







文章目录
hadoop架构组成
hdfs详解
yarn详解
hadoop分布式详解
hadoop配置文件
hadoop架构组成
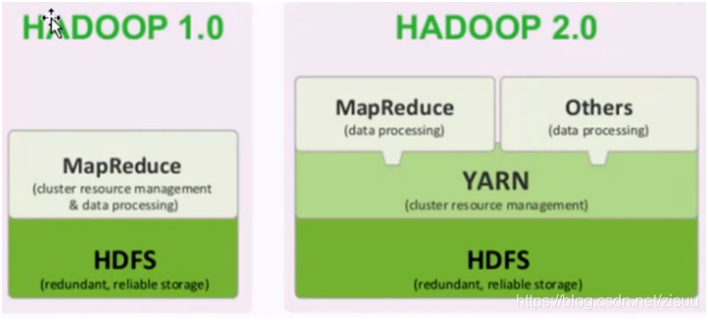
Hadoop是Apache软件基金会旗下的一个分布式系统基础架构。Hadoop的框架最核心的设计就是HDFS、MapReduce和YARN,为海量的数据提供了存储和计算。
-
HDFS主要是Hadoop的存储,用于海量数据的存储;
-
MapReduce主要运用于分布式计算;
-
YARN是Hadoop中的资源管理系统。
hdfs架构
HDFS是一个分布式文件系统,具有高容错的特点,它可以部署在廉价的通用硬件上,提供高吞吐率的数据访问,适合那些需要处理海量数据集的应用程序。
需要注意的是,hdfs适合存储几百MB、GB甚至TB级别的文件,不适合存储小型的文件
架构
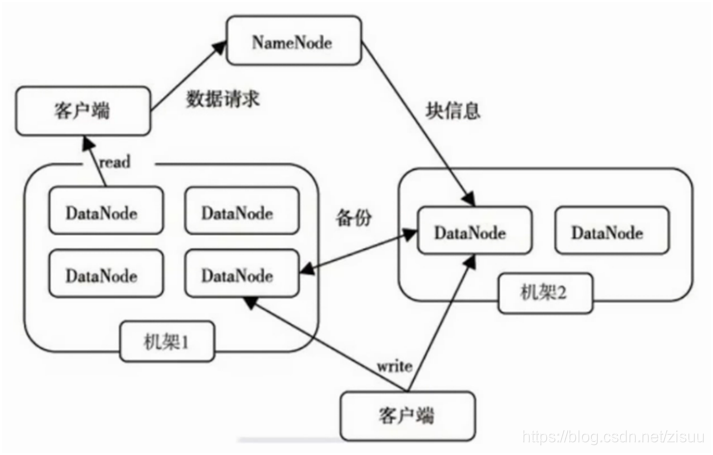
Namenode–保存数据在datanode中的存放地址,处理客户端的请求
Datanode–真正存放数据的地方,以数据块的形式进行存储
数据块:
HDFS也有块的概念,Hadoop2中HDFS块默认大小为128MB(此大小可以根据各自的业务情况进行配置,Hadoop1中HDFS块默认大小为64MB),以Linux上普通文件的形式保存在数据节点的文件系统中,数据块是HDFS的文件存储处理的单元。
数据块的好处:
-
HDFS可以保存比存储节点单一磁盘大的文件
-
简化了存储子系统和存储管理,也消除了分布式管理文件元数据的复杂性
-
方便容错,有利于数据复制
hdfs读流程
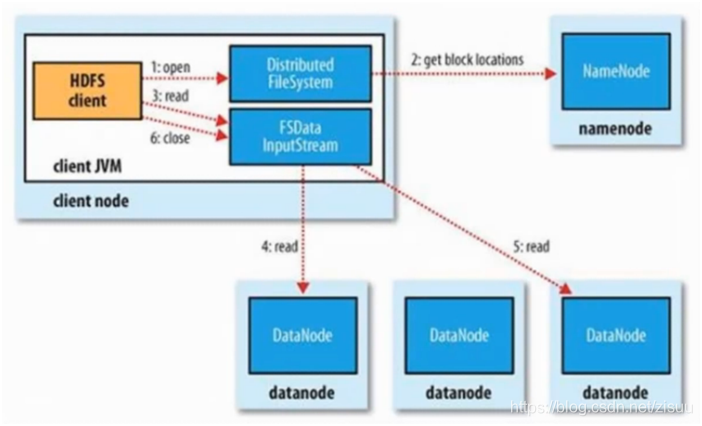
1、客户端client使用open函数打开文件;
2、DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息;
3、对于每一个数据块,元数据节点返回保存数据块的数据节点的地址;
4、DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据;
5、客户端调用FSDataInputStream的read函数开始读取数据;
6、FSDataInputStream连接保存此文件第一个数据块的最近的数据节点;
7、Data从数据节点读到客户端;
8、当此数据块读取完毕时,FSDataInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点;
9、当客户端读取数据完毕时,调用FSDataInputStream的close函数;
10、在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
hdfs写流程
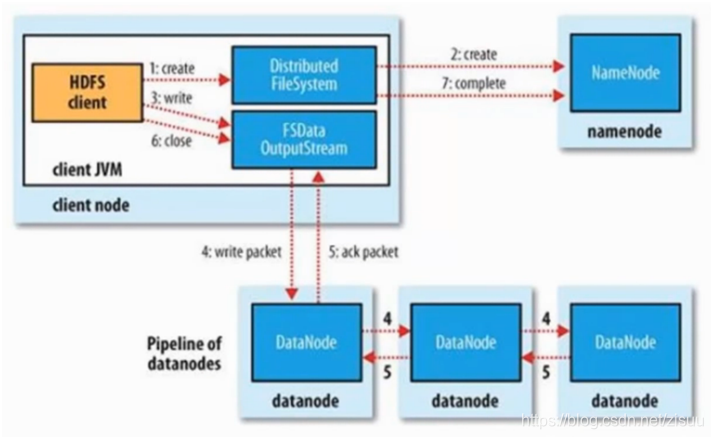
客户端client调用create函数创建文件;
2、DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件;
3、元数据节点首先确定文件是否存在,并且客户端是否有创建文件的权限,然后创建新文件;
4、DistributedFileSystem返回FSDataOutputStream给客户端用于写数据;
5、客户端开始写入数据,FSDataOutputStream将数据分成块,写入data queue;
6、Data queue由DataStreamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块),分配的数据节点放在一个pipeline里;
7、DataStreamer将数据块写入pipeline中的第一个数据节点,第一个数据节点将数据块发送给第二个数据节点,第二个数据节点将数据发送给第三个数据节点;
8、FSDataOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功;
9、如果数据节点在写入的过程中失败,则进行以下几个操作:一是关闭pipeline并将ack queue中的数据块放入data queue的开始;二是当前数据块在已写入的数据节点中被元数据节点赋予新的标示,错误节点重启后察觉其数据块过时而被删除;三是失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点;四是元数据节点被通知此数据块的复制块数不足,从而再创建第三份备份;
10、当客户端结束写入数据,则调用close函数将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功,最后通知元数据节点写入完毕。
Secondary Namenode
其并非字面意思,不是Namenode的接班者其作用如下:
- 辅助Namenode的工作,减轻其工作量
- 定期合并Fsimage(镜像) 和Edits(读写操作),并推送给Namenode
- 在紧急情况下,可恢复Namenode
YARN架构
YARN是一个通用的资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN的基本设计思想:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理,其基本架构如下图所示:
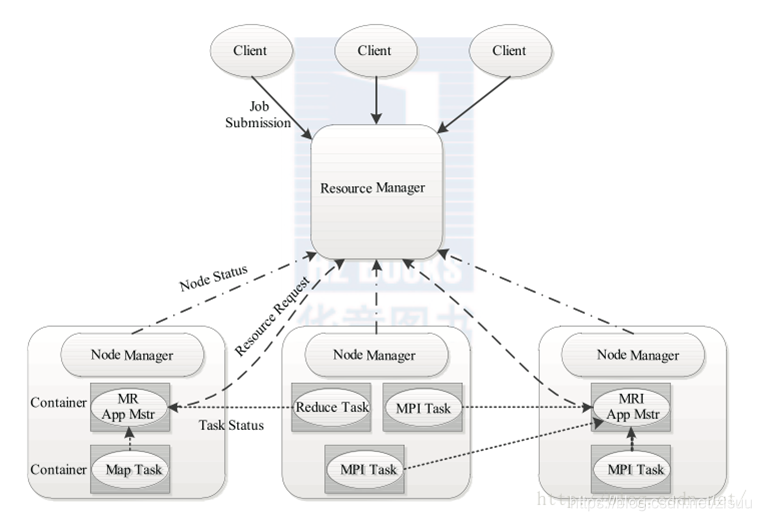
ResourceManager:它是一个全局的资源管理器,负责整个系统的资源管理和分配,主要由调度器和应用程序管理器两个组件构成。
-
调度器:根据容量、队列等限制条件,将系统中的资源分配给各个正在运行的应用程序。调度器仅根据应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。
-
应用程序管理器:负责管理整个系统中所有的应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
ApplicationMaster:用户提交的每个应用程序均包含1个ApplicationMaster,主要功能包括与ResourceManager调度器协商以获取资源、将得到的任务进一步分配给内部的任务、与NodeManager通信以启动/停止任务、监控所有任务运行状态并在任务运行失败时重新为任务申请资源以重启任务等。
NodeManager:它是每个节点上的资源和任务管理器,它不仅定时向ResourceManager汇报本节点上的资源使用情况和各个Container的运行状态,还接收并处理来自ApplicationMaster的Container启动/停止等各种请求。
- Container:它是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当ApplicationMaster向ResourceManager申请资源时,返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
工作流程:
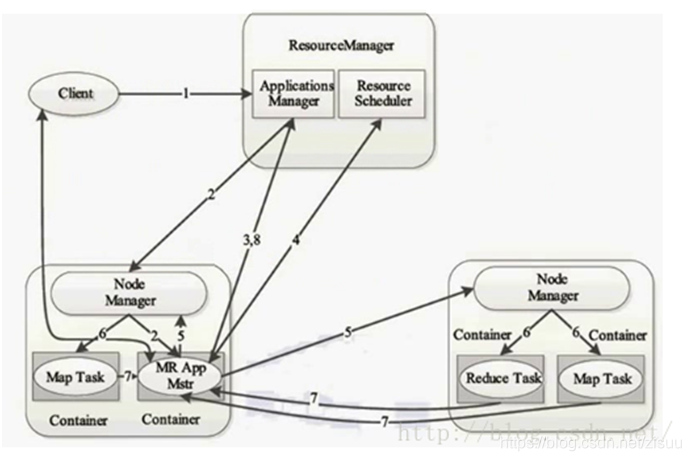
1:用户向YARN中提交应用程序,其中包括用户程序、ApplicationMaster程序、ApplicationMaster启动命令等。
2:ResourceManager为应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
3:ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后ApplicationMaster为各个任务申请资源,并监控它们的运行状态,直到运行结束,即重复步骤4-7。
4:ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
5:一旦ApplicationMaster成功申请到资源,便开始与对应的NodeManager通信,要求它启动任务。
6:NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
7:各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,使ApplicationMaster能够随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
8:应用程序运行完成后,ApplicationMaster通过RPC协议向ResourceManager注销并关闭自己。在这里插入代码片
hadoop分布式
1.单机(非分布式)模式
这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统,一般仅用于本地MR程序的调试
2.伪分布式运行模式
-
这种模式也是在一台单机上运行,但用不同端口模仿分布式运行中的各类结点: (NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode)
-
从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
开启多个进程模拟完全分布式 -
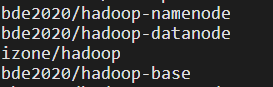
如果用docker进行部署hadoop伪分布式集群环境,docker上有一个专门的伪分布式镜像,如下:(可根据几个镜像写一个docker-compose,进行伪分布式部署)

3.完全分布式模式
真正的分布式,由3个及以上的实体机或者虚拟机组件的机群。
如果要用docker进行部署,基本思路:(只是一个基本思路)
- 在docker中创建centos容器
- 在该容器中创建hadoop
- 配置hadoop
- 将该centos容器制作成镜像,由此创造出三个centos容器,一主二辅
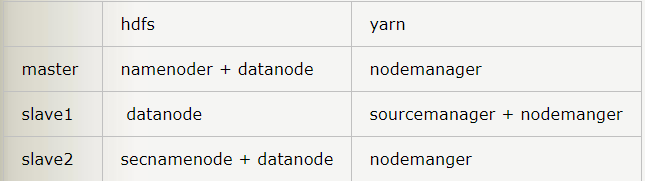
- 规划好哪个容器上有namenode,datanode,resource Manager…如下:
hadoop配置文件
core-site.xml
fs.defaultFS—配置hdfs访问路径
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.100:900</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
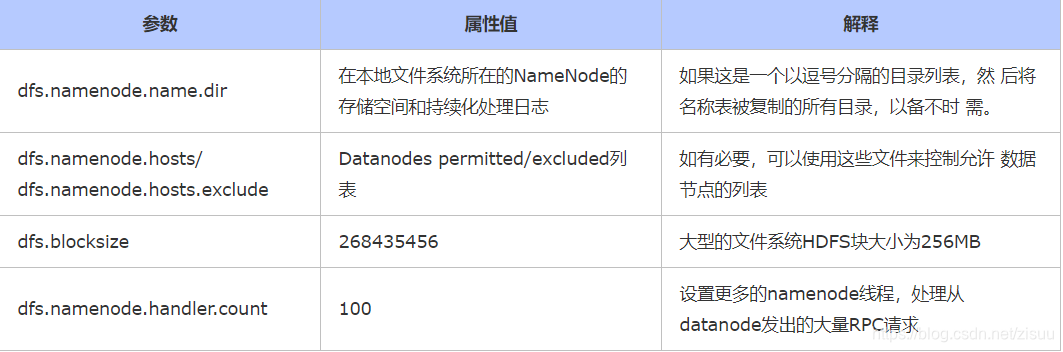
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>分片数量,伪分布式将其配置成1即可</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/namenode</value>
<description>命名空间和事务在本地文件系统永久存储的路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/datanode</value>
<description>DataNode在本地文件系统中存放块的路径</description>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>datanode1, datanode2</value>
<description>datanode1, datanode2分别对应DataNode所在服务器主机名</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>大文件系统HDFS块大小为256M,默认值为64M</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
<description>更多的NameNode服务器线程处理来自DataNodes的RPCS</description>
</property>
</configuration>
yarn-site.xml
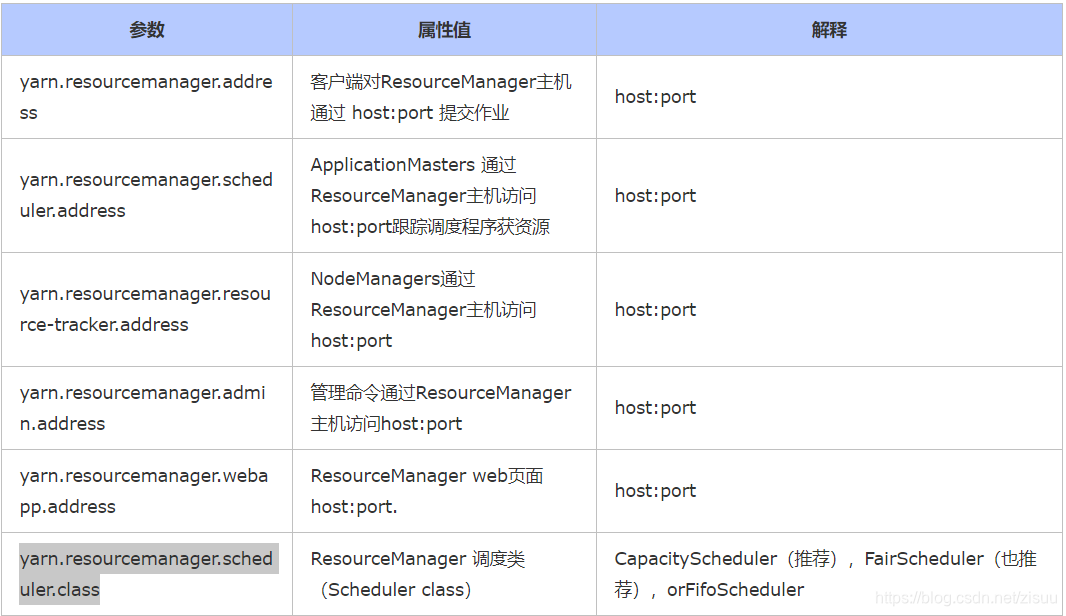
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.100:8081</value>
<description>IP地址192.168.1.100也可替换为主机名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.100:8082</value>
<description>IP地址192.168.1.100也可替换为主机名</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.100:8083</value>
<description>IP地址192.168.1.100也可替换为主机名</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.100:8084</value>
<description>IP地址192.168.1.100也可替换为主机名</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.100:8085</value>
<description>IP地址192.168.1.100也可替换为主机名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>FairScheduler</value>
<description>常用类:CapacityScheduler、FairScheduler、orFifoScheduler</description>
</property>
<property>
<name>yarn.scheduler.minimum</name>
<value>100</value>
<description>单位:MB</description>
</property>
<property>
<name>yarn.scheduler.maximum</name>
<value>256</value>
<description>单位:MB</description>
</property>
<property>
<name>yarn.resourcemanager.nodes.include-path</name>
<value>nodeManager1, nodeManager2</value>
<description>nodeManager1, nodeManager2分别对应服务器主机名</description>
</property>
</configuration>
在yarn-site中配置nodeManager
<configuration>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>256</value>
<description>单位为MB</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>90</value>
<description>百分比</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/hadoop/tmp/nodemanager</value>
<description>列表用逗号分隔</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/usr/local/hadoop/tmp/nodemanager/logs</value>
<description>列表用逗号分隔</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>单位为S</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce-shuffle</value>
<description>Shuffle service 需要加以设置的MapReduce的应用程序服务</description>
</property>
</configuration>
浏览器访问















 5962
5962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









