






《二维DSA和三维MRA图像的双视图融合配准用于神经介入》
Dual-view fusion and registration of 2D DSA images and 3D MRA images for neurointerventio
发表于 Computers in Biology and Medicine
CIBM-小区一区 7.7影响因子
摘要解析
摘要
目标: 在神经介入手术中,术前高分辨率影像(MRI, MRA)与术中影像(DSA)的对齐至关重要。目前依赖的2D DSA轮廓图像由于缺乏解剖细节,导致手术时间和辐射暴露时间增加。通过整合MRA数据,可以弥补这些不足,提高手术效率。本研究将问题框定为3D点及其2D投影之间的相对姿态和对应关系,这由于多模态图像中固有的噪声和异常而变得复杂。很少有方法能够完全自动化多模态融合。
方法: 本文介绍了一个多模态图像配准流程,融合了双视图。使用深度学习技术从多模态图像中提取特征以实现自动化。提出的配准方法基于最大边界因子(FMB),通过放宽下限约束和加强上限约束,并使用第二视角挖掘点集中更多的局部一致信息,以生成精确的姿态估计。
主要结果: 与现有的2D/3D点集配准方法相比,该方法采用了不同的问题表述,更有效地搜索旋转和平移空间,提高了配准速度。
意义: 在合成和真实数据上的实验表明,所提出的方法在精度、鲁棒性和时间效率方面表现出色。
简介
神经介入手术需要术前高分辨率影像(MRI, MRA)与术中影像(DSA)的精确对齐,以有效治疗病变。传统上,手术依赖2D DSA轮廓图像进行指导,但由于其解剖细节不足,可能导致手术时间和辐射暴露增加。整合MRA影像的详细信息可以提高手术效率和安全性。
方法
配准流水线: 引入的配准流水线自动对齐多模态图像,利用融合的双视图通过深度学习提取特征。
特征提取: 使用深度学习模型从MRI/MRA和DSA影像中提取相关特征,相比手动或传统方法,自动化并增强了这一过程。
最大边界因子(FMB): 提出的配准方法以FMB为核心,包括:
- 放宽下限约束以适应噪声和异常。
- 加强上限约束以实现更严格的匹配标准。
- 利用第二视角提取局部一致信息,提高姿态估计精度。
结果
该方法在合成和真实数据集上的评估结果表明,与现有2D/3D点集配准方法相比,具有以下优势:
- 精度: 更精确的多模态图像对齐。
- 鲁棒性: 在存在噪声和异常的情况下表现更佳。
- 时间效率: 配准过程更快,减少了整体手术时间。
结论
本研究提出了一种新颖的神经介入手术多模态图像配准方法。通过利用深度学习进行特征提取和创新的基于FMB的配准方法,所提出的流水线在精度、鲁棒性和效率方面表现出色。这些改进可以显著增强神经介入手术的效果和安全性,减少手术时间和患者的辐射暴露。
Introduction分析
计算机辅助医疗干预(CAMI)中的2D/3D图像配准
在计算机辅助医疗干预(CAMI)中,实时跟踪和调整手术器械的空间位置,并同时查看患者病变的解剖特征,外科医生需要查看3D术前图像(如高分辨率磁共振成像HR-MRI、计算机断层扫描CT和磁共振血管成像MRA)以及2D数字减影血管造影(DSA)图像。这种多模态图像的配准对于许多介入程序来说是一个挑战,如介入超声、心脏介入等,尤其是在神经介入程序中,因为大脑血管结构复杂且变化多样。
主要贡献
- FMB方法: 最大边界因子 (Factor of Maximum Bounds, FMB)
- 提出了一种基于最大边界因子的全局搜索方法,能够在数据中混淆的对应关系中挖掘更多局部信息,生成高精度的匹配关系。
- 多模态血管配准的解决方案:
- 首次解决了双视图下的多模态血管配准问题,将FMB与Segment Anything Model (SAM)和3D-Unet结合,创建了一个可以提高性能的端到端框架,无需初始化,提供自然的可视化和解释性。
未来工作方向
-
提升数据泛化能力:
- 深度学习方法需要大量数据进行训练,并且在不同数据集上的泛化能力较差。未来工作可以探索更鲁棒的特征描述符或更有效的对应选择技术,提高跨数据集的配准准确性。
-
优化算法效率:
- RANSAC及其变体在离群点增加时表现脆弱且需要大量迭代。未来可以探索更高效的鲁棒估计器或离群点移除技术,优化6D参数空间搜索。
主流程图分析
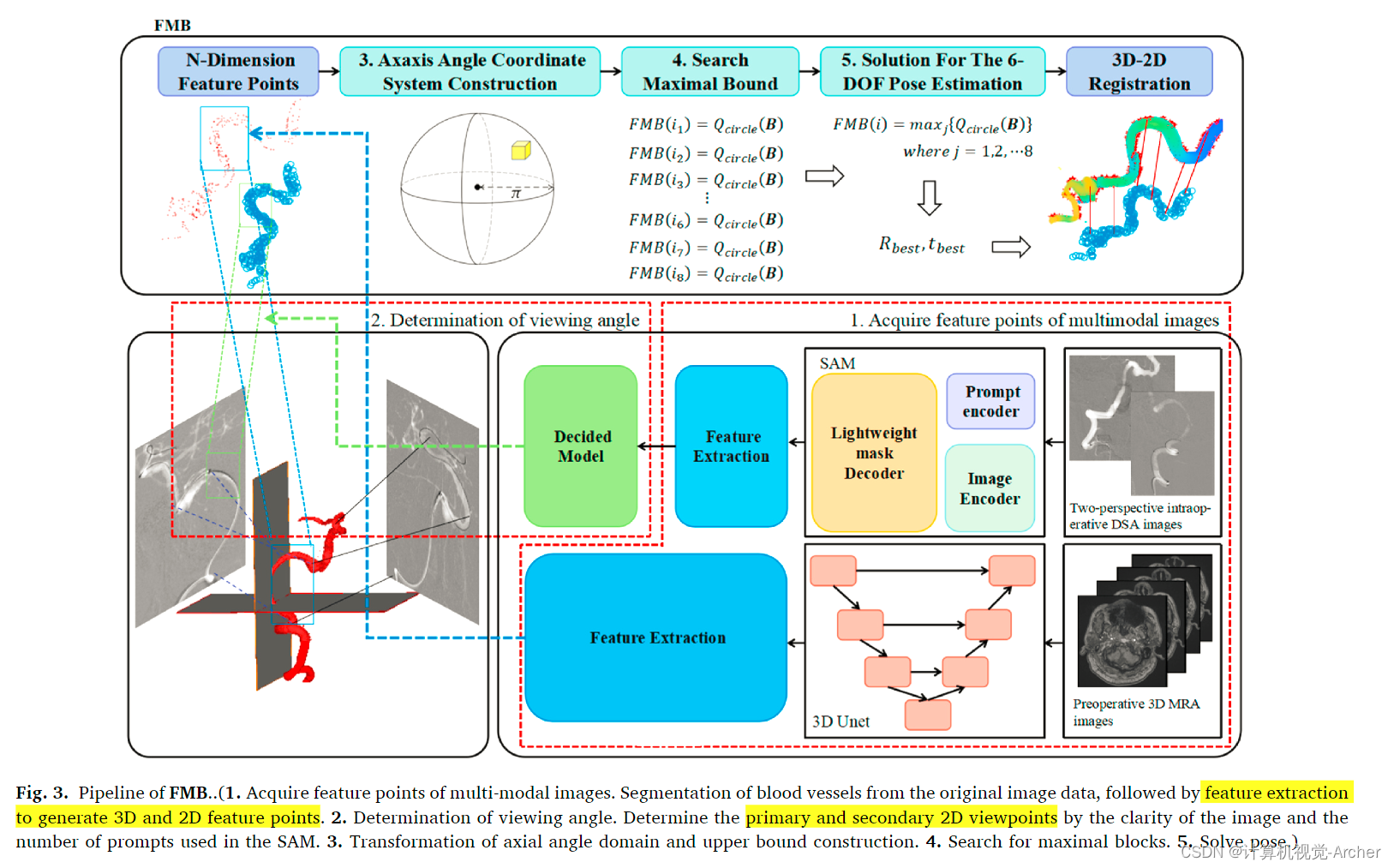
-
FMB流程管道
1. 获取多模态图像的特征点
首先,对原始图像数据进行血管分割,然后进行特征提取,生成3D和2D特征点。这一步的目标是从多模态图像中提取出准确的特征点,以便后续步骤使用。
2. 确定视角
通过图像的清晰度和在SAM中使用的提示数量,确定主要和次要的2D视角。这一步的目的是选择最合适的视角,以确保在进行配准时获取最佳的图像信息。
3. 轴角域转换和上界构建
将特征点转换到轴角域中,并构建其上界。这一步通过松弛下界和增强上界的约束,确保能够挖掘出点集中更多的局部信息,为后续步骤的准确匹配打下基础。
4. 搜索最大块
在轴角域中搜索最大块,通过多视角融合获取更多的局部信息,并进行点集的惩罚和过滤。这一步通过全局搜索方法,在点集中挖掘更多的局部信息,从而提高匹配的准确性。
5. 解算姿态
最终,求解点集的姿态。这一步通过对最大块的优化,得到最终的配准结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











