







目录
一、相关基础知识
1.unsigned char与signed char 的区别:
2.哈夫曼树(最优树、最佳搜索树):
①路径长度的概念
1.路径:从一个结点到另一个结点之间的分支序列
2.结点之间的路径长度:从一个结点到另一个结点之间的分支数目
3.树的路径长度(用PL表示):从树的根到每一个结点的路径长度之和 → 深度之和
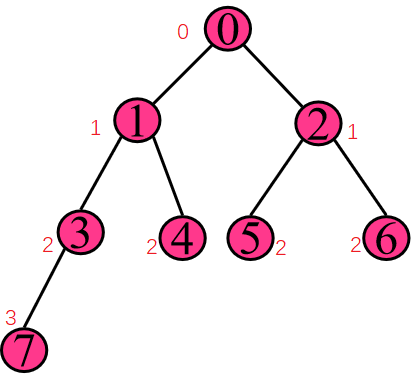
PL = 0+1+1+2+2+2+2+3=13

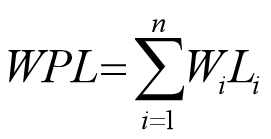
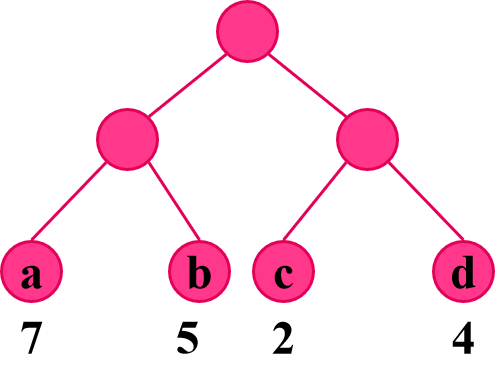
WPL=7*2+5*2+2*2+4*2=36
②构建一颗Huffman树
以数据{5,6,7,8,15}为例

注意观察特征:原数据5\6\7\8\15均只会出现在叶子结点(自下而上构建新的节点)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











