







函数
函数在计算机语言的使用中贯穿始终,函数的作用是什么呢?它可以把经常使用的代码封装起来,需要 的时候直接调用即可。这样既提高了代码效率 ,又提高了可维护性。在SQL
中也可以使用函数对检索出 来的数据进行函数操作。使用这些函数,可以极大地 提高用户对数据库的管理效率。
从函数定义的角度出发,可以将函数分成内置函数和自定义函数。在
SQL
语言中,同样也包括内置函数 和自定义函数。内置函数是系统内置的通用函数,而自定义函数是根据自己的需要编写的
函数说明
在使用
SQL
语言的时候,不是直接和这门语言打交道,而是通过它使用不同的数据库软件,即
DBMS
。
DBMS
之间的差异性很大,远大于同一个语言不同版本之间的差异。实际上,只有很少的函数是被
DBMS
同时支持的。比如,大多数
DBMS
使用
||
或者
+
来做拼接符,而在
MySQL
中的字符串拼接函数为 concat()。大部分
DBMS
会有自己特定的函数,这就意味着采用
SQL
函数的代码可移植性是很差的,因此 在使用函数的时候需要特别注意。
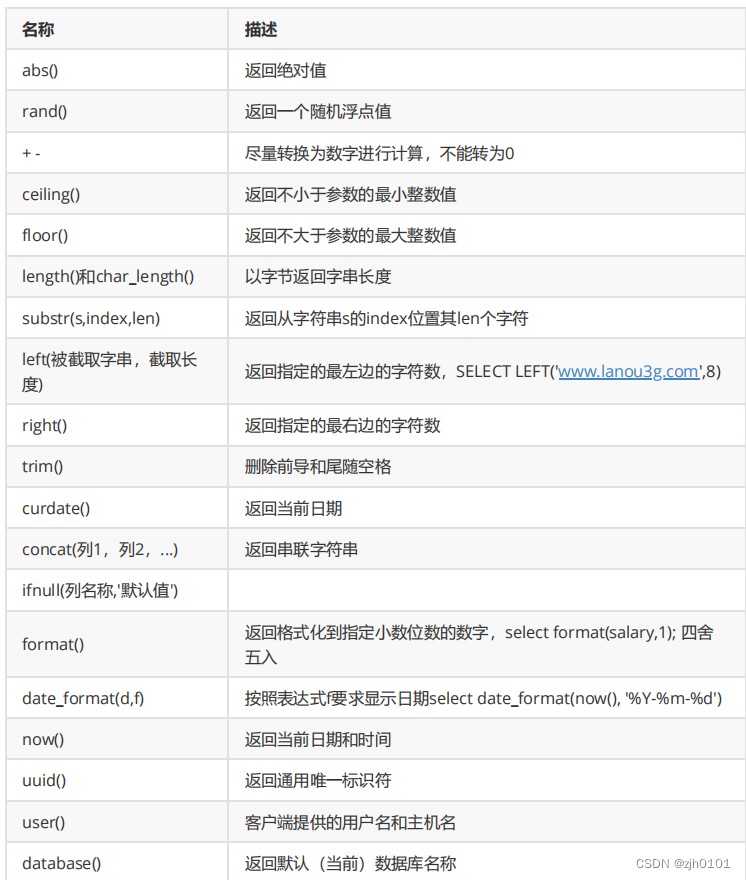
MySQL
提供了丰富的内置函数,这些函数使得数据的维护与管理更加方便,能够更好地提供数据的分析 与统计功能,在一定程度上提高了开发人员进行数据分析与统计的效率。
MySQL
提供的内置函数从实现的功能角度可以分为数值函数、字符串函数、日期和时间函数、流程控制 函数、加密与解密函数、获取MySQL
信息函数、聚合函数等。这里这些丰富的内置函数再分为两类:单 行函数、聚合函数(或分组函数)
两种
SQL
函数

单行函数
操作数据对象
接受参数返回一个结果
只对一行进行变换
每行返回一个结果
可以嵌套
参数可以是一列或一个值
多行函数
多行函数又称聚合函数,对行的分组进行操作,对每个组给出一个结果;如果在查询中没有指定分组, 则将查询结果看作一个组
聚合函数的类型主要有:
avg
平均值、
count
计数、
max
最大值、
min
最小值、
sum
合计
所有聚合函数忽略空值(不会去处理),可以使用
ifnull
或
coalesce
函数来用一个值代替空值,可以使用 distinct使查询到的数据去重。
聚合函数不能互相嵌套使用!
语法
select
函数名称
()
;
或者
select
函数名称
(
列名称,其它参数
) from
表名称
,在
mysql
中
from
子句 不是必须的
CONCAT(A, B) –
连接两个字符串值以创建单个字符串输出。通常用于将两个或多个字段合并为一
个字段。
LENGTH(str)
获取以字节为单位的字符串长度;
CHAR_LENGTH
函数获取字符串的长度,以字符为
单位计算长度
FORMAT(X, D)-
格式化数字
X
到
D
有效数字。
FOMRAT(N,D,locale);
将数字
N
格式化为格式,如
"#,###,###.##"
,舍入到
D
位小数。它返
回一个值作为字符串。其中
N
是要格式化的数字。
D
是要舍入的小数位数。
locale
是一个可选
参数,用于确定千个分隔符和分隔符之间的分组。如果省略
locale
操作符,
MySQL
将默认使
用
en_US
。
SELECT FORMAT(14500.2018, 2);
返回
14,500.20
CURDATE(), CURTIME()-
返回当前日期或时间。
NOW
()
–
将当前日期和时间作为一个值返回。另外
MONTH
(),
DAY
(),
YEAR
(),
WEEK
(),
WEEKDAY
()
–
从日期值中提取给定数据。
HOUR
(),
MINUTE
(),
SECOND
()
–
从时间值中提取给定数据。
DATEDIFF
(
A
,
B
)
–
确定两个日期之间的天数差异,通常用于计算年龄
SELECT DATEDIFF('2008-12-29','2008-12-30') AS DiffDate
ROUND(DATEDIFF(requiredDate, orderDate) / 365, 1)
四舍五入到
1
位小数
SUBTIMES
(
A
,
B
)
–
用于执行时间的减法运算。
SUBTIME('2018-10-31 23:59:59','0:1:1')
返回
2018-10-31 23:58:58
FROM_DAYS
(
INT
)
–
将整数天数转换为日期值。
TO_DAYS(date)
给出一个日期
date
,返回一个天数
(
从
0
年开始的天数
)
SELECT TO_DAYS('1997-10-07'); -> 729669
FROM_DAYS(N)
给出一个天数
N
,返回一个
DATE
值
SELECT FROM_DAYS(729669); -> '1997-10-07'
IFNULL()
函数用于判断第一个表达式是否为
NULL
,如果为
NULL
则返回第二个参数的值,如果不
为
NULL
则返回第一个参数的值
SELECT IFNULL(price,0.0);
聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
聚合函数类型:
AVG()
、
SUM()
、
MAX()
、
MIN()
、
COUNT()
可以对数值型数据使用
AVG
和
SUM
函数
可以对任意数据类型的数据使用
MIN
和
MAX
函数
COUNT(*)
返回表中记录总数,适用于任意数据类型
COUNT(expr)
返回
expr
不为空的记录总数

问题
1
:用
count(*)
,
count(1)
,
count(
列名
)
谁好呢
?
其实对于
MyISAM
引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb
引擎的表用
count(*),count(1)
直接读行数,复杂度是
O(n)
,因为
innodb
真的要去数一
遍。但好
于具体的
count(
列名
)
问题:能不能使用
count(
列名
)
替换
count(*)?
不要使用
count(
列名
)
来替代
count(*)
,
count(*)
是
SQL92
定义的标准统计行数的语法,
跟数
据库无关,跟
NULL
和非
NULL
无关。
说明:
count(*)
会统计值为某个列值为
NULL
的行,而
count(
列名
)
不会统计此列为
NULL
值的行
分组操作
可以使用
GROUP BY
子句将表中的数据分成若干组
明确:
WHERE
一定放在
FROM
后面,如果有
where
则
group by
应该在
where
的后面
在
SELECT
列表中所有未包含在组函数中的列都应该包含在
GROUP BY
子句中
select sex,avg(salary) from tb_users group by sex
正确
select username,max(salary) from tb_users group by sex
语法错误
扩展:特殊用法。使用
WITH ROLLUP
关键字之后,在所有查询出的分组记录之后增加一条记录,该记录
计算查询出的所有记录的总和,即统计记录数量
注意:当使用
ROLLUP
时,不能同时使用
ORDER BY
子句进行结果排序,即
ROLLUP
和
ORDER BY
是互相排斥的
分组过滤
HAVING
行已经被分组
使用了聚合函数
满足
HAVING
子句中条件的分组将被显示
HAVING
不能单独使用,必须要跟
GROUP BY
一起使用
非法使用聚合函数 : 不能在
WHERE
子句中使用聚合函数
WHERE
和
HAVING
的对比
区别
1
:
WHERE
可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条
件;
HAVING
必须要与
GROUP BY
配合使用,可以把分组计算的函数和分组字段作为筛选条件。这
决定了,在需要对数据进行分组统计的时候,
HAVING
可以完成
WHERE
不能完成的任务。这是因
为,在查询语法结构中,
WHERE
在
GROUP BY
之前,所以无法对分组结果进行筛选。
HAVING
在
GROUP BY
之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是
WHERE
无法完成的。另外,
WHERE
排除的记录不再包括在分组中。
区别
2
:如果需要通过连接从关联表中获取需要的数据,
WHERE
是先筛选后连接,而
HAVING
是先
连接后筛选。这一点,就决定了在关联查询中,
WHERE
比
HAVING
更高效。因为
WHERE
可以先
筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较
高。
HAVING
则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数
据集进行筛选,这样占用的资源就比较多,执行效率也较低。
SELECT column
, group_function(
column
)
FROM table
[
WHERE condition
]
[
GROUP BY
group_by_expression]
[
ORDER BY column
];
SELECT
department_id,
AVG
(salary)
FROM
employees
WHERE
department_id >
80
GROUP BY
department_id
WITH ROLLUP
;
SELECT
department_id,
MAX
(salary)
FROM
employees
GROUP BY
department_id
HAVING MAX
(salary)>
10000
SELECT
department_id,
AVG
(salary)
FROM
employees
WHERE
AVG
(salary) >
8000
GROUP BY
department_id
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









