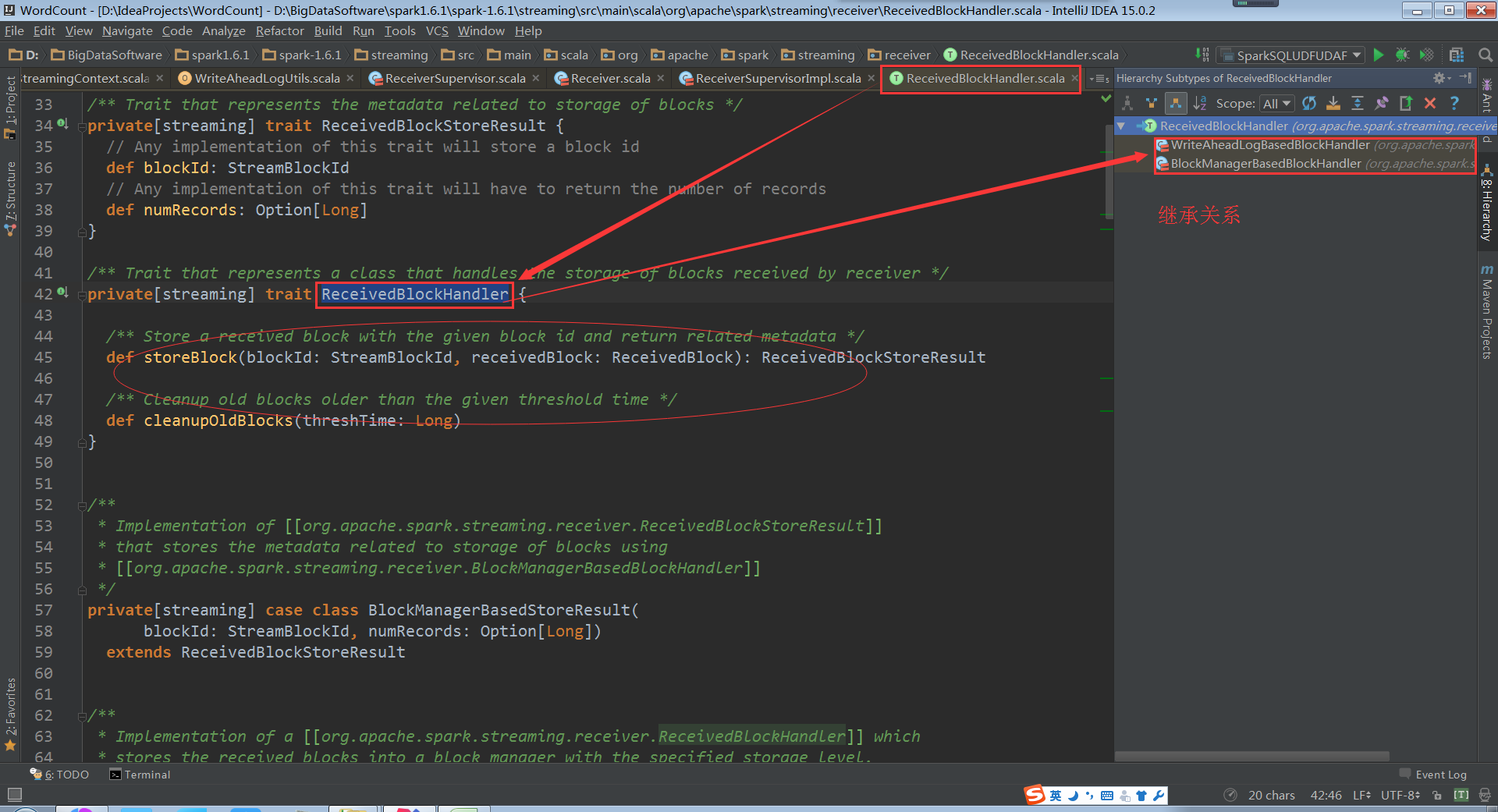
进入到WriteAheadLogBasedBlockHandler源码
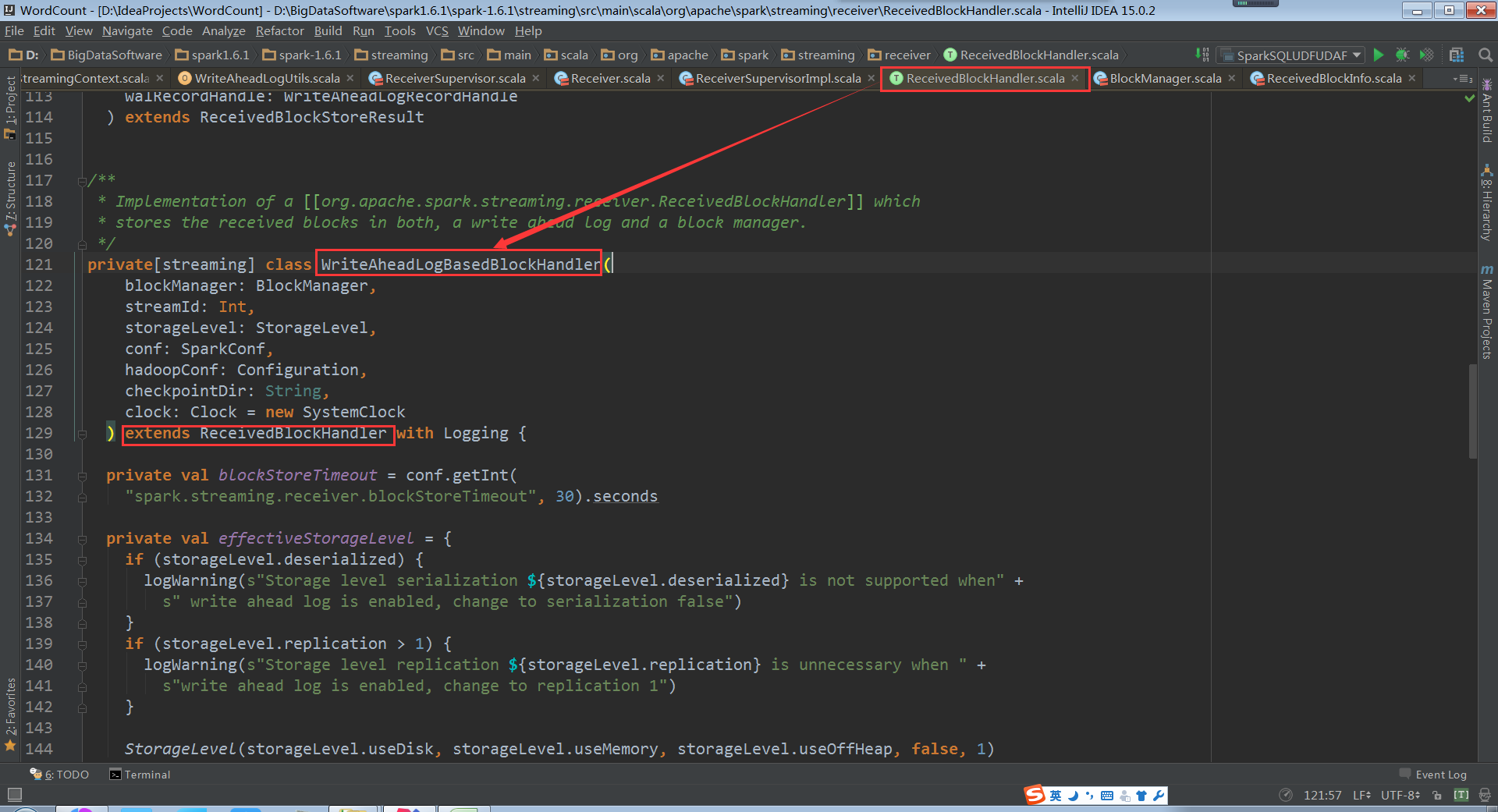
使用WAL,就没必要将replication变成2份。WAL是写到checkpoint目录中,而checkpoint是保持在HDFS中,HDFS默认是3份副本
存储数据的时候是同时往WAL和BlockManager中放数据
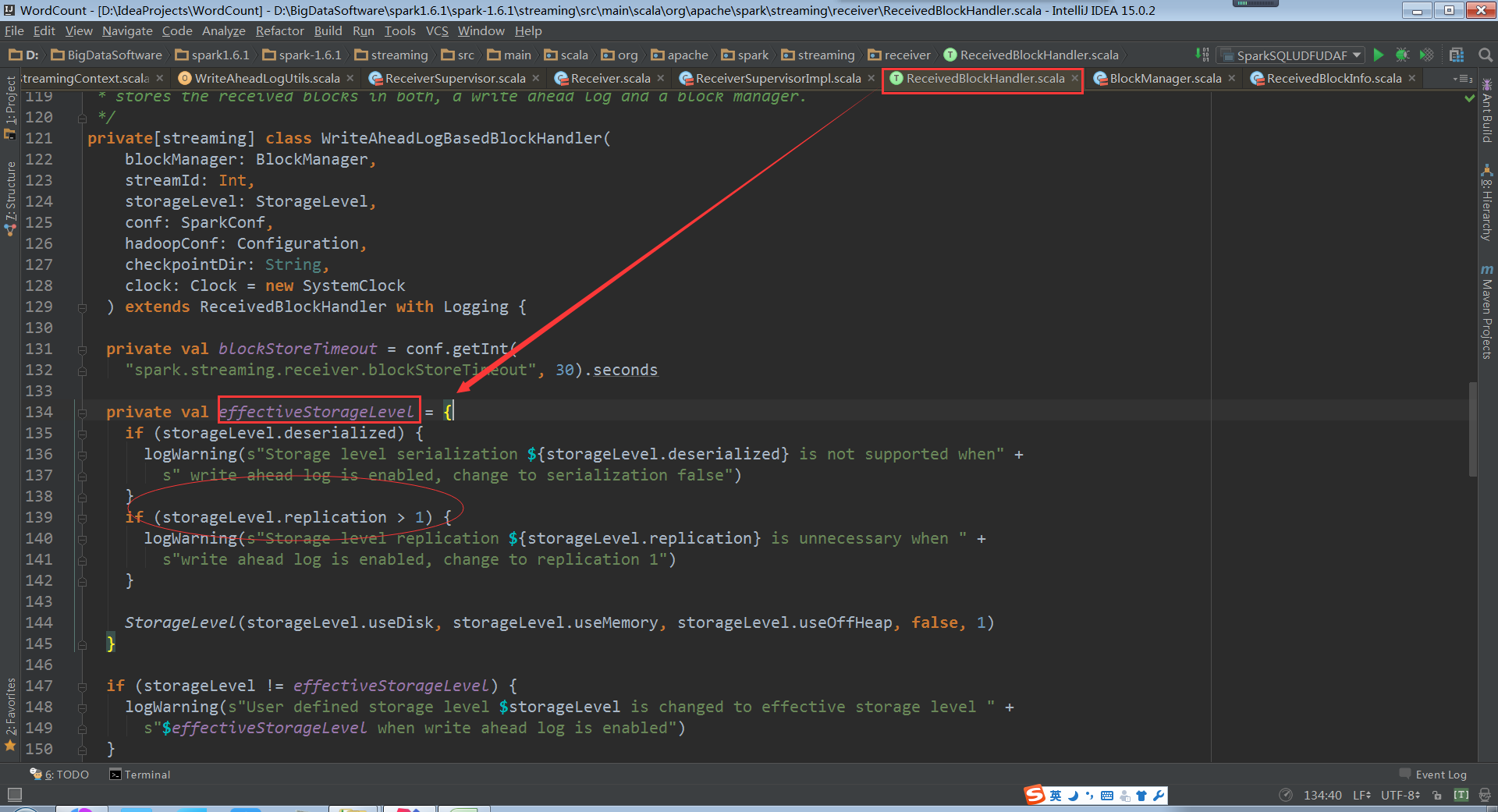
然后将数据存储到BlockManager中
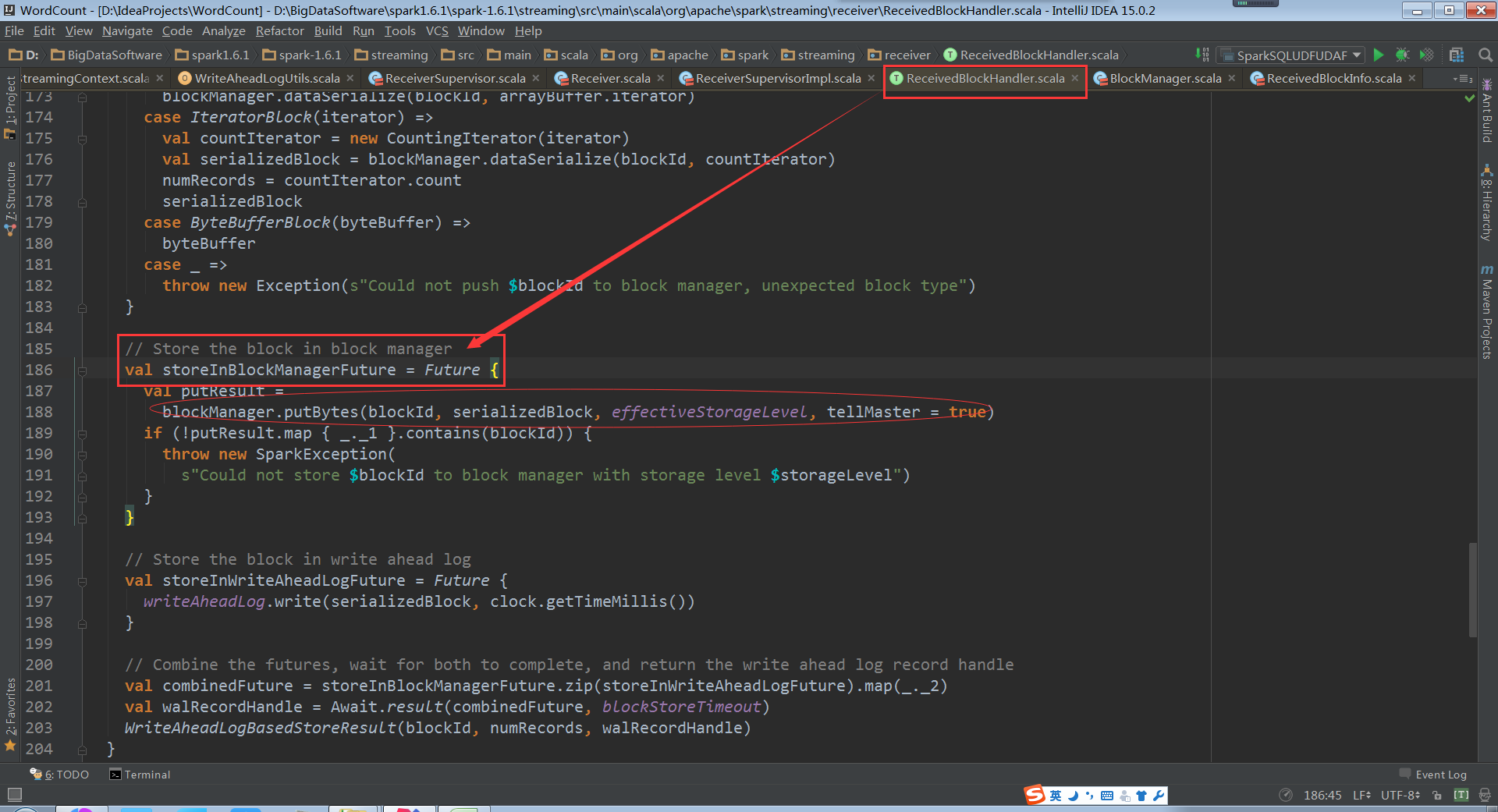
使用write方法写入到log中
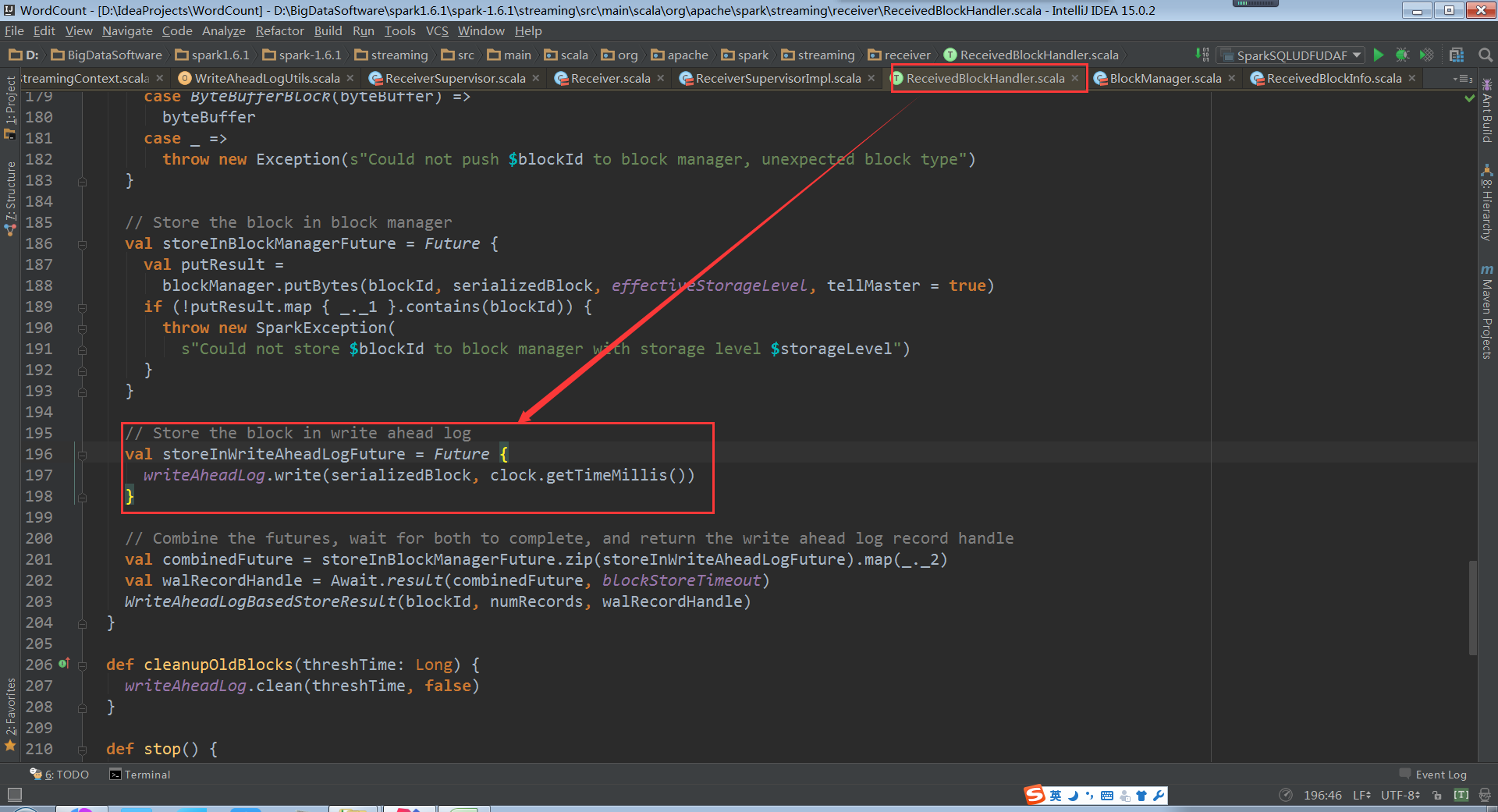
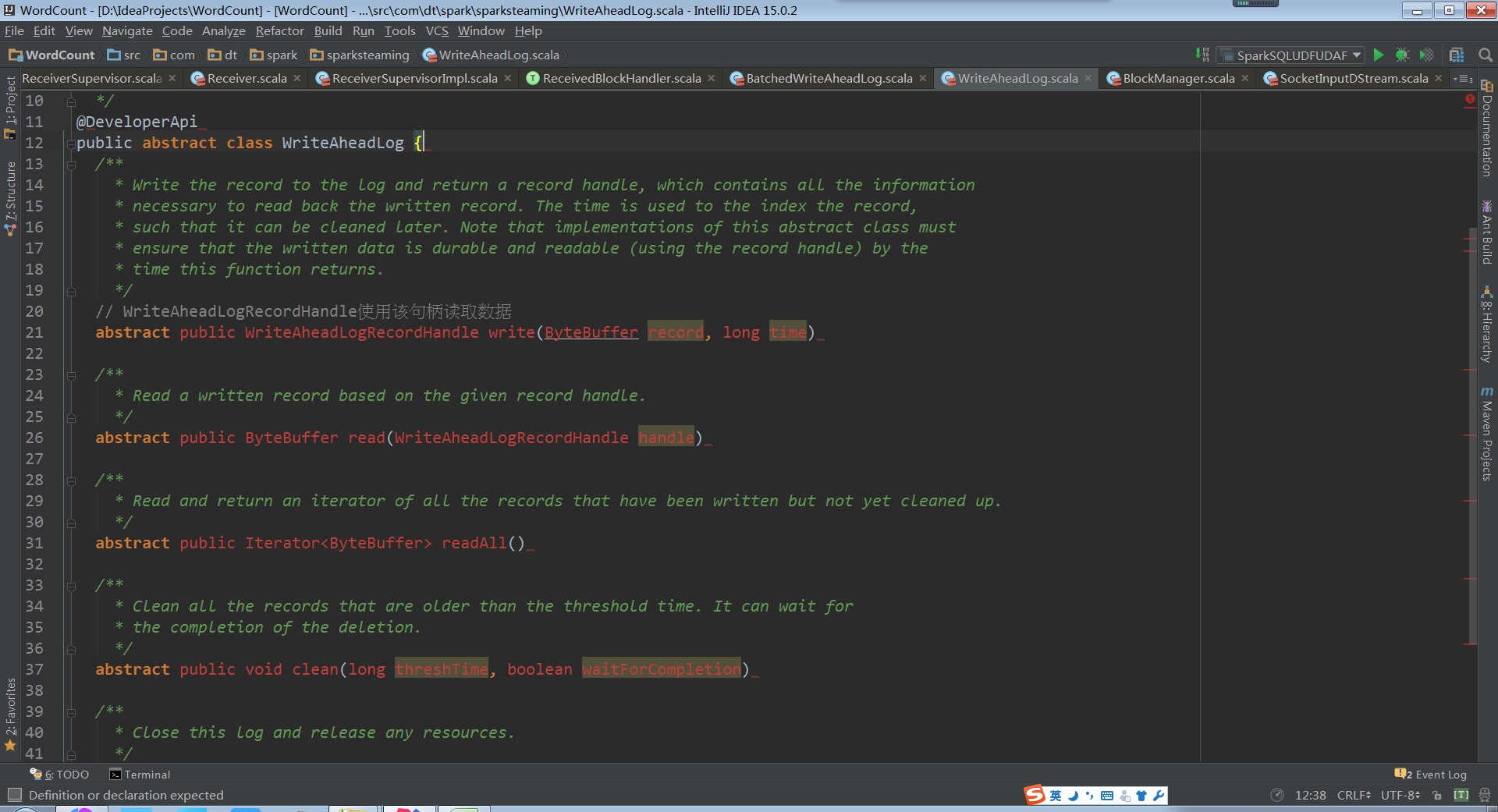
WAL写数据的时候是顺序写,数据不可修改,所以读的时候只需要按照指针(也就是要读的record在那,长度是多少)读即可。所以WAL的速度非常快
FileBasedWriteAheadLog管理WAL文件
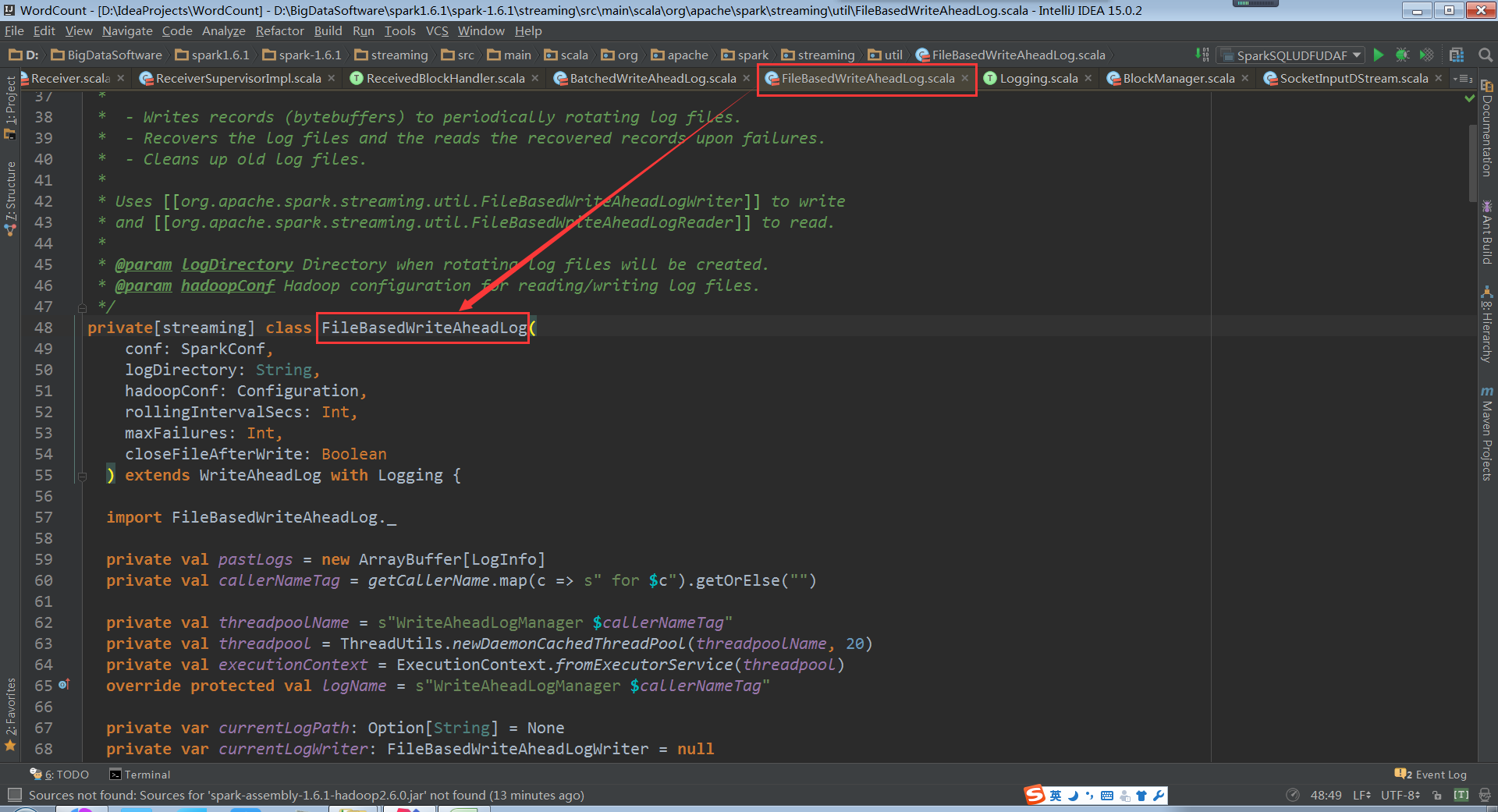
直接将数据写入到HDFS的checkpoint
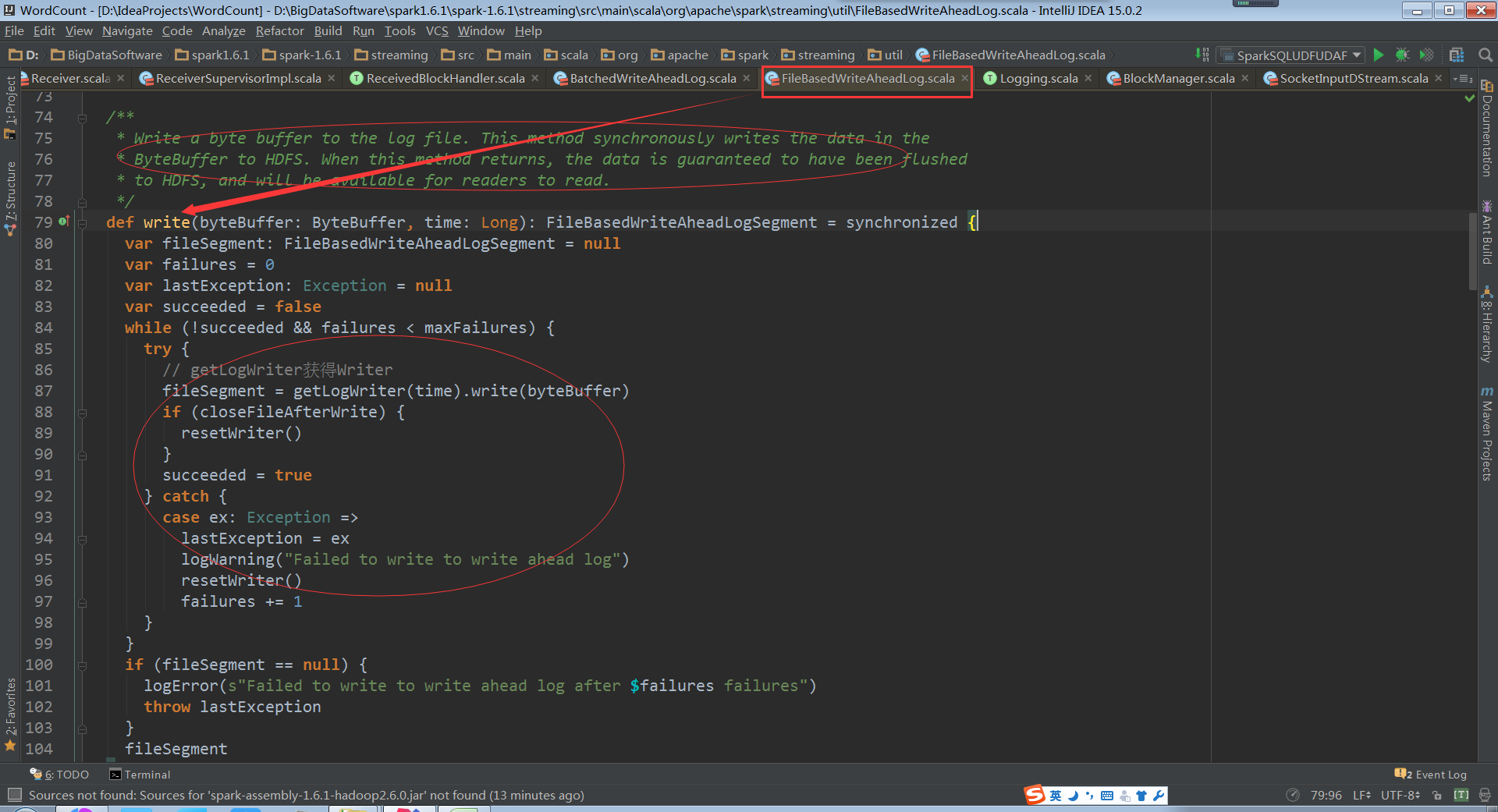
不同时间不同条件下,会写入到不同的文件中,会有很多小文件
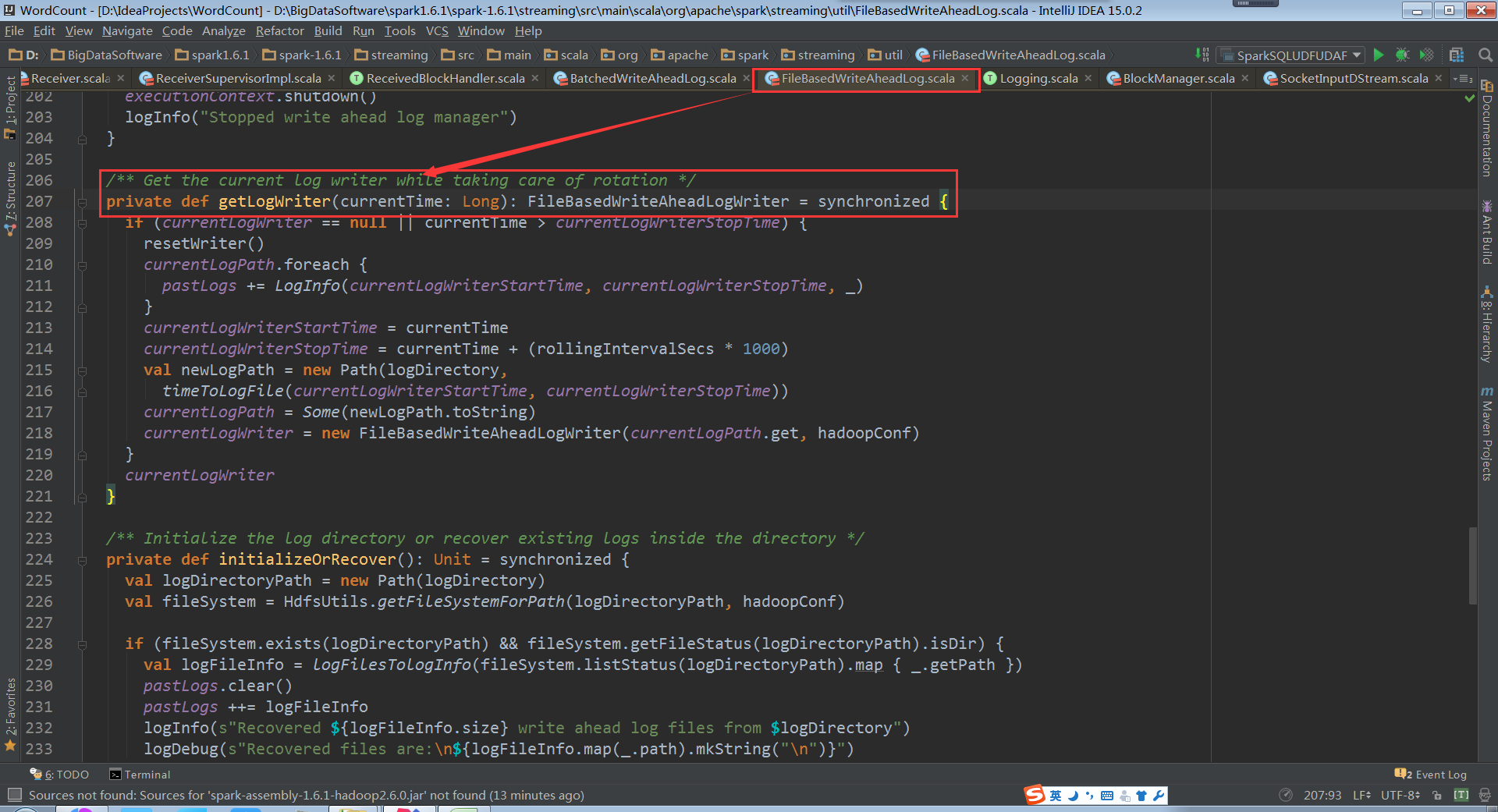
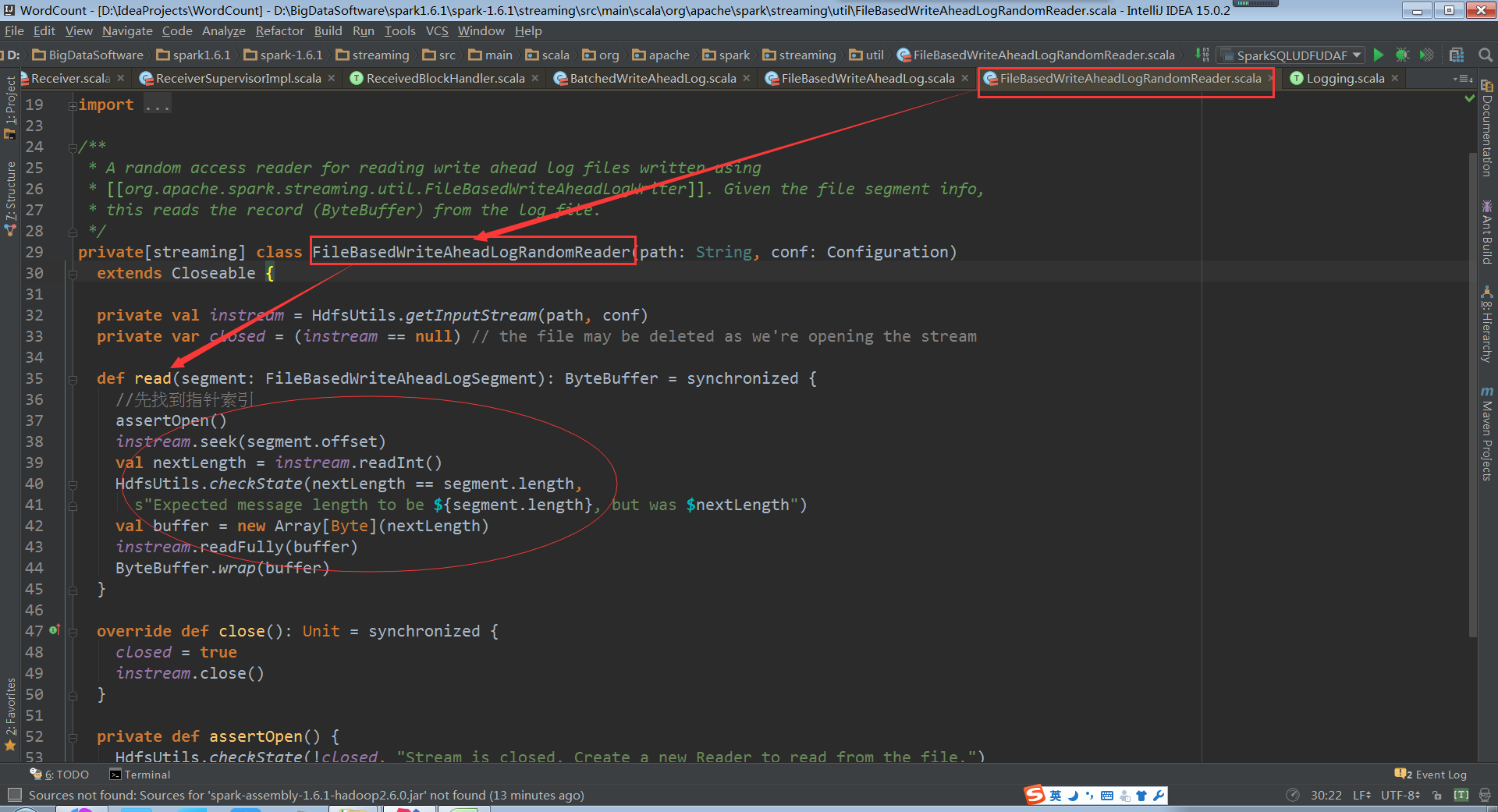
Read部分
不管是WAL还是直接交给blockmanager都是采用副本的方式。还有一种是数据源支持数据存放,典型的就是kafka。Kafka已经成为了数据存储系统,它天然具有容错和数据副本
Kafka有receiver和direct的方式。Receiver的方式其实是交给zookeper来管理matadata的(偏移量offset),如果数据处理失败后,kafka会基于offset重新读取数据。为什么可以重新读取?如果程序崩溃或者数据没处理完是不会给zookeper发ack。Zookeper就认为这个数据没有被消费。实际生产环境下越来越多的使用directAPI的方式,直接去操作kafka并且是自己管理offset。这就可以保证有且只有一次的容错处理。DirectKafkaInputDstream,它会去看最新的offset,并把这个内容放入batch中
获取最新的offset,通过最新的offset减去上一个offset就可以确定读哪些数据,也就是一个batch中的数据
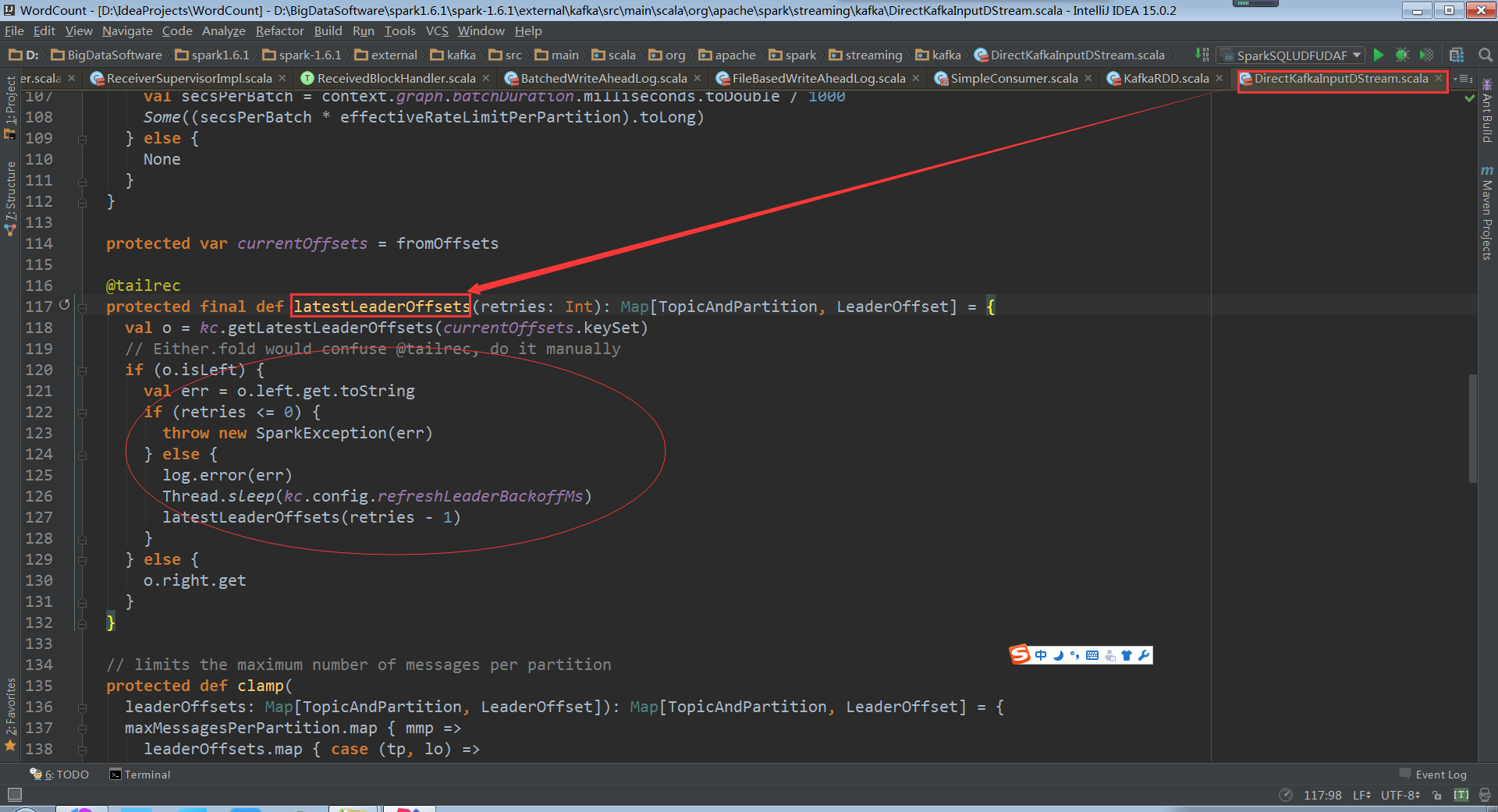
a. 容错的弊端就是消耗性能,占用时间。也不是所有情况都不能容忍数据丢失。有些情况下可以不进行容错来提高性能
b. 假如一次处理1000个block,但是有1个block出错,就需要把1000个block进行重新读取或者恢复,这也有性能问题















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









