







在生产环境中使用 Kafka 时,绝不仅仅是 “生产消息 → 消费消息” 这么简单。随着业务复杂度提升,很多隐藏的“坑”也随之暴露:消费失败如何重试?死信队列该怎么设计?系统高压下如何避免雪崩? 本文将围绕 Kafka 的实际使用问题,逐一剖析,并提供应对策略。
一、消费失败后的重试机制设计
问题背景:
Kafka 默认并不提供内建的消息重试机制,如果消费失败,Consumer 不提交 offset,Kafka 会不断尝试重新投递同一条消息,直到消费成功或服务挂掉。这种机制看似简单,其实隐含多个风险:
-
会导致消费阻塞(阻碍后续消息处理)
-
无限重试占用资源,引发雪崩
-
无法精准控制重试间隔与次数
✅ 解决思路
最常见的方式是构建自定义重试机制:
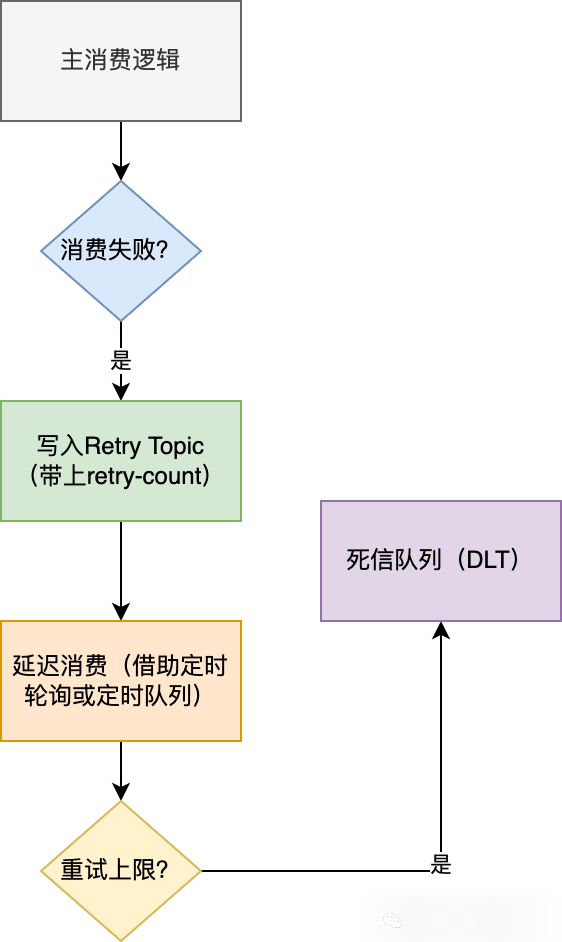
✅ 技术实现方式
创建多个 Topic:
-
main-topic
-
retry-topic-N(带不同延迟)
-
dead-letter-topic
业务代码示意(伪代码):
if (consumeFailed && retryCount < maxRetry) {
// 投递至重试 Topic
sendToRetryTopic(msg, retryCount + 1);
} else {
// 达到最大重试次数,进入死信队列
sendToDLT(msg);
}实现延迟重试:
-
Kafka 本身不支持延迟消息,可借助定时任务、调度服务(如 Quartz)、或使用中间件如Kafka Delay Queue 实现。
二、死信队列(Dead Letter Queue, DLQ)
为什么需要 DLQ?
重试失败的消息若没有归宿,会:
-
导致重复写入 retry topic
-
堵塞主消费流程
-
影响系统稳定性
DLQ 实践建议
-
独立的 Topic(如:xxx-dlt)
-
业务字段要完整保留,便于人工回溯/补偿
-
配合监控告警系统,自动通知相关负责人
三、Kafka 中的反压问题(Backpressure)
问题表现:
-
Consumer 消费速度 < Producer 写入速度
-
Topic 积压明显,Consumer Lag 急剧上升
-
Broker 内存、磁盘压力剧增,甚至触发 OOM 或 GC Storm
✅ 应对策略
1.从消费侧入手:
-
增加 Consumer 实例数
-
优化业务逻辑处理效率(异步 + 批处理)
-
开启并行消费(分区粒度并行)
2.从生产侧限流:
-
通过指标监控 ConsumerLag,动态调整发送速率
-
接入流控中间件,如 Sentinel、Resilience4j
3.Broker 层优化:
-
调整 retention.ms,避免堆积长时间消息
-
提高磁盘吞吐:使用 SSD、RAID 等硬件优化
4.开启指标监控与告警:
-
监控 Lag、TPS、消费延迟等核心指标
-
自动扩容 or 告警触发缓冲措施
四、实战补充:如何写一个支持重试与 DLQ 的消费者
@KafkaListener(topics = "order-topic", groupId = "order-consumer")
public void consume(ConsumerRecord<String, String> record) {
try {
processBusiness(record.value());
// 正常消费逻辑
} catch (Exception ex) {
int retryCount = getRetryCount(record.headers());
if (retryCount < MAX_RETRY) {
sendToRetryTopic(record, retryCount + 1);
} else {
sendToDLQ(record);
}
}
}五、小结:Kafka 实践中不可忽视的 3 个“坑”
| 问题 | 影响 | 推荐解决策略 |
|---|---|---|
| 消费失败重试 | 死循环、消息阻塞 | 自定义 retry + delay topic |
| 死信队列缺失 | 消息丢失、运维难 | 构建 DLQ,带业务字段 |
| 消费者反压 | 系统资源耗尽、Broker 崩溃 | 增加并发 + 限流 + 监控 + 通知 |
六、Kafka + Spring Retry 实现灵活的延迟重试机制
这是一个非常实用的问题,尤其是在微服务系统中处理消息失败与自动重试时,Kafka + Spring Retry 的组合可以大幅提升健壮性与灵活性。下面是详细讲解和实战指南。
6.1 方案简介
Spring for Apache Kafka 从 2.3+ 版本起提供了 @RetryableTopic 注解,内置对延迟重试与死信队列的支持。它允许你用注解方式优雅实现 retry + DLT(Dead Letter Topic)机制,无需手动创建多个重试 topic,也不必手动编排转发逻辑。
6.2 实现步骤(基于 Spring Boot)
6.2.1 添加依赖
<!-- pom.xml -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>6.2.2 配置 Kafka 消费者(application.yml)
spring:
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: demo-consumer-group
auto-offset-reset: earliest
listener:
ack-mode: record6.2.3 编写支持延迟重试的消费者逻辑
@RetryableTopic(
attempts = "3",
backoff = @Backoff(delay = 2000, multiplier = 2.0),
dltTopicSuffix = ".dlt",
autoCreateTopics = "true",
include = { RuntimeException.class }
)
@KafkaListener(topics = "order-topic", groupId = "demo-consumer-group")
public void listen(String message) {
System.out.println("收到消息: " + message);
if (message.contains("fail")) {
throw new RuntimeException("模拟消费失败");
}
}🔍 说明:
-
attempts = "3":最大重试 3 次(首次 + 2 次)
-
delay = 2000:第一次重试延迟 2 秒
-
multiplier = 2.0:指数退避(下次延迟为 4s、8s)
-
.dlt:超过重试次数的消息自动进入 order-topic.dlt
-
autoCreateTopics = true:自动创建重试 topic 和 DLT
6.3 运行效果说明
当收到一条包含 "fail" 的消息:
-
第一次消费失败(立即失败)
-
第 1 次重试:2 秒后尝试
-
第 2 次重试:4 秒后尝试
-
第 3 次重试:8 秒后尝试
-
若仍失败,消息自动进入 order-topic.dlt(可人工处理)
你可以监听死信队列:
@KafkaListener(topics = "order-topic.dlt", groupId = "demo-consumer-group")
public void handleDLT(String dltMessage) {
System.err.println("进入死信队列: " + dltMessage);
}6.4 可扩展参数说明
| 参数 | 说明 |
|---|---|
| backoff.delay | 初始重试间隔(毫秒) |
| backoff.multiplier | 每次重试的间隔增长倍数(指数退避) |
| backoff.maxDelay | 最大重试间隔上限 |
| include/exclude | 哪些异常触发重试 |
| dltStrategy | 死信队列策略(默认:ALWAYS) |
| autoCreateTopics | 是否自动创建 retry + dlt topic |
6.5 实战建议
-
幂等性:避免重复消费造成数据错误,必须保证业务处理幂等。
-
统一处理失败逻辑:可用 AOP 或封装 RetryHandler。
-
配合监控平台:死信 topic 应接入日志、告警系统。
-
DLT 持久化字段:原始消息信息应完整保留,便于人工分析。
6.6 小结
| 特性 | Kafka + Spring Retry |
|---|---|
| 重试机制 | 支持固定延迟 & 指数退避 |
| 开发复杂度 | 极低(只需注解 + 配置) |
| 自动生成 Topic | ✅(无需手动创建 retry/dlt topics) |
| 与业务逻辑解耦 | ✅(重试逻辑不入侵业务代码) |
下一篇我将探讨Kafka 3.x 引入的原生 DLQ 支持,实战与局限。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











